
Release notes for the Genode OS Framework 13.02
Traditionally, the February release of Genode is focused on platform support. The version 13.02 follows this tradition by vastly improving Genode for the NOVA base platform and the extending the range of ARM SoCs supported by both our custom kernel platform and the Fiasco.OC kernel.
The NOVA-specific improvements concern three major topics, namely the added support for running dynamic workloads on this kernel, the use of IOMMUs, and the profound integration of the Vancouver virtual machine monitor with the Genode environment. The latter point is particularly exciting to us because this substantial work is the first contribution by Intel Labs to the Genode code base. Thanks to Udo Steinberg and Markus Partheymüller for making that possible.
Beyond the x86 architecture, the new version comes with principal support for the ARM Cortex-A15-based Exynos 5250 SoC and the Freescale i.MX53 SoC. The Exynos 5250 SoC has been enabled for our custom kernel as well as for the Fiasco.OC kernel. The most significant functional improvements are a new facility to detect faulting processes and a new mechanism for file-system notifications.
Besides those added functionalities, the release cycle was taken as an opportunity to revisit several aspects under the hood of the framework. A few examples are the reworked synchronization primitives, the simplified base library structure, the completely redesigned audio-output interface, and a modernized timer interface.
DMA protection via IOMMU
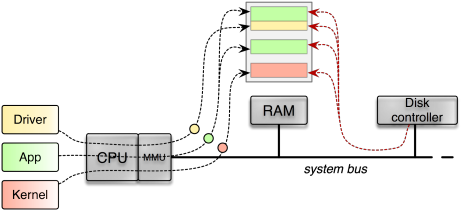
Direct memory access (DMA) of devices is universally considered as the Achilles heel of microkernel-based operating systems. The most compelling argument in favour of using microkernels is that by encapsulating each system component within a dedicated user-level address space, the system as a whole becomes more robust and secure compared to a monolithic operating-system kernel. In the event that one component fails due to a bug or an attack, other components remain unaffected. The prime example for such buggy components are device drivers. By empirical evidence, those remain the most prominent trouble makers in today's operating systems. Unfortunately however, most commodity hardware used to render this nice argumentation moot because it left one giant loophole open, namely bus-master DMA.
Via bus-master DMA, a device attached to the system bus is able to directly access the RAM without involving the CPU. This mechanism is crucial for all devices that process large amounts of data such as network adapters, disk controllers, or USB controllers. Because those devices can issue bus requests targeting the RAM directly and not involving the CPU altogether, such requests are naturally not subjected by the virtual-memory mechanism implemented in the CPU in the form of an MMU. From the device's point of view there is just physical memory. Hence, if a driver sets up a DMA transaction, let's say a disk driver wants to read a block from the disk, the driver tells the device about the address and size of a physical-memory buffer where the it wants to receive the data. If the driver lives in a user-level process, as is the case for a microkernel-based system, it still needs to know the physical address to program the device correctly. Unfortunately, there is nothing to prevent the driver from specifying any physical address to the device. Consequently, a malicious driver could misuse the device to read and manipulate all parts of the memory, including the kernel.
|
|
Traditional machine without IOMMU. Direct memory accesses issued by the disk controller are not subjected to the MMU. The disk controller can access the entity of memory present in the system.
|
So - does this loop hole render the micro-kernel approach useless? Of course not. Putting each driver in a dedicated address space is still beneficial in two ways. First, classes of bugs that are unrelated to DMA remain confined in the driver's address space. In practice most driver issues arise from issues like memory leaks, synchronization problems, deadlocks, flawed driver logic, wrong state machines, or incorrect device-initialization sequences. For those classes of problems, the microkernel argument still applies. Second, executing a driver largely isolated from other operating-system code minimizes the attack surface of the driver. If the driver interface is rigidly small and well-defined, it is hard to compromise the driver by exploiting its interface.
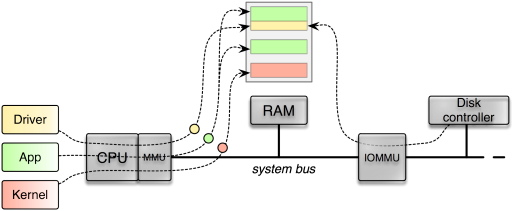
Still the DMA issue remains to be addressed. Fortunately, modern PC hardware has closed the bus-master-DMA loophole by incorporating a so-called IOMMU into the system. As depicted in the following figure, the IOMMU sits between the RAM and the system bus where the devices are attached to. So each DMA request has to pass the IOMMU, which is not only able to arbitrate the access of DMA requests to the RAM but also able to virtualize the address space per device. Similar to how a MMU confines each process running on the CPU within a distinct virtual address space, the IOMMU is able to confine each device within a dedicated virtual address space. To tell the different devices apart, the IOMMU uses the PCI device's bus-device-function triplet as unique identification.
|
|
An IOMMU arbitrates and virtualizes DMA accesses issued by a device to the RAM. Only if a valid IOMMU mapping exists for a given DMA access, the memory access is performed.
