
Release notes for the Genode OS Framework 15.02
Genode's roadmap for this year puts a strong emphasis on the consolidation and cultivation of the existing feature set. With the first release of the year, version 15.02 pays tribute to this mission by stepping up to extensive and systematic automated testing. As a precondition for scaling up Genode's test infrastructure, the release features a highly modular tool kit for exercising system scenarios on a growing zoo of test machines. Section Modular tool kit for automated testing explains the new tools in detail. In the spirit of improving the existing feature set, Genode 15.02 vastly improves the performance and stability of our version of VirtualBox running on the NOVA microhypervisor, solves long-standing shortcomings of memory management on machines with a lot of RAM, addresses NOVA-related scalability limitations, stabilizes our Rump-kernel-based file-system server, and refines the configuration interface of the Intel wireless driver.
As the most significant new feature, the new version introduces virtualization support for ARM to our custom base-hw kernel. Section Virtualization on ARM outlines the design and implementation of this feature, which was greatly inspired by NOVA's virtualization architecture and has been developed over the time span of more than a year.
With respect to platform support, we are happy to accommodate the upcoming USB-Armory board, which is a computer in the form factor of a USB stick especially geared towards security applications. Section Support for the USB-Armory board covers the background and the current state of this line of work.
Virtualization on ARM
The ARMv7 architecture of recent processors like Cortex-A7, Cortex-A15, or Cortex-A17 CPUs support hardware extensions to facilitate virtualization of guest operating systems. With the current release, we enable the use of these virtualization extensions in our custom base-hw kernel when running on the Cortex-A15-based Arndale board.
While integrating ARM's virtualization extension, we aimed to strictly follow microkernel-construction principles. The primary design is inspired by the NOVA OS Virtualization Architecture. It is based on a microhypervisor that provides essential microkernel mechanisms along with basic primitives to switch between virtual machines (VMs). On top of the microhypervisor, classical OS services are implemented as ordinary, unprivileged user-level components. Those services can be used by other applications. Services may be shared between applications or instantiated separately, according to security and safety needs. Correspondingly, following the NOVA principles, each VM has its own associated virtual-machine monitor (VMM) that runs as an unprivileged user-level component. VMM implementations can range from simple ones that just emulate primary device requirements to highly complex monitors including sophisticated device models, like VirtualBox. The NOVA approach allows to decouple the TCB complexity of one VM with respect to another, as well as with respect to all components not related to virtualization at all.
Along those lines, we extended the base-hw kernel/core conglomerate with API extensions that enable user-level VMM components to create and control virtual machines.
Design
The ARM virtualization extensions are based on the so-called security extensions, commonly known as TrustZone. The ARM designers did not follow the Intel approach to split the CPU into a "root" and a "guest" world while having all prior existing CPU modes available in both worlds. Instead, ARM added a new privilege level to the non-secure side of TrustZone that sits underneath the ordinary kernel and userland privilege levels. It is subjected to a hypervisor-like kernel. All instructions used to prepare a VM's environment have to be executed in this so called "hyp" mode. In hyp mode, some instructions differ from their regular behaviour on the kernel-privilege level. For this reason, prior-existing kernel code cannot simply be reused in hyp mode without modifications.
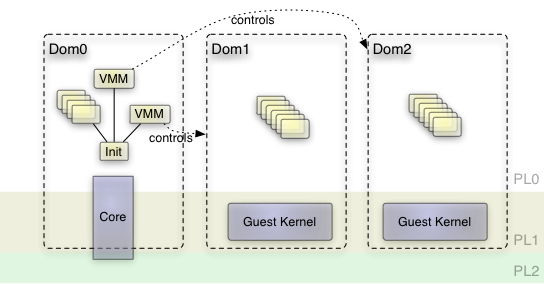
The base-hw kernel is meant to execute Genode's core component on bare hardware. Core, which is an ordinary user-level component, is linked together with a slim kernel library that is executed in privileged kernel mode. To enable ARM hardware virtualization, we pushed this approach even further by executing core in three different privilege levels. Thereby, core shares the same view on hardware resources and virtual memory across all levels. A code path is executed on a higher privilege level only if the code would fail to execute on a lower privilege level. Following this approach, we were able to keep most of the existing kernel code with no modifications.
|
|
Genode's ARM kernel (core) runs across all privilege levels
|
The hypervisor part of core is solely responsible to switch between VMs and the host system. Therefore, it needs to load/store additional CPU state that normally remains untouched during context switches of ordinary tasks. It also needs to configure the VM's guest-physical to host-physical memory translations. Moreover, the virtualization extensions of the ARMv7 architecture are not related to the CPU cores only. The interrupt controller and the CPU-local timers are also virtualization-aware. Therefore, the hypervisor has to load/store state specific to those devices, too. Nevertheless, the hypervisor merely reloads those devices. It does not interpret their state.
