
Release notes for the Genode OS Framework 10.02
After the release of the feature-packed version 9.11, we turned our attention to improving the platform support of the framework. The current release 10.02 bears fruit of these efforts on several levels.
First, we are proud to announce the support for two new base platforms, namely the NOVA hypervisor and the Codezero microkernel. These new kernels complement the already supported base platforms Linux, L4/Fiasco, L4ka::Pistachio, and OKL4. So why do we address so many different kernels instead of focusing our efforts to one selected platform? Our observation is that different applications pose different requirements on the kernel. Most kernels have a specific profile with regard to security, hardware support, complexity, scheduling, resource management, and licensing that may make them fit well for one application area but not perfectly suited for a different use case. There is no single perfect kernel and there doesn't need to be one. By using Genode, applications developed for one kernel can be ported to all the other supported platforms with a simple recompile. We believe that making Genode available on a new kernel is beneficial for the kernel developers, application developers, and users alike. For kernel developers, Genode brings additional workloads to stress-test their kernel, and it extends the application area of the kernel. Application developers can address several kernel platforms at once instead of tying their programs to one particular platform. Finally, users and system integrators can pick their kernel of choice for the problem at hand. Broadening the platform support for Genode helps to make the framework more relevant.
Second, we introduced a new way for managing real-time priorities, which fits perfectly with the recursive system structure of Genode. This clears the way to multi-media and other real-time workloads that we target with our upcoming work. We implemented the concept for the L4ka::Pistachio and OKL4 platforms. With real-time priorities on OKL4, it is possible to run multiple instances of the OKLinux kernel at the same time, each instance at a different priority.
Third, we vastly improved the existing framework, extended the ARM architecture support to cover dynamic loading and the C runtime, introduced a new thread-context management, added a plugin-concept to our C runtime, and improved several device drivers.
Even though platform support is the main focus of this release, we introduced a number of new features, in particular the initial port of the Python 2.6 script interpreter.
NOVA hypervisor as new base platform
When we started the development of Genode in 2006 at the OS Group of the Technische Universität Dresden, it was originally designated to be the user land of a next-generation and to-be-developed new kernel called NOVA. Because the kernel was not ready at that time, we had to rely on intermediate solutions as kernel platform such as L4/Fiasco and Linux during development. These circumstances led us to the extremely portable design that Genode has today and motivated us to make Genode available on the whole family of L4 microkernels. In December 2009, the day we waited for a long time had come. The first version of NOVA was publicly released:
- Official website of the NOVA hypervisor
Besides the novel and modern kernel interface, NOVA has a list of features that sets it apart from most other microkernels, in particular support for virtualization hardware, multi-processor support, and capability-based security.
Why bringing Genode to NOVA?
NOVA is an acronym for NOVA OS Virtualization Architecture. It stands for a radically new approach of combining full x86 virtualization with microkernel design principles. Because NOVA is a microkernelized hypervisor, the term microhypervisor was coined. In its current form, it successfully addresses three main challenges. First, how to consolidate a microkernel system-call API with a hypercall API in such a way that the API remains orthogonal? The answer to this question lies in NOVA's unique IPC interface. Second, how to implement a virtual machine monitor outside the hypervisor without spoiling performance? The Vancouver virtual machine monitor that runs on top NOVA proves that a decomposition at this system level is not only feasible but can yield high performance. Third, being a modern microkernel, NOVA set out to pursue a capability-based security model, which is a challenge on its own.
Up to now, the NOVA developers were most concerned about optimizing and evaluating NOVA for the execution of virtual machines, not so much about running a fine-grained decomposed multi-server operating system. This is where Genode comes into play. With our port of Genode to NOVA, we contribute the workload to evaluate NOVA's kernel API against this use case. We are happy to report that the results so far are overly positive.
At this point, we want to thank the main developers of NOVA Udo Steinberg and Bernhard Kauer for making their exceptional work and documentation publicly available, and for being so responsive to our questions. We also greatly enjoyed the technical discussions we had and look forward to the future evolution of NOVA.
Challenges
From all currently supported base platforms of Genode, the port to NOVA was the most venturesome effort. It is the first platform with kernel support for capabilities and local names. That means no process except the kernel has global knowledge. This raises a number of questions that seem extremely hard to solve at the first sight. For example: There are no global IDs for threads and other kernel objects. So how to address the destination for an IPC message? Or another example: A thread does not know its own identity per se and there is no system call similar to getpid or l4_myself, not even a way to get a pointer to a thread's own user-level thread-control block (UTCB). The UTCB, however, is needed to invoke system calls. So how can a thread obtain its UTCB in order to use system calls? The answers to these questions must be provided by user-level concepts. Fortunately, Genode was designed for a capability kernel right from the beginning so that we already had solutions to most of these questions. In the following, we give a brief summary of the specifics of Genode on NOVA:
-
We maintain our own system-call bindings for NOVA (base-nova/include/nova/) derived from the NOVA specification. We put the bindings under MIT license to encourage their use outside of Genode.
-
Core runs directly as roottask on the NOVA hypervisor. On startup, core maps the complete I/O port range to itself and implements debug output via comport 0.
-
Because NOVA does not allow rootask to have a BSS segment, we need a slightly modified linker script for core (see src/platform/roottask.ld). All other Genode programs use Genode's generic linker script.
-
The Genode Capability type consists of a portal selector expressing the destination of a capability invocation and a global object ID expressing the identity of the object when the capability is specified as an invocation argument. In the latter case, the global ID is needed because of a limitation of the current system-call interface. In the future, we are going to entirely remove the global ID.