|
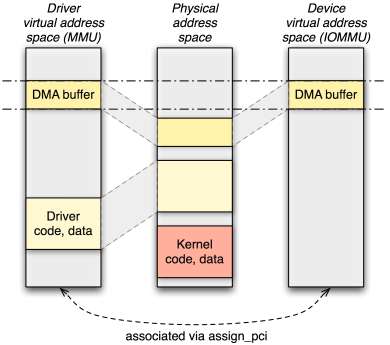
Of the microkernels supported by Genode, NOVA is the first kernel that supports the IOMMU. NOVAs interface to the IOMMU is quite elegant. The kernel simply applies a subset of the (MMU) address space of a process (aka protection domain in NOVA speak) to the (IOMMU) address space of a device. So the device's address space can be managed in the same way as we normally manage the address space of a process. The only missing link is the assignment of device address spaces to process address spaces. This link is provided by the dedicated system call "assign_pci" that takes a process identifier and a device identifier as arguments. Of course, both arguments must be subjected to a security policy. Otherwise, any process could assign any device to any other process. To enforce security, the process identifier is a capability to the respective protection domain and the device identifier is a virtual address where the extended PCI configuration space of the device is mapped in the specified protection domain. Only if a user-level device driver got access to the extended PCI configuration space of the device, it is able to get the assignment in place.
To make NOVA's IOMMU support available to Genode programs, we enhanced the ACPI/PCI driver with the ability to hand out the extended PCI configuration space of a device and added a NOVA-specific extension to the PD session interface. The new assign_pci function allows the assignment of a PCI device to the protection domain.
|
|
NOVAs management of the IOMMU address spaces facilities the use of driver-local virtual addresses as DMA addresses.
|
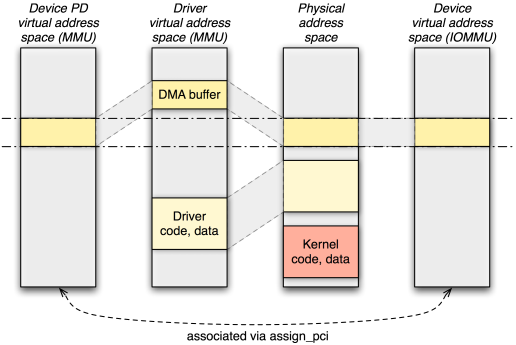
Even though these mechanisms combined principally suffice to let drivers operate with the IOMMU enabled, in practice, the situation is a bit more complicated. Because NOVA uses the same virtual-to-physical mappings for the device as it uses for the process, the DMA addresses the driver needs to supply to the device must be virtual addresses rather than physical addresses. Consequently, to be able to make a device driver usable on systems without IOMMU as well as on systems with IOMMU, the driver needs to be IOMMU-aware and distinguish both cases. This is an unfortunate consequence of the otherwise elegant mechanism provided by NOVA. To relieve the device drivers from caring about both cases, we came up with a solution that preserves the original device interface, which expects physical addresses. The solution comes in the form of so called device PDs. A device PD represents the address space of a device as a Genode process. Its sole purpose is to hold mappings of DMA buffers that are accessible by the associated device. By using one-to-one physical-to-virtual mappings for those buffers within the device PD, each device PD contains a subset of the physical address space. The ACPI/PCI server performs the assignment of device PDs to PCI devices. If a device driver intends to use DMA, it asks the ACPI/PCI driver for a new DMA buffer. The ACPI/PCI driver allocates a RAM dataspace at core, attaches it to the device PD using the dataspace's physical address as virtual address, and hands out the dataspace capability to the driver. If the driver requests the physical address of the dataspace, the returned address will be a valid virtual address in the associated device PD. From this design follows that a device driver must allocate DMA buffers at the ACPI/PCI server (while specifying the PCI device the buffer is intended for) instead of using core's RAM service to allocate buffers anonymously. The current implementation of the ACPI/PCI server assigns all PCI devices to only one device PD. However, the design devises a natural way to partition devices into different device PDs.
|
|
By modelling a device address space as a dedicated process (device PD), the traditional way of programming DMA transactions can be maintained, even with the IOMMU enabled.
|
Because the changed way of how DMA buffers are allocated, our existing drivers such as the AHCI disk driver, the OSS sound driver, the iPXE network driver, and the USB driver had to be slightly modified. We also extended DDE Kit with the new dde_kit_pci_alloc_dma_buffer function for allocating DMA buffers. With those changes, the complete Genode user land can be used on systems with IOMMU enabled. Hence, we switched on the IOMMU on NOVA by default.
Full virtualization on NOVA/x86
Vancouver is a x86 virtual machine monitor that is designed to run as user-level process on top of the NOVA hypervisor. In Genode version 11.11, we introduced the preliminary adaptation of Vancouver to Genode. This version was meant as a mere proof of concept, which allowed the bootup of small Guest OSes (such as Fiasco.OC or Pistachio) inside the VMM. However, it did not support any glue code to Genode's session interface, which limited the usefulness of this virtualization solution at that point. We had planned to continue the integration of Vancouver with Genode once we observed public demand.
The move of NOVA's development to Intel Labs apparently created this demand. It is undeniable that combining the rich user land provided by Genode with the capabilities of the Vancouver VMM poses an attractive work load for NOVA. So the stalled line of the integration work of Vancouver with Genode was picked up within Intel Labs, more specifically by Markus Partheymüller. We are delighted to be able to merge the outcome of this undertaking into the mainline Genode development. Thanks to Intel Labs and Markus in particular for this substantial contribution!