In contrast to the low-complexity hypervisor, a user-level VMM can be complex without putting the system's security at risk. It contains potentially complex device-emulation code and assigns hardware resources such as memory and interrupts to the VM. The VMM is an ordinary user-level component running unprivileged. Of course, as a plain user-level component, it is not able to directly access hardware resources. Hence an interface between VMMs and the kernel is needed to share the state of a virtual machine. In the past, we faced a similar problem when building a VMM for our former TrustZone experiments. It was natural to build upon the available solution and to extend it where necessary. Core provides a so-called VM service. Each VM corresponds to a session of this service. The session provides the following extended interface:
- CPU state
-
The CPU-state function returns a dataspace containing the virtual machine's state. The state is initialized by the VMM before bootstrapping the VM, gets updated by the hypervisor whenever it switches away from the VM, and can be used by the VMM to interpret the behavior of the guest OS. Moreover, the CPU state can be updated after the virtual machine monitor emulated instructions for the VM.
- Exception handler
-
The second function is used to register a signal handler that gets informed whenever the VM produces a virtualization fault.
- Run
-
The run function starts or resumes the execution of the VM.
- Pause
-
The pause function removes the VM from the kernel's scheduler.
- Attach
-
This function attaches a given RAM dataspace to a designated area of the guest-physical address space.
- Detach
-
The detach function invalidates a designated area of the guest-physical address space.
- Attach_pic
-
Tells the hypervisor to attach the CPU's virtual interface of the virtualization-aware interrupt controller to a designated area of the guest-physical address space.
Implementation
By strictly following the micro-kernel construction principles when integrating the hypervisor into the base-hw kernel, we reached a minimally invasive solution. In doing so, we took the time to separate TrustZone-specific code that was formerly an inherent part of the kernel on ARMv7 platforms. Now, TrustZone- and virtualization-specific aspects are incorporated into the kernel only if actually used. The change in complexity of the whole core component expressed in lines of code is shown in the table below. As can be seen, the additional code in the root of the trusted computing base when using virtualization is about 700-800 LOC.
| Platform | with TrustZone, no VT | TrustZone/VT optional |
|---|---|---|
| hw_arndale | 17970 LOC | 18730 LOC |
| hw_imx53_qsb | 17900 LOC | 17760 LOC |
| hw_imx53_qsb_tz | 18260 LOC | 18320 LOC |
| hw_rpi | 17500 LOC | 17430 LOC |
| hw_panda | 18040 LOC | 17880 LOC |
| hw_odroid_xu | 17980 LOC | 18050 LOC |
Besides the VM world switch, we enabled support for the so-called "large physical address extension" (LPAE), which is obligatory when using virtualization. It allows for addressing a 40-bit instead of only 32-bit physical address space. Moreover, to execute in hypervisor mode, the bootstrap code of the kernel had to be set up properly. Hence, when booting on the Arndale board, the kernel now prepares the non-secure TrustZone world first, and finally leaves the secure world forever.
To test and showcase the ARM virtualization features integrated in base-hw, we implemented a minimal, exemplary VMM. It can be found in repos/os/src/server/vmm. The VMM emulates a simplified variant of ARM's Versatile Express Cortex-A15 development platform. Currently, it only comprises support for the CPU, the timer, the interrupt controller, and a UART device. It is written in 1100 lines of C++ in addition to the base Genode libraries. The VMM is able to boot a vanilla Linux kernel compiled with a slightly modified standard configuration (no-SMP), and a device tree description stripped down to the devices provided by the VMM. This release includes an automated run test that executes the Linux kernel on top of the VMM on Genode. It can be started via:
make run/vmm
|
|
Three Linux serial consoles running in parallel on top of Genode
|
Modular tool kit for automated testing
In Genode version 13.05, we already introduced comprehensive support for the automated testing of Genode scenarios. Since then, Genode Labs has significantly widened the scope of its internal test infrastructure, both in terms of the coverage of the test scenarios as well as the variety of the used hardware platforms.
