
Release notes for the Genode OS Framework 14.08
The overall theme of version 14.08 is the introduction of a new scalable GUI architecture that takes security as the most fundamental premise. It is unique in the way that the security of graphical applications and thereby the privacy of the user depends on only a few components of very little complexity. We strive for low complexity to reduce the likelihood for bugs and thereby the attack surface of the system. When using a secure microkernel such as NOVA, Genode's trusted computing base for graphical applications is orders of magnitude less complex compared to contemporary operating systems. To illustrate the rigidity of this claim, the security-sensitive parts of the GUI stack do not even depend on a C runtime. With the current release, we maintain our focus on security while taking the scalability of the GUI architecture to a level that meets the expectations of general-purpose OSes. Thanks to its component-based design, the new GUI stack provides a great deal of flexibility with respect to its behaviour and style. Section New GUI architecture provides the rationale behind the development, the big picture of the architecture, and details about the current implementation.
Besides the GUI-related improvements, the release comes with a new port of the OpenVPN client as Genode component (Section New port of OpenVPN), pluggable VFS file systems (Section Pluggable VFS file systems), a vastly improved integration of Qt5 (Section Integration of Qt5), and an upgrade of the Linux device-driver environment (DDE Linux) to version 3.14.5 (Section DDE Linux updated to version 3.14.5). On the NOVA platform, both supported virtualization solutions received attention. Guests running in VirtualBox have become able to use networking, and the Seoul virtual-machine monitor got improved to support SMP. Furthermore, the development of our custom base-hw kernel continued at a high pace. Its performance could be greatly improved and its source structure got overhauled to make it more coherent and approachable. The latter point is important as we see the growing popularity of base-hw among the users of the framework. Section Execution on bare hardware (base-hw) covers the changes of this base platform in detail.
New GUI architecture
Up until now, Genode's GUI stack has been pretty rigid with the nitpicker GUI server being the centerpiece of the picture. Nitpicker is a low-level display multiplexer that allows multiple applications to share the physical screen and input devices in a secure way. It is designed such that no application can eavesdrop or influence another application via the GUI server, and user input is protected from snooping. The design applies microkernel-construction principles to the GUI level. Because the GUI server is in a similar position as a kernel in that it provides services shared by different clients that may distrust each other, it must be of low complexity to keep the likelihood for bugs (and thereby its attack surface) as low as possible. It must contain only those mechanisms that are crucial for a GUI to operate and impossible to implement outside of the GUI server. Following this principle, nitpicker lacks many features that are universally expected from a GUI server such as window decorations, window management, widgets, keyboard-layout management, or conversion between color spaces. It provides merely three mechanisms: A way for a client to make pixel buffers visible on screen using so-called views, a way for the user to direct user input to a specific application, and a way for the user to reveal the identity of the visible applications to counter Trojan Horses (the feature is dubbed "X-ray mode").
Over the years, nitpicker served us well for covering relatively static special-purpose system scenarios. But when considering Genode as a general-purpose OS, it goes without saying that nitpicker alone does not make a desktop environment. The functionality stripped off the GUI server must be implemented somewhere else. With the current release, we took the opportunity to design a GUI architecture that maintains the low complexity of the status quo for static system scenarios while also scaling to GUI features expected from general-purpose computing such as dynamics, window management, and a great deal of customizability.
When we set out to design the GUI architecture, we took the following requirements into account.
- Security
-
First and foremost, we need to maintain the strong security properties provided by nitpicker. GUI applications must be isolated by default. No application must be able to peek at another application. Even the mere existence of an application should be hidden from other applications. If we need to introduce new components that are shared among multiple applications, those components must be kept as low-complex as possible to keep their attack surface small. User input must be made available only to the single application that the user talks to. If we need to add complex code such as graphics-heavy libraries to the picture, we have to contain it in sandboxes with no critical privileges.
- Flexibility
-
The architecture should principally support a wide range of user-interface paradigms such as floating windows, tabbed and tiled window management, or plain virtual consoles.
- Customizability
-
Everyone has a different taste when it comes to the look of GUIs. However, advanced presentation often comes at the expense of additional complexity. The architecture should allow us to largely customize all visual aspects of the GUI such as the way the mouse pointer looks like and how it responds to a hovered context, how windows are equipped with window elements, or the functionality of panels and on-screen displays.
- Performance
-
Even though we rely on software rendering at the time being and cannot expect miracles when it comes to graphics performance, we want the GUI to perform well enough to be enjoyable, even on low-end platforms like the Raspberry Pi.
- Dynamics
-
The GUI should adapt itself at runtime, i.e., respond to configuration changes on the fly and handle changed screen resolutions.
- Composability
-
In line with Unix's philosophy, we aspire the creation of complementary components that implement orthogonal functionality such that they can be combined in many different ways. To optimize for composability, we have to avoid introducing new interfaces because a new interface cannot be combined with existing components per se. Rather than introducing additional interfaces and abstractions, we should try to make the existing interfaces more flexible. Finally, we don't want to re-invent the wheel. With composability, we also refer to the sandboxed re-use of existing (and often highly complex) software such as Qt5.