The features added to the new version of Vancouver for Genode are as follows:
- VMX support
-
Our initial version supported AMD's SVM technology only because this was readily supported by Qemu. With the added support for Intel VMX, Vancouver has become able to operate on both Intel and AMD processors with hardware virtualization support.
- Timer support
-
With added support for timer interrupts, the VMM has become able to boot a complete Linux system.
- Console support
-
With this addition, the guest VM can be provided with a frame buffer and keyboard input.
For the frame-buffer size in Vancouver, the configuration value in the machine XML node is used. It is possible to map the corresponding memory area directly to the guest regardless if it comes from nitpicker, a virtual frame buffer, or the VESA driver. The guest is provided with two modes (text mode 3 and graphics mode 0x114 (0x314 in Linux).
Pressing LWIN+END while a VM has focus resets the virtual machine. Also, RESET and DEBUG key presses will not be forwarded to the VM anymore. It is possible to dump a VM's state by pressing LWIN+INS keys.
The text console is able to detect idle mode, unmaps the buffer from the guest and stops interpreting. Upon the next page fault in this area, it resumes operation again. The code uses a simple checksum mechanism instead of a large buffer and memcmp to detect an idle text console. False positives don't matter very much.
- Network support
-
The VMM has become able to use the Intel 82576 device model from the NUL user land to give VMs access to the network via Genode's NIC bridge service or a NIC driver.
- Disk support
-
The VMM can now assign block devices to guests using Genode's block-session interface. The machine has to be configured to use a specified drive, which could be theoretically routed to different partitions or services via policy definitions. Currently the USB driver only supports one device. Genode's AHCI driver is untested.
- Real-time clock
-
By using the new RTC session interface, Vancouver is able to provide the wall-clock time to guest OSes.
To explore the new version of the Vancouver VMM, there exists a ready-to-use run script at ports/run/vancouver.run. Only the guest OS binaries such as a Linux kernel image and a RAM disk must be manually supplied in the <build-dir>/bin directory. The run script is able to start one or multiple instances of the VMM using the graphical launchpad.
Low-latency audio output
In version 10.05, we introduced an interface for the playback of audio data along with an audio mixer component and ALSA-based sound drivers ported from the Linux kernel. The original Audio_out session interface was based on Genode's packet stream facility, which allows the communication of bulk data across address spaces via a combination of shared memory and signals. Whereas shared memory is used to transfer the payload in an efficient manner without the need to copy data via the kernel, signals are used to manage the data flow between the information source and sink.
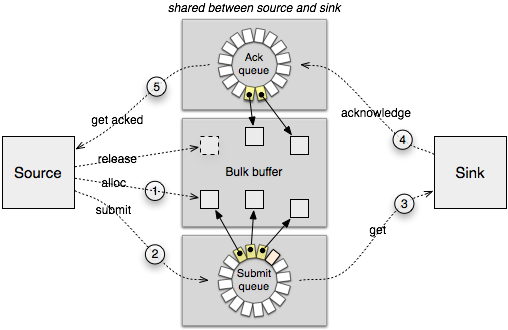
|
Figure 5 displays the life cycle of a packet of information transferred from the source to the sink. The original intent behind the packet-stream facility was the transmission of networking packets and blocks of block devices. At the time when we first introduced the Audio_out interface, the packet stream seemed like a good fit for audio, too. However, in the meanwhile, we came to the conclusion that this is not the case when trying to accommodate streamed audio data and sporadic audio output at the same time.
For the output of streamed audio data, a codec typically decodes a relatively large portion of an audio stream and submits the sample data to the mixer. The mixer, in turn, mixes the samples of multiple sources and forwards the result to the audio driver. Each of those components the codec, the mixer, and the audio driver live in a separate process. By using large buffer sizes between them, the context-switching overhead is hardly a concern. Also, the driver can submit large buffers of sample data to the sound device without any further intervention needed.
In contrast, sporadic sounds are used to inform the user about an immediate event. It is ultimately expected that such sounds are played back without much latency. Otherwise the interactive experience (e.g., of games) would suffer. Hence, using large buffers between the audio source, the mixer, and the driver is not an option. By using the packet stream concept, we have to settle on a specific buffer size. A too small buffer increases CPU load caused by many context switches and the driver, which has to feed small chunks of sample data to the sound device. A too large buffer, however, makes sporadic sounds at low latencies impossible. We figured out that the necessity to find a sweet spot for picking a buffer size is a severe drawback. This observation triggered us to replace the packet-stream-based communication mechanism of the Audio_out session interface by a new solution that we specifically designed to accommodate both corner cases of audio output.
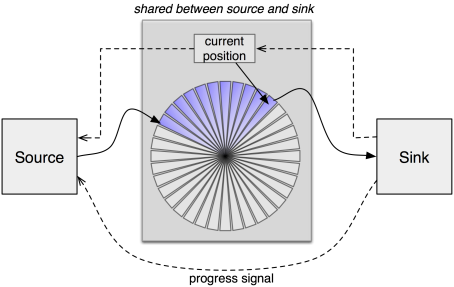
|
Similarly to the packet-stream mechanism, the new interface is based on a combination of shared memory and signals. However, we dropped the notion of ownership of packets. When using the packet-stream protocol depicted as above, either the source or the sink is in charge of handling a given packet at a given time, not both. At the points 1, 2, and 4, the packet is owned by the source. At the points 3 and 4, the packet is owned by the sink. By putting a packet descriptor in the submit queue or acknowledgement queue, there is a handover of responsibility. The new interface weakens this notion of ownership by letting the source update once submitted audio frames even after submitting them. If there are solely continuous streams of audio arriving at the mixer, the mixer can mix those large batches of audio samples at once and pass the result to the driver.