The centerpiece of our test infrastructure is the so-called run tool. Steered by a script (run script), it performs all the steps necessary to test drive a Genode system scenario. Those steps are:
-
Building the components of a scenario
-
Configuration of the init component
-
Assembly of the boot directory
-
Creation of the boot image
-
Powering-on the test machine
-
Loading of the boot image
-
Capturing the LOG output
-
Validation of the scenario behavior
-
Powering-off the test machine
Each of those steps depends on various parameters such as the used kernel, the hardware platform used to run the scenario, the way the test hardware is connected to the test infrastructure (e.g., UART, AMT, JTAG, network), the way the test hardware is powered or reseted, or the way of how the scenario is loaded into the test hardware. Naturally, to accommodate the growing variety of combinations of those parameters, the complexity of the run tool increased over time. This growth of complexity prompted us to eventually turn the run tool into a highly modular and extensible tool kit.
Originally, the run tool consisted of built-in rules that could be extended and tweaked by a kernel-specific supplement called run environment. The execution of a run script used to depend on the policies built into the run tool, the used run environment, and optional configuration parameters (run opts).
The new run tool kit replaces most of the formerly built-in policies by the ability to select and configure different modules for the various steps. The selection and configuration of the modules is expressed in the run-tool configuration. There exist the following types of modules:
- boot-dir modules
-
These modules contain the functionality to populate the boot directory and are specific to each kernel. It is mandatory to always include the module corresponding to the used kernel.
(the available modules are: linux, hw, okl4, fiasco, pistachio, nova, codezero, foc)
- image modules
-
These modules are used to wrap up all components used by the run script in a specific format and thereby prepare them for execution. Depending on the used kernel, different formats can be used. With these modules, the creation of ISO and disk images is also handled.
(the available modules are: uboot, disk, iso)
- load modules
-
These modules handle the way the components are transfered to the target system. Depending on the used kernel there are various options to pass on the components. For example, loading from TFTP or via JTAG is handled by the modules of this category.
(the available modules are: tftp, jtag, fastboot)
- log modules
-
These modules handle how the output of a currently executed run script is captured.
(the available modules are: qemu, linux, serial, amt)
- power_on modules
-
These modules are used for bringing the target system into a defined state, e.g., by starting or rebooting the system.
(the available modules are: qemu, linux, softreset, powerplug, amt)
- power_off modules
-
These modules are used for turning the target system off after the execution of a run script.
(the available modules are: powerplug)
When executing a run script, only one module of each category must be used.
Each module has the form of a script snippet located under the tool/run/<step>/ directory where <step> is a subdirectory named after the module type. Further instructions about the use of each module (e.g., additional configuration arguments) can be found in the form of comments inside the respective script snippets. Thanks to this modular structure, the extension of the tool kit comes down to adding a file at the corresponding module-type subdirectory. This way, custom work flows (such as tunneling JTAG over SSH) can be accommodated fairly easily.
Usage examples
To execute a run script, a combination of modules may be used. The combination is controlled via the RUN_OPT variable used by the build framework. Here are a few common exemplary combinations:
Executing NOVA in Qemu:
RUN_OPT = --include boot_dir/nova \
--include power_on/qemu --include log/qemu --include image/iso
Executing NOVA on a real x86 machine using AMT for resetting the target system and for capturing the serial output while loading the files via TFTP:
RUN_OPT = --include boot_dir/nova \
--include power_on/amt --power-on-amt-host 10.23.42.13 \
--power-on-amt-password 'foo!' \
--include load/tftp --load-tftp-base-dir /var/lib/tftpboot \
--load-tftp-offset-dir /x86 \
--include log/amt --log-amt-host 10.23.42.13 \
--log-amt-password 'foo!'