-
Thread-local data such as the UTCB pointer is provided by the new thread context management introduced with the Genode release 10.02. It enables each thread to determine its thread-local data using the current stack pointer.
-
NOVA provides threads without time called local execution contexts (EC). Local ECs are intended as server-side RPC handlers. The processing time needed to perform RPC requests is provided by the client during the RPC call. This way, RPC semantics becomes very similar to function call semantics with regard to the accounting of CPU time. Genode already distinguishes normal threads (with CPU time) and server-side RPC handlers (Server_activation) and, therefore, can fully utilize this elegant mechanism without changing the Genode API.
-
On NOVA, there are no IPC send or IPC receive operations. Hence, this part of Genode's IPC framework cannot be implemented on NOVA. However, the corresponding classes Ipc_istream and Ipc_ostream are never used directly but only as building blocks for the actually used Ipc_client and Ipc_server classes. Compared with the other Genode base platforms, Genode's API for synchronous IPC communication maps more directly onto the NOVA system-call interface.
-
The Lock implementation utilizes NOVA's semaphore as a utility to let a thread block in the attempt to get a contended lock. In contrast to the intuitive way of using one kernel semaphore for each user lock, we use only one kernel semaphore per thread and the peer-to-peer wake-up mechanism we introduced in the release 9.08. This has two advantages: First, a lock does not consume a kernel resource, and second, the full semantics of the Genode lock including the cancel-blocking semantics are preserved.
-
NOVA does not support server-side out-of-order processing of RPC requests. This is particularly problematic in three cases: Page-fault handling, signal delivery, and the timer service.
A page-fault handler can receive a page fault request only if the previous page fault has been answered. However, if there is no answer for a page-fault, the page-fault handler has to decide whether to reply with a dummy answer (in this case, the faulter will immediately raise the same page fault again) or block until the page-fault can be resolved. But in the latter case, the page-fault handler cannot handle any other page faults. This is unfeasible if there is only one page-fault handler in the system. Therefore, we instantiate one pager per user thread. This way, we can block and unblock individual threads when faulting.
Another classical use case for out-of-order RPC processing is signal delivery. Each process has a signal-receiver thread that blocks at core's signal service using an RPC call. This way, core can selectively deliver signals by replying to one of these in-flight RPCs with a zero-timeout response (preserving the fire-and-forget signal semantics). On NOVA however, a server cannot have multiple RPCs in flight. Hence, we use a NOVA semaphore shared between core and the signal-receiver thread to wakeup the signal-receiver on the occurrence of a signal. Because a semaphore-up operation does not carry payload, the signal has to perform a non-blocking RPC call to core to pick up the details about the signal. Thanks to Genode's RPC framework, the use of the NOVA semaphore is hidden in NOVA-specific stub code for the signal interface and remains completely transparent at API level.
For the timer service, we currently use one thread per client to avoid the need for out-of-order RPC processing.
-
Because NOVA provides no time source, we use the x86 PIT as user-level time source, similar as on OKL4.
-
On the current version of NOVA, kernel capabilities are delegated using IPC. Genode supports this scheme by being able to marshal Capability objects as RPC message payload. In contrast to all other Genode base platforms where the Capability object is just plain data, the NOVA version must marshal Capability objects such that the kernel translates the sender-local name to the receiver-local name. This special treatment is achieved by overloading the marshalling and unmarshalling operators of Genode's RPC framework. The transfer of capabilities is completely transparent at API level and no modification of existing RPC stub code was needed.
How to explore Genode on NOVA?
The Genode release 10.02 supports the NOVA pre-release version 0.1. You can download the archive here:
- Download NOVA version 0.1
-
https://os.inf.tu-dresden.de/~us15/nova/nova-hypervisor-0.1.tar.bz2
For building NOVA, please refer to the README file contained in the archive. Normally, a simple make in the build/ subdirectory is all you need to get a freshly baked hypervisor binary.
The NOVA platform support for Genode resides in the base-nova/ repository. To create a build directory prepared for compiling Genode for NOVA, you can use the create_builddir tool. From the top-level Genode directory, issue the following command:
./tool/builddir/create_builddir nova_x86 GENODE_DIR=. BUILD_DIR=<dir>
This tool will create a fresh build directory at the location specified as BUILD_DIR. Provided that you have installed the Genode tool chain, you can now build Genode by using make from within the new build directory.
Note that in contrast to most other kernels, the Genode build process does not need to know about the source code of the kernel. This is because Genode maintains its own system-call bindings for this kernel. The bindings reside in base-nova/include/nova/.
NOVA supports multi-boot boot loaders such as GRUB, Pulsar, or gPXE. For example, a GRUB configuration entry for booting the Genode demo scenario with NOVA looks as follows, whereas genode/ is a symbolic link to the bin/ subdirectory of the Genode build directory and the config file is a copy of os/config/demo.
title Genode demo scenario kernel /hypervisor noapic module /genode/core module /genode/init module /config/demo/config module /genode/timer module /genode/ps2_drv module /genode/pci_drv module /genode/vesa_drv module /genode/launchpad module /genode/nitpicker module /genode/liquid_fb module /genode/nitlog module /genode/testnit module /genode/scout
Please note the noapic argument for the NOVA hypervisor. This argument enables the use of ordinary PIC IRQ numbers, as relied on by our current PIT-based timer driver.
Limitations
The current NOVA version of Genode is able to run the complete Genode demo scenario including several device drivers (PIT, PS/2, VESA, PCI) and the GUI. At version 0.1, however, NOVA is not yet complete and misses some features needed to make Genode fully functional. The current limitations are:
-
No real-time priority support: NOVA supports priority-based scheduling but, in the current version, it allows each thread to create scheduling contexts with arbitrary scheduling parameters. This makes it impossible to enforce priority assignment from a central point as facilitated with Genode's priority concept.