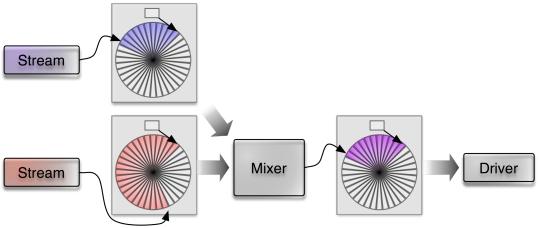
|
|
The mixer processes incoming data from multiple streaming sources as batches.
|
Now, if a sporadic sound comes in, the mixer checks the current output position reported by the audio driver, and re-mixes those portions that haven't been played back yet by incorporating the sporadic sound. So the buffer consumed by the driver gets updated with new data.
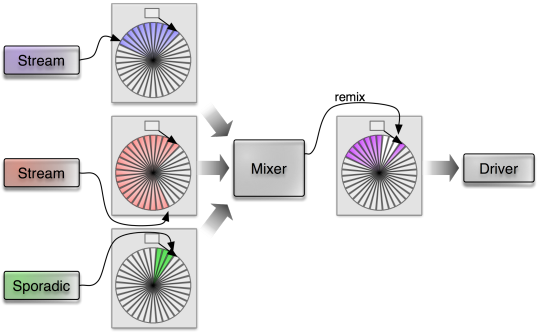
|
|
A sporadic occuring sound prompts the mixer to remix packets that are already submitted in the output queue.
|
Besides changing the way of how packets are populated with data, the second major change is turning the interface into a time-triggered concept. The driver produces periodic signals that indicate the completeness of a played-back audio packet. This signal triggers the mixer to become active, which in turn serves as a time base for its clients. The current playback position is denoted alongside the sample data as a field in the memory buffer shared between source and sink.
The new Audio_out interface has the potential to align the requirements of both streamed audio with those of sporadic sounds. As a side benefit, the now domain-specific interface has become simpler than the original packet-stream based solution. This becomes nowhere as evident as in the implementation of the mixer, which has become much simpler (30% less code). The interface change is accompanied with updates of components related to audio output, in particular the OSS sound drivers contained in dde_oss, the ALSA audio driver for Linux, the avplay media player, and the libSDL audio back-end.
Base framework
Signalling API improvements
The signalling API provided by base/signal.h is fairly low level. For employing the provided mechanism by application software, we used to craft additional glue code that translates incoming signals to C++ method invocations. Because the pattern turned out to be not only useful but a good practice, we added the so called Signal_dispatcher class template to the signalling API.
In addition to being a Signal_context, a Signal_dispatcher associates a member function with the signal context. It is intended to be used as a member variable of the class that handles incoming signals of a certain type. The constructor takes a pointer-to-member to the signal handling function as argument. If a signal is received at the common signal reception code, this function will be invoked by calling Signal_dispatcher_base::dispatch. This pattern can be observed in the implementation of RAM file system (os/src/server/ram_fs).
Under the hood, the signalling implementation received a major improvement with regard to the life-time management of signal contexts. Based on the observation that Signal objects are often referring to non-trivial objects derived from Signal_context, it is important to defer the destruction of such objects to a point when no signal referring to the context is in flight anymore. We solved this problem by modelling Signal type as a shared pointer that operates on a reference counter embedded in the corresponding Signal_context. Based on reference counter, the Signal_receiver::dissolve() function does not return as long as the signal context to be dissolved is still referenced by one or more Signal objects.
Trimmed and unified framework API
A though-provoking posting on our mailing list prompted us to explore the idea to make shared libraries and dynamically linked executables binary compatible among different kernels. This sounds a bit crazy at first but it is not downright infeasible.
As a baby step into this direction, we unified several public headers of the Genode API and tried to make headers private to the framework where possible. The latter is the case for the base/platform_env.h header, which is actually not part of the generic Genode API. Hence, it was moved to the framework-internal src/base/env. Another step was the removal of platform-specific types that are not necessarily platform-dependent. We could remove the Native_lock type without any problems. Also, we were able to unify the IPC API, which was formerly split into the two parts base/ipc_generic.h and base/ipc.h respectively. Whereas base/ipc_generic.h was shared among all platforms, the base/ipc.h header used to contain platform-specific IPC marshalling and unmarshalling code. But by moving this code from the header to the corresponding (platform-specific) IPC library, we were able to discard the content of base/ipc.h altogether. Consequently, the former base/ipc_generic.h could be renamed to base/ipc.h. These changes imply no changes at the API level.