Executing Fiasco.OC on a real x86 machine using AMT for resetting, USB serial for output while loading the files via TFTP:
RUN_OPT = --include boot_dir/foc \
--include power_on/amt --amt-host 10.23.42.13 --amt-password 'foo!' \
--include load/tftp --tftp-base-dir /var/lib/tftpboot \
--tftp-offset-dir /x86 \
--include log/serial --log-serial-cmd 'picocom -b 115200 /dev/ttyUSB0'
Executing base-hw on a Raspberry Pi using powerplug to reset the hardware, JTAG to load the image and USB serial to capture the output:
RUN_OPT = --include boot_dir/hw \
--include power_on/powerplug --power-on-powerplug-ip 10.23.42.5 \
--power-on-powerplug-user admin \
--power-on-powerplug-password secret \
--power-on-powerplug-port 1
--include power_off/powerplug --power-off-powerplug-ip 10.23.42.5 \
--power-off-powerplug-user admin \
--power-off-powerplug-password secret \
--power-off-powerplug-port 1
--include load/jtag \
--load-jtag-debugger /usr/share/openocd/scripts/interface/flyswatter2.cfg \
--load-jtag-board /usr/share/openocd/scripts/interface/raspberrypi.cfg \
--include log/serial --log-serial-cmd 'picocom -b 115200 /dev/ttyUSB0'
After the run script was executed successfully, the run tool will print the string 'Run script execution successful.". This message can be used to check for the successful completion of the run script when doing automated testing.
Meaningful default behaviour
To maintain the ease of use of creating and using a build directory, the create_builddir tool equips a freshly created build directory with a meaningful default configuration that depends on the selected platform. For example, if creating a build directory for the Linux base platform, RUN_OPT is initially defined as
RUN_OPT = --include boot_dir/linux \
--include power_on/linux --include log/linux
Low-level OS infrastructure
Improved management of physical memory
On machines with a lot of memory, there exist constraints with regard to the physical address ranges of memory:
-
On platforms with a non-uniform memory architecture, subsystems should preferably use memory that is local to the CPU cores the subsystem is using. Otherwise the performance is impeded by costly memory accesses to the memory of remote computing nodes.
-
Unless an IOMMU is used, device drivers program physical addresses into device registers to perform DMA operations. Legacy devices such as USB UHCI controllers expect a 32-bit address. Consequently, the memory used as DMA buffers for those devices must not be allocated above 4 GiB.
-
When using an IOMMU on NOVA, Genode represents the address space accessible by devices (by the means of DMA) using a so-called device PD (https://genode.org/documentation/release-notes/13.02#DMA_protection_via_IOMMU). DMA transactions originating from PCI devices are subjected to the virtual address space of the device PD. All DMA buffers are identity-mapped with their physical addresses within the device PD. On 32-bit systems with more than 3 GiB of memory, this creates a problem. Because the device PD is a regular user-level component, the upper 1 GiB of its virtual address space is preserved for the kernel. Since no user-level memory objects can be attached to this area, the physical address range to be used for DMA buffers is limited to the lower 3 GiB.
Up to now, Genode components had no way to influence the allocation of memory with respect to physical address ranges. To solve the problems outlined above, we extended core's RAM services to take allocation constraints as session arguments when a RAM session is created. All dataspaces created from such a session are subjected to the specified constraints. In particular, this change enables the AHCI/PCI driver to allocate DMA buffers at suitable physical address ranges.
This innocent looking feature to constrain RAM allocations raises a problem though: If any component is able to constrain RAM allocations in arbitrary ways, it would become able to scan the physical address space for allocated memory by successively opening RAM sessions with the constraints set to an individual page and observe whether an allocation succeeds or not. Two conspiring components could use this information to construct a covert storage channel.
To prevent such an abuse, the init component filters out allocations constrains from RAM-session requests unless explicitly permitted. The permission is granted by supplementing the RAM resource assignment of a component with a new constrain_phys attribute. For example:
<resource name="RAM" quantum="3M" constrain_phys="yes"/>
Init component
Most of Genode's example scenarios in the form of run scripts support different platforms. However, as the platform details vary, the run scripts have to tweak the configuration of the init component according to the features of the platform. For example, when declaring an explicit route to a framebuffer driver named "fb_drv", the run script won't work on Linux because on this platform, the framebuffer driver is called "fb_sdl". Another example is the role of the USB driver. Depending on the platform, the USB driver is an input driver, a block driver, a networking driver, or a combination of those. Consequently, run scripts with support for a great variety of platforms tend to become convoluted with platform-specific conditionals.