-
No multi-processor support: NOVA supports multi-processor CPUs through binding each execution context (ECs) to a particular CPU. Because everyone can create ECs, every process could use multiple CPUs. However, Genode's API devises a more restrictive way of allocating and assigning resources. In short, physical resource usage should be arbitrated by core and the creation of physical ECs should be performed by core only. However, Remote EC creation is not yet supported by NOVA. Even though, multiple CPU can be used with Genode on NOVA right now by using NOVA system calls directly, there is no support at the Genode API level.
-
Missing revoke syscall: NOVA is not be able to revoke memory mappings or destroy kernel objects such as ECs and protection domains. In practice, this means that programs and complete Genode subsystems can be started but not killed. Because virtual addresses cannot be reused, code that relies on unmap will produce errors. This is the case for the dynamic loader or programs that destroy threads at runtime.
Please note that these issues are known and worked on by the NOVA developers. So we expect Genode to become more complete on NOVA soon.
Codezero kernel as new base platform
Codezero is a microkernel primarily targeted to ARM-based embedded systems. It is developed as an open-source project by a British company called B-Labs.
- B-Labs website
The Codezero kernel was first made publicly available in summer 2009. The latest version, documentation, and community resources are available at the project website:
- Codezero project website
As highlighted by the name of the project website, the design of the kernel is closely related to the family of L4 microkernels. In short, the kernel provides a minimalistic set of functionality for managing address spaces, threads, and communication between threads, but leaves complicated policy and device access to user-level components.
To put Codezero in relation to other L4 kernels, here is a quick summary on the most important design aspects as implemented with the version 0.2, and how our port of Genode relates to them:
-
In the line of the original L4 interface, the kernel uses global name spaces for kernel objects such as threads and address spaces.
-
For the interaction between a user thread and the kernel, the concept of user-level thread-control blocks (UTCB) is used. A UTCB is a small thread-specific region in the thread's virtual address space, which is always mapped. The access to the UTCB can never raise a page fault, which makes it perfect for the kernel to access system-call arguments, in particular IPC payload copied from/to user threads. In contrast to other L4 kernels, the location of UTCBs within the virtual address space is managed by the user land.
On Genode, core keeps track of the UTCB locations for all user threads. This way, the physical backing store for the UTCB can be properly accounted to the corresponding protection domain.
-
The kernel provides three kinds of synchronous inter-process communication (IPC): Short IPC carries payload in CPU registers only. Full IPC copies message payload via the UTCBs of the communicating parties. Extended IPC transfers a variable-sized message from/to arbitrary locations of the sender/receiver address spaces. During an extended IPC, page faults may occur.
Genode solely relies on extended IPC, leaving the other IPC mechanisms to future optimizations.
-
The scheduling of threads is based on hard priorities. Threads with the same priority are executed in a round-robin fashion. The kernel supports time-slice-based preemption.
Genode does not support Codezero priorities yet.
-
The original L4 interface leaves the question on how to manage and account kernel resources such as the memory used for page tables unanswered. Codezero makes the accounting of such resources explicit, enables the user-land to manage them in a responsible way, and prevent kernel-resource denial-of-service problems.
-
In contrast to the original L4.v2 and L4.x0 interfaces, the kernel provides no time source in the form of IPC timeouts to the user land. A time source must be provided by a user-space timer driver. Genode employs such a timer services on all platforms so that it is not constricted by this limitation.
In several ways, Codezero goes beyond the known L4 interfaces. The most noticeable addition is the support of so-called containers. A container is similar to a virtual machine. It is an execution environment that holds a set of physical resources such as RAM and devices. The number of containers and the physical resources assigned to them are static and have to be defined at build time. The code executed inside a container can roughly be classified by two categories. First, there are static programs that require strong isolation from the rest of the system but no classical operating-system infrastructure, for example special-purpose telecommunication stacks or cryptographic functionality of an embedded device. Second, there are kernel-like workloads, which use the L4 interface to substructure the container into address spaces, for example a paravirtualized Linux kernel that uses Codezero address spaces to protect Linux processes. Genode runs inside a container and facilitates Codezero's L4 interface to implement its multi-server architecture.
The second major addition is the use of a quite interesting flavor of a capability concept to manage the authorization of processes to access system resources and system calls. In contrast to most current approaches, Codezero does not attempt to localize the naming of physical objects such as address-space IDs and thread ID. So a capability is not referred to via a local name but a global name. However, for delegating authorization throughout the system, the capability approach is employed. A process that possesses a capability to an object can deal with the object. It can further delegate this access right to another party (to which it holds a capability). In a way, this approach keeps the kernel interface true to the original L4 interface but provides a much stronger concept for access control. However, it is important to point out that the problem of ambient authority is not (yet) addressed by this concept. If a capability is not used directly but specified as an argument to a remote service, this argument is passed as a plain value not protected by the kernel. Because the identity of the referenced object can be faked by the client, the server has to check the plausibility of the argument. For the server, however, this check is difficult/impossible because it has no way to know whether the client actually possesses the capability it is talking about.
The current port of Genode to Codezero does not make use of the capability concept for fine-grained communication control, yet. As with the other L4 kernels, each object is identified by a unique ID allocated by a core service. There is no mechanism in place to prevent faked object IDs.
- Thanks
We want to thank the main developer of Codezero Bahadir Balban for his great responsiveness to our feature requests and questions. Without his help, the port would have taken much more effort. We hope that our framework will be of value to the Codezero community.