Simplified structure of base libraries
The Genode base API used to come in the form of many small libraries, each covering a dedicated topic. Those libraries were allocator_avl, avl_tree, console, env, cxx, elf, env, heap, server, signal, slab, thread, ipc, and lock. The term "library" for those bits of code was hardly justified as most of the libraries consisted of only a few .cc files. Still the build system had to check for their inter-dependencies on each run of the build process. Furthermore, for Genode developers, specifying the list of base libraries in their target.mk files tended to be an inconvenience. Also, the number of libraries and their roles (core only, non-core only, shared by both core and non-core) were not easy to capture. Hence, we simplified the way of how those base libraries are organized. They have been reduced to the following few libraries:
-
cxx.mk contains the C++ support library
-
startup.mk contains the startup code for normal Genode processes On some platform, core is able to use the library as well.
-
base-common.mk contains the parts of the base library that are identical by core and non-core processes.
-
base.mk contains the complete base API implementation for non-core processes
Consequently, the LIBS declaration in target.mk files becomes simpler as well. In the normal case, only the base library must be mentioned.
New fault-detection mechanism
Until now, it was hardly possible for a parent process to respond to crashes of child processes in a meaningful way. If a child process crashed, the parent would normally just not take notice. Even though some special use cases such as GDB monitor could be accommodated by the existing Cpu_session::exception_handler facility, this mechanism requires the virtualization of the Cpu_session interface because an exception handler used to refer to an individual thread rather than the whole process. For ordinary parents, this mechanism is too cumbersome to use. However, there are several situations where a parent process would like to actively respond to crashing children. For example, the parent might like to restart a crashed component automatically, or enter a special failsafe mode.
To ease the implementation of such scenarios, we enhanced the existing Cpu_session::exception_handler mechanism with the provision of a default signal handler that is used if no thread-specific handler is installed. The default signal handler can be set by specifying an invalid thread capability and a valid signal-context capability. So for registering a signal handler to all threads of a process, no virtualization of the Cpu_session interface is needed anymore. The new mechanism is best illustrated by the os/run/failsafe.run script, which creates a system that repeatedly spawns a crashing child process.
Reworked synchronization primitives
We reworked the framework-internal lock interface in order to be able to use the futex syscall on the Linux base platform. Previously, the lock implementation on Linux was based on Unix signals. In the contention case, the applicant for a contended lock would issue a blocking system call, which gets canceled by the occurrence of a signal. We used nanosleep for this purpose. Once the current owner of the lock releases the lock, it sends a signal to the next applicant of the lock. Because signals are buffered by the kernel, they are guaranteed to be received by the targeted thread. However, in situations with much lock contention, we observed the case where the signal was delivered just before the to-be-blocked thread could enter the nanosleep syscall. In this case, the signal was not delivered at the next entrance into the kernel (when entering nanosleep) but earlier. Even though the signal handler was invoked, we found no elegant way to handle the signal such that the subsequent nanosleep call would get skipped. So we decided to leave our signal-based solution behind and went for the mainstream futex mechanism instead.
Using this mechanism required us to re-design the internal lock API, which was originally designed with the notion of thread IDs. The Native_thread_id type, which was previously used in the lock-internal Applicant class to identify a thread to be woken up, was not suitable anymore for implementing this change. Hence, we replaced it with the Thread_base* type, which also has the positive effect of making the public base/cancelable_lock.h header file platform-independent.
In addition to reworking the basic locking primitives, we changed the Object_pool data structure to become safer to use. The former obj_by_* functions have been replaced by lookup_and_lock that looks up an object and locks it in one atomic operation. Additionally, the case that an object may already be in destruction is handled gracefully. In this case, the lookup will return that the object is not available anymore.
Low-level OS infrastructure
Notification mechanism for the file-system interface
To support dynamic system scenarios, we extended Genode's file-system interface with the ability to monitor changes of files or directories, similar to the inotify mechanism on Linux but simpler. The new File_system::sigh function can be used to install a signal handler for an open file node. When a node is closed after a write operation, a prior registered signal handler for this file gets notified. Signal handlers can also be installed for directories. In this case, the signal handler gets informed about changes of immediate nodes hosted in the directory, i.e., the addition, renaming, or removal of nodes.
The ram_fs server has been enhanced to support the new interface. So any file or directory change can now be observed by ram_fs clients.
New adapter from file-system to ROM session interface
The new fs_rom server translates the File_system session interface to the ROM session' interface. Each request for a ROM file is handled by looking up an equally named file on the file system. If no such file can be found, then the server will monitor the file system for the creation of the corresponding file. Furthermore, the server reflects file changes as signals to the ROM session.
There currently exist two limitations: First, symbolic links are not handled. Second, the server needs to allocate RAM for each requested file. The RAM is always allocated from the RAM session of the server. Thereby, the RAM quota consumed by the server depends on the client requests and the size of the requested files. Therefore, one instance of the server should not be used by untrusted clients and trusted clients at the same time. In such situations, multiple instances of the server could be used.
The most interesting feature of the fs_rom server is the propagation of file-system changes as ROM module changes. This clears the way to use this service to supply dynamic configurations to Genode programs.
Dynamic re-configuration of the init process
The init process has become able to respond to configuration changes by restarting the scenario using the new configuration. To make this feature useful in practice, init must not fail under any circumstances. Even on conditions that were considered previously as fatal and led to the abort of init (such as ambiguous names of the children or misconfiguration in general), init must stay alive and responsive to configuration changes.