To counter this problem, we enhanced init to support aliases for component names. By defining the following aliases in the init configuration
<alias name="nic_drv" child="usb_drv"/> <alias name="input_drv" child="usb_drv"/> <alias name="block_drv" child="usb_drv"/>
the USB driver becomes reachable for session requests routed to either "usb_drv", "nic_drv", "input_drv", and "block_drv". Consequently, the routing configuration of components that use either of those drivers does no longer depend on any platform-intrinsic knowledge.
RTC session interface
Until now, the RTC session interface used an integer to return the current time. Although this is preferable when performing time-related calculations, a structured representation is more convenient to use, i.e., if the whole purpose is showing the current time. This interface change is only visible to components that use the RTC session directly.
Since the current OS API of Genode lacks time-related functions, most users end up using the libc, which already converts the structured time stamp internally, or provide their own time related functions.
Update of rump-kernel-based file systems
We updated the rump-kernel support to a newer rump-kernel version (as of mid of January 2015). This way, Genode is able to benefit from upstream stability improvements related to the memory management. Furthermore, we revised the Genode backend to allow the rump_fs server to cope well with a large amount of memory assigned to it. The latter is useful to utilize the block cache of the NetBSD kernel.
Libraries and applications
As a stepping stone in the forthcoming community effort to bring the Nix package manager to Genode, ports of libbz2 and sqlite have been added to the repos/libports/ repository.
Runtime environments
VirtualBox on NOVA
Whereas our previous efforts to run VirtualBox on Genode/NOVA were mostly concerned with enabling principal functionality and with the addition of features, we took the release cycle of Genode 15.02 as a chance to focus on performance and stability improvements.
- Performance
Our goal with VirtualBox on NOVA is to achieve a user experience comparable to running VirtualBox on Linux. Our initial port of VirtualBox used to cut a lot of corners with regards to performance and timing accuracy because we had to concentrate on more fundamental issues of the porting work first. Now, with the feature set settled, it was time to revisit and solidify our interim solutions.
The first category of performance improvements is the handling of timing, and virtual guest time in particular. In our original version, we could observe a substantial drift of the guest time compared to the host time. The drift is not merely inconvenient but may even irritate the guest OS because it violates its assumptions about the behaviour of certain virtual devices. The drift was caused by basing the timing on a simple jiffies counter that was incremented by a thread after sleeping for a fixed period. Even though the thread almost never executes, there is still a chance that it gets preempted by the kernel and resumed only after the time slices of concurrently running threads have elapsed. This can take tens of milliseconds. During this time, the jiffies counter remains unchanged. We could significantly reduce the drift by basing the timing on absolute time values requested from the timer driver. Depending on the used guest OS, however, there is still a residual inaccuracy left, which is subject to ongoing investigations.
The second type of improvements is related to the handling of virtual interrupts. In its original habitat, VirtualBox relies on so-called external-interrupt virtualization events. If a host interrupt occurs while the virtual machine is active, the virtualization event is forwarded by the VirtualBox hypervisor to the virtual machine monitor (VMM). On NOVA, however, the kernel does not propagate this condition to the user-level VMM because the occurrence of host interrupts should be of no matter to the VMM. In the event of a host interrupt, NOVA takes a normal scheduling decision (eventually activating the user-level device driver the interrupt belongs to) and leaves the virtual CPU (vCPU) in a runnable state - to be rescheduled later. Once the interrupt is handled, the vCPU gets resumed. The VMM remains out of the loop. Because the update of the VirtualBox device models ultimately relies on the delivery of external-interrupt virtualization events, the lack of this kind of event introduced huge delays with respect to the update of device models and the injection of virtual interrupts. We solved this problem by exploiting a VirtualBox-internal mechanism called POKE. By setting the so-called POKE flag, an I/O thread is able to express its wish to force the virtual machine into the VMM. We only needed to find the right spots to set the POKE flag.
Another performance-related optimization is the caching of RTC time information inside VirtualBox. The original version of the gettimeofday function used by VirtualBox contacted the RTC server for obtaining the wall-clock time on each call. After the update to VirtualBox 4.3, the rate of those calls increased significantly. To reduce the costs of these calls, our new version of gettimeofday combines infrequent calls to the RTC driver with a component-local time source based on the jiffies mechanism mentioned above.