Using Genode with Codezero
The port of Genode is known to work with the devel branch of Codezero version 0.2 as of 2010-02-19.
To download the Codezero source code from the official source-code repository, you can use the following commands:
git clone git://git.l4dev.org/codezero.git git checkout -b devel --track origin/devel
In addition to downloading the source code, you will need to apply the small patch base-codezero/lcd.patch to the Codezero kernel to enable the device support for the LCD display. Go to the codezero.git/ directory and issue:
patch -p1 < <genode-dir>/base-codezero/lcd.patch
For a quick start with Codezero, please follow the "Getting Started with the Codezero Development" guide, in particular the installation of the tool chain:
- Getting started with Codezero
The following steps guide you through building and starting Genode on Codezero using the Versatilepb platform as emulated by Qemu.
-
Create a Genode build directory for the Codezero/Versatilepb platform. Go to the Genode directory and use the following command where <build-dir> is the designated location of the new Genode build directory and <codezero-src-dir> is the codezero.git/ directory with the Codezero source tree, both specified as absolute directories.
./tool/builddir/create_builddir codezero_versatilepb \ GENODE_DIR=. \ BUILD_DIR=<genode-build-dir> \ L4_DIR=<codezero-src-dir>With the build directory created, Genode targets can immediately be compiled for Codezero. For a quick test, go to the new build directory and issue:
make init
In addition to being a Genode build directory, the directory is already prepared to be used as Codezero container. In particular, it holds a SConstruct file that will be called by the Codezero build system. In this file, you will find the list of Genode targets to be automatically built when executing the Codezero build process. Depending on your work flow, you may need to adapt this file.
-
To import the Genode container into the Codezero configuration system, go to the codezero.git/ directory and use the following command:
./scripts/baremetal/baremetal_add_container.py \ -a -i Genode -s <genode-build-dir> -
Now, we can add and configure a new instance of this container via the Codezero configuration system:
./configure.py
Using the interactive configuration tool, select to use a single container and set up the following values for this bare-metal container, choose a sensible Container Name (e.g., genode0) and select the Genode entry in the Baremetal Project menu.
- Default pager parameters
0x40000 Pager LMA 0x100000 Pager VMA
These values are important because they are currently hard-wired in the linker script used by Genode. If you need to adopt these values, make sure to also update the Genode linker script located at base-codezero/src/platform/genode.ld.
- Physical Memory Regions
1 Number of Physical Regions 0x40000 Physical Region 0 Start Address 0x4000000 Physical Region 0 End Address
We only use 64MB of memory. The physical memory between 0 and 0x40000 is used by the kernel.
- Virtual Memory Regions
1 Number of Virtual Regions 0x0 Virtual Region 0 Start Address 0x50000000 Virtual Region 0 End Address
It is important to choose the end address such that the virtual memory covers the thread context area. The context area is defined at base/include/base/thread.h.
- Container Devices (Capabilities)
Enable the LCD display in the CLCD Menu.
The configuration system will copy the Genode container template to codezero.git/conts/genode0. Hence, if you need to adjust the container's SConscript file, you need to edit codezero.git/conts/genode.0/SConscript. The original Genode build directory is only used as template when creating a new Codezero container but it will never be looked at by the Codezero build system.
-
After completing the configuration, it is time to build both Codezero and Genode. Thanks to the SConscript file in the Genode container, the Genode build process is executed automatically:
./build.py
You will find the end result of the build process at
./build/final.elf
-
Now you can try out Genode on Qemu:
qemu-system-arm -s -kernel build/final.elf \ -serial stdio -m 128 -M versatilepb &The default configuration starts the nitpicker GUI server and the launchpad application. The versatilepb platform driver is quite limited. It does support the LCD display as emulated by Qemu but no user input, yet.
Limitations
At the current stage, the Genode version for Codezero is primarily geared towards the developers of Codezero as a workload to stress their kernel. It still has a number of limitations that would affect the real-world use:
-
Because the only platform supported out of the box by the official Codezero source tree is the ARM-based Versatilebp board, Genode is currently tied to this hardware platform. When Codezero moves beyond this particular platform, we will add a modular concept for platform support packages to Genode.
-
The current timer driver at os/src/drivers/timer/codezero/ is a dummy driver that just yields the CPU time instead of blocking. It is not suitable as time source.
-
The versatilepb platform driver at os/src/drivers/platform/versatilepb/ does only support the LCD display as provided by Qemu but it was not tested on real hardware. Because Codezero does not yet allow the assignment of the Versatilepb PS/2 controller to a container, the current user-input driver is just a dummy.
-
The lock implementation is based on a simple spinlock using an atomic compare-exchange operation, which is implemented via Codezero's kernel mutex. The lock works and is safe but it has a number of drawbacks with regard to fairness, efficiency, and its interaction with scheduling.
-
Core's IRQ service is not yet implemented because the IRQ-handling interface of Codezero is still in flux.
-
Because we compile Genode with the same tool chain (Codesourcery ARM tool chain) as used for Codezero, there are still subtle differences in the linker scripts, making Genode's dynamic linker not yet functional on Codezero.
-
Even though Codezero provides priority-based scheduling, Genode does not allow assigning priorities to Codezero processes, yet.
-
Currently, all Genode boot modules are linked as binary data against core, which is then loaded as single image into a container. For this reason, core must be build after all binaries. This solution is far from being convenient because changing the list of boot modules requires changes in core's platform.cc and target.mk file.