With this change, the init process is one of the first use cases of the dynamic configuration feature enabled via the fs_rom service and the new file-system notifications. By supplying the configuration of an init instance via the fs_rom and ram_fs services, the configuration of this instance gets fetched from a file of the ram_fs service. Each time, this file is changed, for example via VIM running within a Noux runtime environment, the init process re-evaluates its configuration.
In addition to the support for dynamic re-configurations, we simplified the use of conditional session routing, namely the <if-args> mechanism. When matching the label session argument using <if-args> in a routing table, we can omit the child name prefix because it is always the same for all sessions originating from the child anyway. By handling the matching of session labels as a special case, the expression of label-specific routing becomes more intuitive.
Timer interface turned into asynchronous mode of operation
The msleep function of Timer::Session interface is one of the last relics of blocking RPC interfaces present in Genode. As we try to part away from blocking RPC calls inside servers and as a means to unify the timer implementation across the many different platforms supported by Genode, we changed the interface to an asynchronous mode of operation.
Synchronous blocking RPC interfaces turned out to be constant sources of trouble and code complexity. E.g., a timer client that also wants to respond to non-timer events was forced to be a multi-threaded process. Now, the blocking msleep call has been replaced by a mechanism for programming timeouts and receiving wakeup signals in an asynchronous fashion. Thereby signals originating from the timer can be handled, along with signals from other signal sources, by a single thread. Once a timer client has registered a signal handler using the Timer::sigh function, it can program timeouts using the functions trigger_once and trigger_periodic, which take an amount of microseconds as argument. For maintaining compatibility and convenience, the interface still contains the virtual msleep function. However, it is not an RPC function anymore but a mere client-side wrapper around the sigh and trigger_once functions. For use cases where sleeping at the granularity of milliseconds is too coarse (such as udelay calls by device drivers), we added a new usleep call, which takes a number of microseconds as argument.
As a nice side effect of the interface changes, the platform-specific implementations could be vastly unified. On NOVA and Fiasco.OC, the need to use one thread per client has vanished. As a further simplification, we changed the timer to use the build system's library-selection mechanism instead of providing many timer targets with different REQUIRES declarations. This reduces the noise of the build system. For all platforms, the target at os/src/drivers/timer is built. The target, in turn, depends on a timer library, which is platform-specific. The various library description files are located under os/lib/mk/<platform>. The common bits are contained in os/lib/mk/timer.inc.
Since the msleep call is still available from the client's perspective, the change of the timer interface does not imply an API incompatibility. However, it provides the opportunity to simplify clients in cases that required the maintenance of a separate thread for the sole purpose of periodic signal generation.
Loader
The loader is a service that enables its clients to dynamically create Genode subsystems. Leveraging the new fault-detection support described in section New fault-detection mechanism, we enabled loader clients to respond to failures that occur inside the spawned subsystem. This is useful for scenarios where subsystems should be automatically restarted or in situations where the system should enter a designated failsafe mode once an unexpected fault happens.
The loader provides this feature by installing an optional client-provided fault handler as default CPU exception handler and a RM fault handler for all CPU and RM sessions of the loaded subsystem. This way, the failure of any process within the subsystem gets reflected to the loader client as a signal.
The new os/run/failsafe.run test illustrate this mechanism. It covers two cases related to the loader, which are faults produced by the immediate child of the loader and faults produced by indirect children.
Focus events for the nitpicker GUI server
To enable a way for applications to provide visual feedback to changed keyboard focus, we added a new FOCUS event type to the Input::Event structure. To encode whether the focus was entered or left, the former keycode member is used (value 0 for leaving, value 1 for entering). Because keycode is misleading in this context, the former Input::Event::keycode function was renamed to Input::Event::code. The nitpicker GUI server has been adapted to deliver focus events to its clients.
NIC bridge with support for static IP configuration
NIC bridge is a service that presents one physical network adaptor as many virtual network adaptors to its clients. Up to now, it required each client to obtain an IP address from a DHCP server at the physical network. However, there are situations where the use of static IPs for virtual NICs is useful. For example, when using the NIC bridge to create a virtual network between the lighttpd web server and the Arora web browser, both running as Genode processes without real network connectivity.
The static IP can be configured per client of the NIC bridge using a <policy> node of the configuration. For example, the following policy assigns a static address to a client with the session label "lighttpd".
<start name="nic_bridge">
...
<config>
<policy label="lighttpd" ip_addr="10.0.2.55"/>
</config>
</start>
Of course, the client needs to configure its TCP/IP stack to use the assigned IP address. This can be done via configuration arguments examined by the lwip_nic_dhcp libc plugin. For the given example, the configuration for the lighttpd process would look as follows.
<start name="lighttpd">
<config>
<interface ip_addr="10.0.2.55"
netmask="255.255.255.0"
gateway="10.0.2.1"/>
</config>
</start>
Libraries and applications
New terminal multiplexer
The new terminal_mux server located at gems/src/server/terminal_mux is able to provide multiple terminal sessions over one terminal-client session. The user can switch between the different sessions using a keyboard shortcut, which brings up an ncurses-based menu.