With these optimizations in place, simple benchmarks like measuring the boot time of Window 7 or the time of compiling Genode within a Debian VM suggest that our version of VirtualBox has reached a performance that is roughly on par with the Linux version.
- Stability
Since the upgrade to VirtualBox 4.3.16 in release 14.11, we fixed several regression issues caused by the upgrade. Beside that, we completed the support to route serial output of guests to Genode, lifted the restriction to use just one fixed VESA mode, and enabled support for 32-bit Windows 8 guests on 64-bit Genode/NOVA. The 64-bit host restriction stems from the fact that Windows 8 requires support for the non-executable bit (NX) feature of page tables. The 32-bit version of the NOVA kernel does not leverage the physical address extension (PAE) feature, which is a pre-requisite for using NX on 32-bit.
In the course of the adaptation, our port of VirtualBox now evaluates the PAE and HardwareVirtExUX XML tags of .vbox files:
<VirtualBox xmlns=...>
<Machine uuid=...>
<Hardware ..>
<CPU ...>
<HardwareVirtExUX enabled="true"/>
<PAE enabled="true"/>
...
The PAE tag specifies whether to report PAE capabilities to the guest or not. The HardwareVirtExUx tag is used by our port to decide whether to stay for non-paged x86 modes in Virtualbox's recompiler (REM) or not. Until now, we used REM to emulate execution when the guest was running in real mode and protected mode with paging disabled. However, newer Intel machines support the unrestricted guest feature, which makes the usage of REM in non-paged modes not strictly necessary anymore. Setting the HardwareVirtExUx tag to false accommodates older machines with no support for the unrestricted-guest feature.
Device drivers
iPXE-based network drivers
We enabled and tested the driver with Intel I218-LM and I218-V PCI devices.
Intel wireless stack
In this release, several small issues regarding the wireless stack are fixed. From now on, the driver only probes devices on the PCI bus that correspond to the PCI_CLASS_NETWORK_OTHER device class. Prior to that, the driver probed all devices attached to the bus resulting in problems with other devices, e.g. the GPU, when accessing their extended PCI config space. Since the driver uses cooperative scheduling internally, it must never block or, in case it blocks, must schedule another task. Various sleep functions lacked this scheduling call and are now fixed. Furthermore, a bug in the timer implementation has been corrected, which caused the scheduling of wrong timeouts. In addition to these fixes, patches for enabling the support for Intel 7260 cards were incorporated.
Up to now, the configuration of the wireless driver was rather inconvenient because it did not export any information to the system. The driver now creates two distinct reports to communicate its state and information about the wireless infrastructure to other components. The first one is a list of all available access points. The following exemplary report shows its structure:
<wlan_accesspoints> <accesspoint ssid="skynet" bssid="00:01:02:03:04:05" quality="40"/> <accesspoint ssid="foobar" bssid="01:02:03:04:05:06" quality="70" protection="WPA-PSK"/> <accesspoint ssid="foobar" bssid="01:02:03:04:05:07" quality="10" protection="WPA-PSK"/> </wlan_accesspoints>
Each <accesspoint> node has attributes that contain the SSID and the BSSID of the access point as well as the link quality (signal strength). These attributes are mandatory. If the network is protected, the node will also have an attribute describing the type of protection in addition.
The second report provides information about the state of the connection with the currently associated access point:
<wlan_state>
<accesspoint ssid="foobar" bssid="01:02:03:04:05:06" quality="70"
protection="WPA-PSK" state="connected"/>
</wlan_state>
Valid state values are connected, disconnected, connecting and disconnecting.
The driver obtains its configuration via a ROM module. This ROM module contains the selected access point and can be updated during runtime. To connect to an access point, a configuration like the following is used:
<selected_accesspoint ssid="foobar" bssid="01:02:03:04:05:06"
protection="WPA-PSK" psk="foobar123!"/>
To disconnect from an access point, an empty configuration can be set:
<selected_accesspoint/>
For now, the prevalent WPA/WPA2 protection using a pre-shared key is supported.
Improved UART driver for Exynos5
The UART driver for the Exynos5 SoC has been enhanced by enabling the RX channel. This improvement was motivated by automated tests, where a run script needs to interact with some component via a terminal connection.