New thread-context management
With the current release, we introduced a new stack management concept that is now consistently used on all Genode base platforms. Because the new concept does not only cover the stack allocation but also other thread-specific context information, we speak of thread-context management. The stack of a Genode thread used to be a member of the Thread object with its size specified as template argument. This stack-allocation scheme was chosen because it was easy to implement on all base platforms and is straight-forward to use. But there are two problems with this approach.
First, the implementation of thread-local storage (TLS) is either platform dependent or costly. There are kernels with support for TLS, mostly by the means of a special register that holds a pointer to a thread-local data structure (e.g., the UTCB pointer). But using such a facility implicates platform-specific code on Genode's side. For kernels with no TLS support, we introduced a unified TLS concept that registers stacks alongside with thread-local data at a thread registry. To access the TLS of a thread, this thread registry can be queried with the current stack pointer of a caller. This query, however, is costly because it traverses a data structure. Up to now, we accepted these costs because native Genode code did not use TLS. TLS was only needed for code ported from the Linux kernel. However, with NOVA, there is now a kernel that requires the user land to provide a fast TLS mechanism to look up the current thread's UTCB in order to perform system calls. On this kernel, a fast TLS mechanism is important.
The second disadvantage of the original stack allocation scheme is critical to all base platforms: Stack overflows could not be detected. For each stack, the developer had to specify a stack size. A good estimation for this value is hard, in particular when calling functions of library code with unknown stack usage patterns. If chosen too small, the stack could overflow, corrupting the data surrounding the Thread object. Such errors are extremely cumbersome to detect. If chosen too large, memory gets wasted.
For storing thread-specific data (called thread context) such as the stack and thread-local data, we have now introduced a dedicated portion of the virtual address space. This portion is called thread-context area. Within the thread-context area, each thread has a fixed-sized slot, a thread context. The layout of each thread context looks as follows
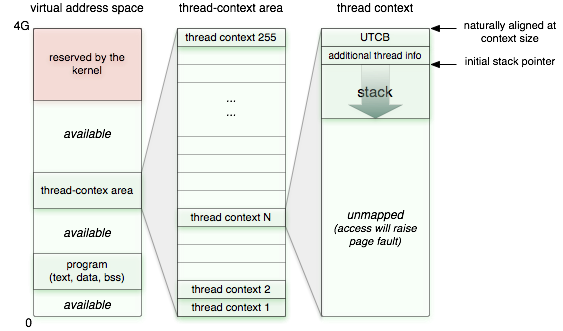
|
On some platforms, a user-level thread-control block (UTCB) area contains data shared between the user-level thread and the kernel. It is typically used for transferring IPC message payload or for system-call arguments. The additional context members are a reference to the corresponding Thread_base object and the name of the thread.
The thread context is a virtual memory area, initially not backed by real memory. When a new thread is created, an empty thread context gets assigned to the new thread and populated with memory pages for the stack and the additional context members. Note that this memory is allocated from the RAM session of the process environment and gets not accounted for when using the sizeof() operand on a Thread_base object.
This way, stack overflows are immediately detected because the corresponding thread produces a page fault within the thread-context area. Data corruption can never occur.
We implemented this concept for all base platforms and thereby made the stack-overflow protection and the fast TLS feature available to all platforms. On L4ka::Pistachio, OKL4, L4/Fiasco, Codezero, and NOVA, the thread-context area is implemented as a managed dataspace. This ensures that the unused virtual memory of the sparsely populated thread-context area is never selected for attaching regular dataspaces into the process' address space. On Linux, the thread-context area is implemented via a fixed offset added to the local address for the mmap system call. So on this platform, there is no protection in place to prevent regular dataspaces from being attached within the thread-context area.
Please note that in contrast to the original Thread object, which contained the stack, the new version does not account for the memory consumed by the stack when using the sizeof() operator. This has to be considered for multi-threaded servers that want to account client-specific threads to the memory donated by the corresponding client.
Real-time priorities
There are two application areas generally regarded as predestined for microkernels, high security and real time. Whereas the development of Genode was primarily focused on the former application area so far, we observe growing interest in using the framework for soft real-time applications, in particular multi-media workload. Most of Genode's supported base platforms already provide some way of real-time scheduling support, hard priorities with round-robin scheduling of threads with the same priority being the most widely used scheduling scheme. What has been missing until now was a way to access these facilities through Genode's API or configuration interfaces. We deferred the introduction for such interfaces for a very good reason: It is hard to get right. Even though priority-based scheduling is generally well understood, the combination with dynamic workload where differently prioritized processes are started and deleted at runtime and interact with each other is extremely hard to manage. At least, this had been our experience with building complex scenarios with the Dresden real-time operating system (DROPS). Combined with optimizations such as time-slice donating IPC calls, the behaviour of complex scenarios tended to become indeterministic and hardly possible to capture.
Genode imposes an additional requirement onto all its interfaces. They have to support the recursive structure of the system. Only if any subsystem of processes is consistent on its own, it is possible to replicate it at an arbitrary location within Genode's process tree. Assigning global priorities to single processes, however, would break this condition. For example, non-related subsystems could interfere with each other if both used the same range of priorities for priority-based synchronization within the respective subsystem. If executed alone, each of those subsystems would run perfectly but integrated into one setup, they would interfere with each other, yielding unpredictable results. We have now found a way to manage real-time priorities such that the recursive nature Genode is not only preserved but actually put to good use.