The terminal sessions provided by terminal_mux implement (a subset of) the Linux terminal capabilities. By implementing those capabilities, the server is interchangeable with the graphical terminal (gems/src/server/terminal). The terminal session used by the server is expected to by VT102 compliant. This way, terminal_mux can be connected via an UART driver with terminal programs such as minicom, which typically implement VT102 rather than the Linux terminal capabilities.
When started, terminal_mux displays a menu with a list of currently present terminal sessions. The first line presents status information, in particular the label of the currently visible session. A terminal session can be selected by using the cursor keys and pressing return. Once selected, the user is able to interact with the corresponding terminal session. Returning to the menu is possible at any time by pressing control-x.
For trying out the new terminal_mux component, the gems/run/termina_mux.run script sets up a system with three terminal sessions, two instances of Noux executing VIM and a terminal_log service that shows the log output of both Noux instances.
New ported 3rd-party libraries
To support our forthcoming port of Git to the Noux runtime environment, we have made the following libraries available via the libports repository:
-
libssh-0.5.4
-
curl-7.29.0 (for now the port is x86_* only because it depends on libcrypto, which is currently not tested on ARM)
-
iconv-1.14
Device drivers
Besides the changes concerning the use of IOMMUs, the following device driver have received improvements:
- UART drivers
-
The OMAP4 platform support has been extended by a new UART driver, which enables the use of up to 4 UART interfaces. The new driver is located at os/src/drivers/uart/omap4.
All UART drivers implement the Terminal::Session interface, which provides read/write functionality accompanied by a function to determine the terminal size. The generic UART driver code shared among the various implementations has been enhanced to support the detection of the terminal size using a protocol of escape sequences. This feature can be enabled by including the attribute detect_size="yes" in the policy of a UART client. This is useful for combining UART drivers with the new terminal_mux server.
- ACPI support for 64-bit machines
-
In addition to IOMMU-related modifications, the ACPI driver has been enhanced to support 64-bit machines and MCFG table parsing has been added.
- PCI support for IOMMUs
-
With the added support of IOMMUs, the Pci::Session interface has been complemented with a way to obtain the extended PCI configuration space in the form of a Genode::Dataspace. Also, the interface provides a way to allocate DMA buffers for a given PCI device. Device drivers that are meant to be used on system with and without IOMMUs should use this interface rather than core's RAM session interface to allocate DMA buffers.
- Real-time clock on x86
-
Up to now, the x86 real-time clock driver served as a mere example for accessing I/O ports on x86 machines but the driver did not expose any service interface. With the newly added os/include/rtc_session interface and the added support of this interface in the RTC driver, Genode programs have now become able to read the real-time clock. Currently, the interface is used by the Vancouver VMM.
- USB driver restructured, support for Arndale board added
-
While adding support for the Exynos-5-based Arndale board, we took the chance to restructure the driver to improve portability to new platforms. The most part of the driver has become a library, which is built in a platform-specific way. The build system automatically selects the library that fits for the platform as set up for the build directory.
Platforms
NOVA
The NOVA base platform received major improvements that address the kernel as well as Genode's NOVA-specific code. We pursued two goals with this line of work. The first goal was the use of NOVA in highly dynamic settings, which was not possible before, mainly due to lacking kernel features. The second goal was the use of IOMMUs.
NOVA is ultimately designed for accommodating dynamic workloads on top of the kernel. But we found that the implementation of crucial functionality was missing. In particular, the kernel lacked the ability to destroy all kinds of kernel objects and to reuse memory of kernel objects that had been destroyed. Consequently, when successively creating and destroying kernel objects such as threads and protection domains, the kernel would eventually run out of memory. This issue became a show stopper for running the Genode tool chain on NOVA because this scenario spawns and destroys hundreds of processes. For this reason, we complemented the kernel with the missing functionality. This step involved substantial changes in the kernel code. So our approach of using the upstream kernel and applying a hand full of custom patches started to show its limitations.
To streamline our work flow and to track the upstream kernel in a structured way, we decided to fork NOVA's Git repository and maintain our patches in our fork. For each upstream kernel revision that involves kernel ABI changes, we create a separate branch called "r<number>". This branch corresponds to the upstream kernel with our series of custom patches applied (actually rebased) on top. This way, our additions to the upstream kernel are well documented. The make prepare mechanism in the base-nova repository automates the task of checking out the right branch. So from the Genode user's point of view, this change is transparent.
The highly dynamic application scenarios executed on NOVA triggered several synchronization issues in Genode's core process that had not been present on other base platforms. The reason for those issues to occur specifically on NOVA lies in the concurrent page fault handling as employed on this base platform. For all classical L4-like kernels and Fiasco.OC, we use one global pager thread to resolve all page faults that occur in the whole Genode system. In contrast, on NOVA we use one pager thread per user thread. Consequently, proper fine-grained synchronization between those pager threads and the other parts of core is mandated. Even though the immediate beneficiary of these changes is the NOVA platform, many of the improvements refer to generic code. This paves the ground for scaling the page-fault handling on other base platforms (such as Fiasco.OC) to multiple threads. With these improvements in place, we are able to successfully execute the noux_tool_chain_nova scenario on the NOVA kernel and build Genode's core on NOVA. That said, however, not all issues are covered yet. So there is still a way left to go to turn base-nova into a base platform that is suitable for highly dynamic scenarios.