Touchscreen support
We enabled support of Wacom USB touchscreen devices via dde_linux - a port of Linux USB driver to Genode. In order to make touchscreen coordinates usable by Genode's input services, they must be calibrated to screen-absolute coordinates. The screen resolution is not determined automatically by the USB driver. It can, however, be configured as a sub node of the <hid> XML tag of the USB driver's configuration:
<start name="usb_drv">
...
<config uhci=... ohci=... xhci=...>
<hid>
<screen width="1024" height="768"/>
</hid>
...
USB session interface
We enhanced our USB driver with the support of remote USB sessions. This feature makes it possible to implement USB-device drivers outside the USB server using a native Genode API. The new USB session can be found under repos/os/include/usb_session and can be used to communicate with the USB server, which merely acts as a host controller and HUB driver in this scenario. Under repos/os/include/usb, there are a number of convenience and wrapper functions that operate directly on top of a USB session. These functions are meant to ease the task of USB-device-driver programming by hiding most of the USB session management, like packet-stream handling.
We also added a USB terminal server, which exposes a Genode terminal session to its clients and drives the popular PL2303 USB to UART adapters using the new USB-session interface. A practical use case for this component is the transmission of logging data on systems where neither UART, AMT, nor JTAG are available. A run script showcasing this feature can be found at repos/dde_linux/run/usb_terminal.run.
RTC proxy driver for Linux
There are a handful of run scripts that depend on the RTC service. So far, it was not possible to run these tests on Linux due to the lack of an RTC driver on this platform. To address this problem, we created a proxy driver that uses the time() system call to provide a reasonable base period on Linux.
Platforms
Execution on bare hardware (base-hw)
Support for the USB-Armory board
With USB Armory, there is an intriguing hardware platform for Genode on the horizon. In short, USB Armory is a computer in the form factor of a USB stick. It is meant for security applications such as VPNs, authentication tokens, and encrypted storage. It is based on the FreeScale i.MX53 SoC, which is well supported by Genode, i.e., Genode can be used as secure-world OS besides Linux running in the normal world. Apart from introducing a novel form factor, this project is interesting because it strives to be an 100% open platform, which includes hardware, software, and firmware. This motivated us to bring Genode to this platform.
The underlying idea is to facilitate ARM TrustZone to use Genode as a companion to a Linux-based OS on the platform. Whereas Linux would run in the normal world of TrustZone, Genode runs in the secure world. With Linux, the normal world will control the communication over USB and provide a familiar environment to implement USB-Armory applications. However, security-critical functions and data like cryptographic keys will reside exclusively in the secure world. Even in the event that Linux gets compromised, the credentials of the user will stay protected.
The support of the USB Armory platform was added in two steps: First, we enabled our base-hw kernel to run as TrustZone monitor with Genode on the "secure side". Since the USB Armory is based on the FreeScale i.MX53 SoC, which Genode already supported, this step went relatively straight-forward.
Second, we enabled a recent version of the Linux kernel (3.18) to run in the normal world. The normal world is supervised by a user-level Genode component called tz_vmm (TrustZone Virtual Machine Monitor). The tz_vmm is, among others, responsible for providing startup and hardware information to the non-secure guest. The Linux kernel version we used previously as TrustZone guest on i.MX53 boards expected this information to be communicated via so-called ATAGs. The new version, however, expects this to be done via a device tree blob. As a consequence, the tz_vmm had to be adapted to properly load this blob into the non-secure RAM. The original USB-Armory device tree was modified to blind out the RAM regions that get protected by the TrustZone hardware. This way, Linux won't attempt to access them. Furthermore, to keep basic user interaction simple, our device tree tells Linux to use the same non-secure UART as Genode for console I/O.
The kernel itself received some modifications, for two reasons. First, we don't want Linux to rely on resources that are protected to keep the secure world secure. This is why the driver for the interrupt controller that originally made use of the TrustZone interrupt configuration, had to be adapted. Second, to prevent Linux from disturbing Genode activities, we disabled most of the dynamic clock and power management as it may sporadically gear down or even disable hardware that Genode relies on. Furthermore, we disabled the Linux drivers for I2C interfaces and the GPIO configuration as these are reserved for Genode.