Harmonic priority-range subdivision
We call Genode's priority management concept harmonic priority-range subdivision. Priorities are not assigned to activities as global values but they can be virtualized at each node in Genode's process tree. At startup time, core assigns the right to use the complete range of priorities to the init process. Init is free to assign those priorities to any of the CPU sessions it creates at core, in particular to the CPU sessions it creates on behalf its children and their grandchildren. Init, however, neither knows nor is it interested in the structure of its child subsystems. It only wants to make sure that one subsystem is prioritized over another. For this reason, it uses the most significant bits of the priority range to express its policy but leaves the lesser significant bits to be defined by the respective subsystems. For example, if init wants to enforce that one subsystem has a higher priority than all others, it would need to distinguish two priorities. For each CPU-session request originating from one of its clients, it would diminish the supplied priority argument by shifting the argument by one bit to the right and replacing the most significant bit with its own policy. Effectively, init divides its own range of priorities into two subranges. Both subranges, in turn, can be managed the same way by the respective child. The concept works recursively.
Implementation
The implementation consists of two parts. First, there is the actual management implemented as part of the parent protocol. For each CPU session request, the parent evaluates the priority argument and supplements its own policy. At this management level, a logical priority range of 0...2^16 is used to pass the policy arguments from child to parent. A lower value represents a higher priority. The second part is the platform-specific code in core that translates priority arguments into kernel priorities and assigns them to physical threads. Because the typical resolution for priority values is lower than 2^16, this quantization can lead to the loss of the lower-significant priority bits. In this case, differently prioritized CPU sessions can end up using the same physical priority. For this reason, we recommend to not use priorities for synchronization purposes.
Usage
The assignment of priorities to subsystems is done via two additional tags in init's config file. The <priolevels> tag specifies how many priority levels are distinguished by the init instance. The value must be a power of two. Each <start> node can contain an optional <priority> declaration, which holds a value between -priolevels + 1 and 0. This way, priorities can only be lowered, never alleviated above init's priority. If no <priority> tag is specified, the default value of 0 (init's own priority) is used. For an example, here is a config file starting several nested instances of the init process using different priority subranges.
<config>
<!--
divides priority range 1..128 into
65..128 (prio 0)
1..64 (prio -1)
-->
<priolevels>2</priolevels>
<start>
<filename>init</filename>
<priority>0</priority>
<ram_quota>5M</ram_quota>
<config>
<!--
divides priority range 65..128 into
113..128 (prio 0)
97..112 (prio -1)
81..96 (prio -2)
65..80 (prio -3)
-->
<priolevels>4</priolevels>
<start>
<filename>init</filename>
<!-- results in platform priority 112 -->
<priority>-1</priority>
<ram_quota>512K</ram_quota>
</start>
<start>
<filename>init</filename>
<!-- results in platform priority 96 -->
<priority>-2</priority>
<ram_quota>2M</ram_quota>
<config>
<start>
<filename>init</filename>
<ram_quota>768K</ram_quota>
</start>
</config>
</start>
</config>
</start>
<start>
<filename>init</filename>
<!-- results in platform priority 64 -->
<priority>-1</priority>
<ram_quota>6M</ram_quota>
<config></config>
</start>
</config>
On kernels that support priorities and where priority 128 is used as priority limit (this is the case for OKL4 and Pistachio), this configuration should result in the following assignments of physical priorities to process-tree nodes:
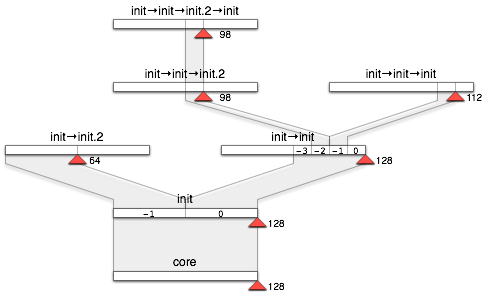
|
The red marker shows the resulting priority of the corresponding process.
With Genode 10.02, we implemented the described concept for the OKL4 and L4ka::Pistachio base platforms first. On both platforms, a priority range of 0 to 128 is used.
On L4/Fiasco, we were not yet able to apply this concept because on this kernel, the used lock implementation is based on a yielding spinlock. If a thread at a high priority would attempt to acquire a contended lock, it would infinitely yield the CPU to itself, letting all other threads in the system starve. In order to make real-time priorities usable on L4/Fiasco we would need to change the lock first.
Base framework
Read-only dataspaces
Until now, we have not handled ROM dataspaces any different from RAM dataspaces in core except for their predefined content. With the Genode workload becoming more complex, ROM files tend to get shared between different processes and need protection. Now, dataspaces of ROM modules are always mapped read-only.
Enabled the use of super pages by default
Since release 9.08, we support super pages as an experimental feature. Now, this feature is enabled by default on L4/Fiasco, L4ka::Pistachio, and NOVA.
Enabled managed dataspaces by default
We originally introduced managed dataspaces with the release 8.11. However, because we had no pressing use cases, it remained a experimental feature until now. The new thread-context management introduced with this release prompted us to promote managed dataspaces to become a regular feature. Originally there was one problem holding us back from this decision, which was the handling of cyclic references between nested dataspaces. However, we do now simply limit the number of nesting levels to a fixed value.
Streamlined server framework
We removed the add_activation() functionality from the server and pager libraries because on all platforms server activations and entry points have a one-to-one relationship. This API was originally intended to support platforms that are able to trigger one of many worker threads via a single entry point. This was envisioned by an early design of NOVA. However, no kernel (including NOVA) supports such a feature as of today.
Furthermore, we added a dedicated Pager_capability type. On most platforms, a pager is simply a thread. So using a Thread_capability as type for the Pager_capability was sufficient. On NOVA, however, a pager is not necessarily a thread. So we need to reflect this difference in the types.