The second goal was the use of NOVA's IOMMU support on Genode. This topic is covered in detail in section DMA protection via IOMMU.
To be able to use and debug Genode on NOVA on modern machines that lack legacy comports, we either use UART PCI cards or the Intel's Active Management Technology (AMT) mechanism. In both cases, the I/O ports to access the serial interfaces differ from the legacy comports. To avoid the need for adjusting the I/O port base addresses per platform, we started using the chain-boot-loader called "bender" developed by the Operating Systems Group of TU Dresden, Germany. This boot loader is started prior the kernel, searches the PCI bus for the first suitable device and registers the corresponding I/O port base address at the bios data area (BDA). Genode's core, in turn, picks the I/O port base address up from the BDA and uses the registered i8250 serial controller for its LOG service.
Execution on bare hardware (base-hw)
The base-hw platform enables the use of Genode on ARM-based hardware without the need for a 3rd-party kernel.
With the new release, the range of supported ARM-based hardware has been extended to cover the following additional platforms. With the previous release, we introduced the support for Freescale i.MX family of SoC, starting with i.MX31. The current release adds support for the i.MX53 SoC and adds a user-level timer driver for this platform. With the Samsung Exynos 5, the first Cortex-A15-based SoC has entered the list of supported SoCs. Thanks to this addition, Genode has become able to run on the Howchip Arndale board. At the current state, core and multiple instances of init can be executed but drivers for peripherals are largely missing. Those will be covered by our ongoing work with this SoC. The added platforms are readily available via the create_builddir tool.
To make base-hw practically usable on real hardware (i.e., the Pandaboard), support for caches has been implemented. Furthermore, the implementation of the signalling API underwent a redesign, which leverage the opportunities that arise with tailoring a kernel specifically to the Genode API. As a side-benefit of this endeavour, we could unify the base/signal.h header with the generic version and thereby took another step towards the unification of the Genode headers across different kernels.
Microblaze platform removed
The base-mb platform has been removed because it is no longer maintained. This platform enabled Genode to run directly on the Xilinx Microblaze softcore CPU. For supporting the Microblaze CPU architecture in the future, we might consider integrating support for this architecture into base-hw. Currently though, there does not seem to be any demand for it.
Fiasco.OC forked, support for Exynos 5 SoC added
In the last release cycle, we went beyond just using the Fiasco.OC kernel and started to engage with the kernel code more intensively. To avoid that the management of a growing number of kernel patches goes out of hand, we forked the Fiasco.OC kernel and conduct our development in our Fiasco.OC Git repository. When using the make prepare mechanism in the base-foc repository, the new Git repository will be used automatically. There exists a dedicated branch for each upstream SVN revision that we use. We started with updating Fiasco.OC to the current revision 47. Hence, the current branch used by Genode is named "r47". The branch contains the unmodified state of the upstream SVN repository with our modifications appearing as individual commits on top. This makes it easy to keep track of the Genode-specific modifications. Please note that the update to Fiasco.OC requires minor adaptations inside the ports-foc repository. So for using L4Linux, "make prepare" must be issued in both repositories base-foc and ports-foc.
Speaking of engaging with the kernel code, the most profound improvement is the support for the Samsung Exynos-5-based Arndale board that we added to the kernel. This goes hand in hand with the addition of this platform to Genode. For creating a build directory targeting the Arndale board, just specify "foc_arndale" to the create_builddir tool. At the time of the release, several basic scenarios including the timer driver and the USB driver are working. Also, both Cortex-A15 CPUs of the Exynos 5 SoC are operational. However, drivers for most of the peripherals of the Exynos-5 SoC are missing, which limits the current scope of Genode on this platform.
Linux
Since the base-linux platform became used for more than a mere development vehicle, we are revisiting several aspects of this base platform. In the last release, we changed the synchronous inter-process-communication mechanism to the use of SCM rights. For the current release, it was time to have a closer look at the memory management within core. The Linux version of core used a part of the BSS to simulate access to physical memory. All dataspaces would refer to a portion of some_mem. So each time when core would access the dataspace contents, it would access its local BSS. For all processes outside of core, dataspaces were represented as files. We have now removed the distinction between core and non-core processes. Now, core uses the same Rm_session_mmap implementation as regular processes. This way, the some_mem could be abandoned. We still use a BSS variable for allocating core-local meta data though. The major benefit of this change is the removal of the artificial quota restriction that was imposed by the predefined size of the some_mem array. Now, the Linux base platform can use as much memory as it likes. Because the Linux kernel implements virtual memory, we are not bound by the physical memory. Hence, the available quota assigned to the init process is almost without bounds.
To implement the fault-detection mechanism described in section New fault-detection mechanism on Linux, we let core catch SIGCHLD signals of all Genode processes. If such a signal occurs, core determines the process that produced the signal by using wait_pid, looks up the CPU session that belongs to the process and delivers an exception signal to the registered exception handler. This way, abnormal terminations of Genode processes are reflected to the Genode API in a clean way and Genode processes become able to respond to terminating Genode child processes.
OKL4
The audio stub driver has been removed from OKLinux. Because of the changed Audio_out::Session interface, we needed to decide on whether to adapt the OKLinux stub driver to the changed interface or to remove the stub driver. Given the fact that OKLinux is not actively used, we decided for the latter.