IPC helping
In traditional L4 microkernels, scheduling parameters (like time-slice length and priority) used to be bound to threads. Usually, those parameters are defined at thread creation time. The initial version of base-hw followed this traditional approach. However, it has a few problems:
-
For most threads, the proper choice of scheduling parameters is very difficult if not impossible. For example, the CPU-time demands of a server thread may depend on the usage patterns of its clients. Most theoretical work in the domain of scheduling presumes the knowledge of job lengths in advance of computing a schedule. But in practice and in particular in general-purpose computing, job lengths are hardly known a priori. As a consequence, in most scenarios, scheduling parameters are set to default values.
-
With each thread being represented as an independent schedulable entity, the kernel has to take a scheduling decision each time a thread performs an IPC call because the calling thread gets blocked and the called thread may get unblocked. In a microkernel-based system, those events occur at a much higher rate than the duration of typical time slices, which puts the scheduler in a performance-critical position.
-
Regarding IPC calls, a synchronous flow of control along IPC call chains is desired. Ideally, an IPC call should have the same characteristics as a function call with respect to scheduling. When a client thread performs an IPC call, it expects the server to immediately become active to handle the request. But if the kernel treats each thread independently, it may pick any other thread and thereby introduce high latencies into IPC operations.
To counter those problems, the NOVA microhypervisor introduced a new approach that decouples scheduling parameters from threads. Instead of selecting threads for execution, the scheduler selects so-called scheduling contexts. For a selected scheduling context, the kernel dynamically determines a thread to execute by taking IPC relationships into account. When a thread performs an IPC, the thread's scheduling context will be used to execute the called server. In principle, a server does not need CPU time on its own but always works with CPU resources provided by clients.
The new version of the base-hw kernel adapts NOVA's approach with slight modifications. Each thread owns exactly one scheduling context for its entire lifetime. However, by the means of "helping" during an IPC call, the caller lends its scheduling context to the callee. Even if the callee is still busy and cannot handle the IPC request right away, the caller helps because it wants the callee to become available for its request as soon as possible. Consequently, a thread has potentially many scheduling contexts at its disposal, its own scheduling context plus all scheduling contexts provisioned by helpers. This works transitively.
Purged outdated platforms
We removed the support for two stale platforms that remained unused for more than a year, namely FreeScale i.MX31 and the TrustZone variant of the Coretile Versatile Express board.
NOVA
On Genode/NOVA, we used to employ one pager thread in core for each thread in the system. We were forced to do so because not every page fault can be resolved immediately. In some situations, core asynchronously propagates the fault to an external component for the resolution. In the meantime, the pager thread leaves the page fault unanswered. Unfortunately, the kernel provides no mechanism to support this scenario besides just blocking the pager thread using a semaphore. This, in turn, means that the pager thread is not available for other page-fault requests. Ultimately, we had to setup a dedicated pager per thread.
This implementation has the downside of "wasting" memory for a lot of pager threads. Moreover, it becomes a denial-of-service vector as soon as more threads get created than core can accommodate. The number of threads is limited per address space - also for core - by the size of Genode's context area, which typically means 256 threads.
To avoid the downsides mentioned, we extended the NOVA IPC reply syscall to specify an optional semaphore capability. The NOVA kernel validates the capability and blocks the faulting thread in the semaphore. The faulted thread remains blocked even after the pager has replied to the fault message. But the pager immediately becomes available for other page-fault requests. With this change, it suffices to maintain only one pager thread per CPU for all client threads.
The benefits are manifold. First, the base-nova implementation converges more closely to other Genode base platforms. Second, core can not run out of threads anymore as the number of threads in core is fixed for a given setup. And the third benefit is that the helping mechanism of NOVA can be leveraged for concurrently faulting threads.
Build system and tools
Tools for convenient handling of port contrib directories
We supplemented our tools for the ports mechanism with two convenient scripts:
- tool/ports/shortcut
-
Creates a symbolic link from contrib/<port-name>-<hash> to contrib/<port-name>. This is useful when working on the third-party code contained in the contrib directory.
- tool/ports/current
-
Prints the current contrib directory of a port. When switching branches back and forth, the hash of the used port might change. The script provides a shortcut to looking up the hash file for a specific port within the repositories and printing its content.