PD session interface
To support capability kernels with support for local names, it is not sufficient to provide the parent capability to a new child by passing a plain data argument to the new child during ELF loading anymore. We also need to tell the kernel about the delegated right of the child to talk to its parent. This is achieved using the new assign_parent function of the PD session interface. This function allows the creator of a new process to register the parent capability.
Singleton services
There are services, in particular device drivers, that support only one session at a time. This characteristic was not easy to express in the framework. Consequently, such services tended to handle the case of a second session request inconsistently. We have now enhanced the Root_component template with a policy parameter to Root_component that allows the specification of a session-creation policy. The most important policy is whether a service can have a single or multiple clients. See the improved template...
Out-of-order RPC replies
In the previous release, we introduced a transitional API for supporting out-of-order RPC replies. This API is currently used by the timer and signal services but is declared deprecated. The original implementation used a blocking send operation to deliver replies, which is not desired and can cause infinite blocking times in the presence of misbehaving clients. Therefore, we changed the implementation to send explicit replies with no timeout. Thanks to Frank Kaiser for pointing out this issue.
Operating-system services and libraries
Python scripting
We have ported a minimal Python 2.6.4 interpreter to Genode. The port is provided with the libports repository. It is based on the official Python code available from the website:
- Python website
To fetch the upstream Python source code, call make prepare from within the libports directory. To include Python in your build process, add libports to your build.conf file.
A test program for the script interpreter is provided at libports/src/test/python. When building this test program, a shared library python.lib.so will be generated. A sample Genode configuration (config_sample) file that starts a Python script can be found within this directory. If you are not using Linux as a Genode base platform, do not forget to add python.lib.so to your boot module list.
We regard this initial port as the first step to make a complete Python runtime. At the current stage, there is support for Rom_session Python scripts to serve basic scripting needs, currently geared towards automated testing. Modules and standard modules are not yet supported.
Plugin-interface for the C library
The recent addition of the lwIP stack to Genode stimulated our need to make the C runtime extensible by providing multiple back ends, lwIP being one of them. Therefore, we introduced a libc-internal plugin interface, which is able to dispatch libc calls to one of potentially many plugins. The plugin interface covers the most used file operations and a few selected networking functions. By default, if no plugin is used, those functions point to dummy implementations. If however, a plugin is linked against a libc-using program, calls to open or socket are directed to the registered plugins, resulting in plugin-specific file handles. File operations on such a file handle are then dispatched by the corresponding plugin.
The first functional plugin is the support for lwIP. This makes it possible to compile BSD-socket based network code to use lwIP on Genode. Just add the following declaration in your target.mk:
LIBS += libc libc_lwip lwip
The libc library is the generic C runtime, lwip is the raw lwIP stack, and libc_lwip is the lwip plugin for the C runtime - the glue between lwip and libc. The initialization of lwip is not yet part of the lwip plugin.
- Limitations
We expand the libc-plugin interface on a per case basis. Please refer to libc/include/libc-plugin/plugin.h to obtain the list of currently supported functions. Please note that select is not yet supported.
ARM architecture support for the C library
We enhanced our port of the FreeBSD libc with support for the ARM architecture. In the ARM version, the following files are excluded:
- libm
-
e_acosl.c, e_asinl.c, e_atan2l.c, e_hypotl.c, s_atanl.c, s_cosl.c, s_frexpl.c, s_nextafterl.c, s_nexttoward.c, s_rintl.c, s_scalbnl.c', s_sinl.c, s_tanl.c, s_fmal.c,
- libc-gen
-
setjmp.S
Atomic operation on ARM are not supported. Although these operations are defined in machine/atomic.h, their original FreeBSD implementations are not functional because we do not emulate the required FreeBSD environment (see: sysarch.h). However, these functions are not a regular part of the libc anyway and are not referenced from any other libc code.
Light-weight IP stack
After introducing LwIP support with our last release, we stabilized the port and combined it with our libc implementation. Moreover, we upgraded the lwIP library to the latest stable version 1.3.2. For convenience reasons, we added initialization code, setting up the LwIP stack, the NIC session back end, and optionally DHCP.
The example programs http_srv and loopback within the libports repository show how to use the LwIP stack directly or as a plugin with the libc. The first one makes direct use of the LwIP library and demonstrates how to deal with the new initialization routine, to setup the session to the NIC driver and to request an IP address via DHCP. The second example doesn't use the socket interface of the LwIP library directly but uses the libc variant instead. It doesn't initialize the NIC session back end but uses the loopback device provided by the LwIP library itself.
Device-driver environment kit
The basis for Genode's legacy driver emulation environment was granted some maintenance. DDE kit now utilizes the thread registry and is able to adopt alien threads. This unimpressive feature permits the execution of driver code directly from server activations, i.e., adds support for single-threaded drivers.
Dynamic linker
We added dynamic linking support for OKL4 on the ARM architecture. Because of the tool chain used on this platform, we had to revisit our linker scripts (one warning is left because of gc-sections) and removed the dependency on gcc builtin functions (with the exception of alloca).
To ease debugging on Linux, we revised the handling of registrations of libraries and dynamic binaries, and thereby, made gdb debugging of dynamically linked programs possible.
Furthermore, we prepared the future support for the dl API (dlopen, dlsym etc.) calls by enabling the linker to register exported linker symbols at startup. This is achieved by emulating .hash, .dynsym, and .dynstr sections within the linker object.
Misc
-
Prevent running over the XML data on sub node identification. This change fixes a problem with parsing the config file on OKL4.
-
C Runtime: Disable definition of pthread_cancel symbol because it collides with a weak implementation provided (and relied on) by the C++ support library.
Device drivers
PIT timer driver
We use the x86 Programmable Interval Timer (PIT) on kernels that provide no time source via their kernel APIs, i.e., OKL4 and NOVA.
Up to now, the accuracy of the timer implementation was not a big concern because we wanted to satisfy the use cases of blocking for a short amount of time (ca. 10ms) as needed by many periodic processes such as interactive GUI applications, DDE device drivers, and the OKLinux timer loop. Achieving exact wake-up times with a user-level timing service that get preemptively scheduled alongside an unknown number of other threads is impossible anyway. However, with the introduction of real-time priorities in the current release, real-time workload and the accuracy of the timer driver becomes important. For this reasons we improved the timer implementation.
-
Corrected programming of one-shot timer IRQs. In the function for assigning the next timeout, the specified argument was not taken over to the corresponding member variable. This way, the timer implementation was not operating in one-shot mode but it periodically triggered at a high rate. This change should take off load from the CPU.
-
Replaced counter-latch command with read-back in PIT timer. We use the PIT status byte to detect counter wrap arounds and adjust our tick count accordingly. This fixes problems with long single timeouts.
Thanks to Frank Kaiser for investigating these timer-accuracy issues and providing us with suggestions to fix them.
NIC driver for Linux
Genode provides the NIC session interface and a DDE Linux 2.6 based driver for AMD PCnet32 devices since release 9.11. The NIC driver adds networking support for all Genode base platforms except Linux. With the current release we filled that gap with the TAP-based nic_drv. The driver itself accesses /dev/net/tun for tap0 and needs no super-user privileges. Therefore, the device has to be configured prior to running Genode like the following.
sudo tunctl -u $$USER -t tap0 sudo ip link set tap0 up sudo ip address add 10.0.0.1/24 brd + dev tap0
Give it a try with the lwIP example scenario. Please note that lwIP is configured for DHCP and does not assign a static IP configuration to its end of the wire. Hence, you should run a DHCP server on tap0, e.g.
sudo /usr/sbin/dhcpd3 -d -f -cf /tmp/dhcpd.conf \
-pf /tmp/dhcpd.pid -lf /tmp/dhcpd.lease tap0
An example dhcpd.conf may look like
subnet 10.0.0.0 netmask 255.255.255.0 {
range 10.0.0.16 10.0.0.31;
}
The DHCP server's log will show you that the driver fakes an ethernet NIC with the MAC address 02-00-00-00-00-01.
VESA driver
Our VESA driver used to set a default resolution of 1024x768 at 16 bit color depth, which could be changed by specifying session arguments. However, most of the time, clients are able to adapt itself to the framebuffer resolution and do not want to implement the policy of defining the screen mode. Now we made the VESA driver configurable, taking the burden of choosing a screen mode from the client. A client can still request a particular resolution but for the common case, it is policy free.
If no configuration is supplied, the driver sets up a resolution of 1024x768 at 16 bit color depth. This behaviour can be overridden by supplying the following arguments via Genode's config mechanism:
<config> <!-- initial screen width --> <width>1024</width> <!-- initial screen height --> <height>768</height> <!-- initial color depth (bits per pixel) --> <depth>16</depth> </config>
Note that only VESA modes but no arbitrary combination of values are supported. To find out which graphics modes exist on your platform, you might use the vbeprobe command of the GRUB boot loader. Also, the driver will print a list of supported modes if the specified values are invalid.
Paravirtualized Linux refinements
The para-virtualized Linux port introduced in Genode Release 9.11 has been refined, especially the block driver providing a root file system for Linux has been completely reworked. Also the configuration facilities changed a bit. Moreover, few problems that occurred when using multiple Linux instances, or when using one instance under heavy load have been fixed. At this point, we like to thank Sven Fülster for providing information and a fix for a bug triggered by a race condition.
- Repository structure
We rearranged the structure of the oklinux repository. The downloaded archive and the original OKLinux code are now stored under download and respectively contrib analog to the libports repository structure.
- Rom-file block driver
The block driver using a ramdisk as backing store as contained in the original OKLinux port has been replaced by a new implementation that uses a dataspace provided by the ROM session interface to provide a read-only block driver.
The read-only block driver can be used together with UnionFS (stackable file system) or the Cowloop driver (copy-on-write block device) for Linux to obtain a writeable root-file system, like it is done in many Linux Live-CDs.
To use the new rom-file block driver you first need to specify what file to use as block device. This can be done by adding a rom_file section in the XML configuration of your Linux instance:
<config>
<rom_file>rootfs.img</rom_file>
</config>
Of course, you need to add this file to your list of boot modules.
The block device is named gda within the Linux Kernel (e.g., take a look at /proc/partitions). When using it as root-file system, you might specify the following in your configuration:
<config>
<commandline>root=/dev/gda1</commandline>
<rom_file>rootfs.img</rom_file>
</config>
Assuming the rom-file contains a valid partition table and the root file system is located in the first partition.
Distribution changes
Starting with the release 10.02, we will no longer distribute our slightly customized version of the L4/Fiasco kernel together with the official Genode distribution but instead will provide this kernel as a separate archive. Our original intention with packaging L4/Fiasco with Genode was to give newcomers a convenient way to start working with Genode on a real microkernel without the need to download the whole TUDOS source tree where the main-line development of L4/Fiasco is hosted. In the meanwhile, the number of supported base platforms greatly increased to 6 different kernels. There are now plenty of opportunities to get started with real microkernels so that the special case of hosting L4/Fiasco with Genode is no longer justified. We want to leave it up to you to pick the kernel that suits your needs best, and provide assistance via our wiki and mailing list.