Design
With the considerations above in mind, we came up with the following overall picture.
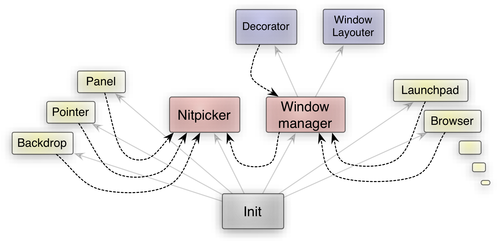
|
|
High-level overview of the components of the GUI stack
|
The thin arrows denote parent-child relationships. The init process starts nitpicker, the window manager, and the yellow applications (the figure omits other components such as device drivers for brevity). The dotted arrows represent the use of nitpicker sessions where each pointed-to component implements the server side of the nitpicker interface. Let us have brief look at the roles of the individual components.
The nitpicker GUI server multiplexes the physical input and output devices among multiple clients. Examples of such clients are depicted on the left side. I.e., the program that provides the backdrop image is connected directly to nitpicker. As is, nitpicker can still be used stand-alone to build static scenarios at minimal complexity.
The window manager is a nitpicker client that provides an alternative implementation of the nitpicker interface. Because it is compatible to the real nitpicker at the interface level, a client cannot decide whether it talks to the real nitpicker or to the window manager. The presence of the window manager is transparent to the client. In contrast to the real nitpicker server, the window manager applies dynamic window management to the views created by its clients. The term "dynamic window management" may refer to vastly different concepts (floating windows vs. full-screen apps vs. tiled and tabbed window management), styles (theming, shadows, location of window handles), and ways of interaction (mouse, touch, keyboard). A single implementation to rule them all would certainly become extremely complex. However, since the window manager is shared by mutually distrusting applications, we strive to avoid complexity within this component to mitigate the chance for security exploits. For this reason, the window manager does not implement the complex window management and decoration by itself but delegates those tasks to two sandboxed child processes, namely the window layouter and the decorator. The window manager merely orchestrates the inter-relationship between GUI applications, the decorator, the window layouter, and the real nitpicker GUI server but it is free from policy. Hence, it can remain simple even when the GUI features get more sophisticated.
The window layouter receives a list of windows (along with their size constraints), the user input that refers to window decorations, and the information about the currently hovered window element. In turn, it produces a data model that describes a window layout. Put shortly, it solely implements the behaviour of the window manager. It does neither see user input that refers to one of the applications nor can it access any pixels produced by the applications. It does not even know the location of window handles on screen. Even in the event that a highly sophisticated window layouter may become complex and bug-ridden, such bugs could not compromise the privacy of the user.
The decorator takes the data model of the window layout as produced by the window layouter and the current pointer position when it points to a window decoration. Based on this information, it draws window decorations using a virtualized nitpicker session provided by the window manager. It is sandboxed in a similar way as the window layouter so that a bug in the decorator cannot put the privacy of the user at risk. In addition to drawing window decorations, the decorator produces a data model that contains information about the currently hovered window element. This model is fed to the layouter. Thanks to this design, only the decorator knows the location and look of window elements. By replacing the decorator with an alternative implementation, the visual style can be freely customized.
Implementation
The implementation of the new architecture consists of a largely revisited interface of the nitpicker GUI server, the new window manager, and example implementations of a window layouter and decorator. Furthermore, it comes with several new or revised supplemental components such as a pointer, status bar, backdrop, and nit_fb.
The window manager is located at gems/src/server/wm. It consists of less than 2000 lines of code and is unlikely to grow much in the future. Similar to nitpicker, it does not depend on a C runtime but only the naked Genode API. The low complexity of this critical component makes us very confident that we will be able to maintain strong security at the GUI level.
An example of a decorator is provided at gems/src/app/decorator/ and os/include/decorator/ (the reusable parts). It has a built-in Motif-inspired look, supplemented with a few fading effects. Technically, it actually contains a window system on its own. That is, it maintains a window stack and a single virtual framebuffer, on which all window decorations are painted. For each window, it creates four nitpicker views for making the top, left, right, and bottom window borders appear on screen. Alternative implementations may use different approaches such as creating a distinct nitpicker session per window. The decorator can be separately tested via the gems/run/decorator.run and gems/run/decorator_stress.run scripts.
A simple example window layouter can be found at gems/src/app/floating_window_layouter/. It implements a plain floating window layout that allows the moving, resizing, and topping of windows.
Nitpicker remains to be the key piece of the puzzle. But in order to fulfill its central position within the new GUI stack, we had to improve it in several ways. To accommodate the interplay of the nitpicker views maintained by the decorator and the applications, we added support for atomically updating multiple views at once. As a measure to mitigate potential overload situations and to allow us to switch to an asynchronous client interface, we changed the redraw handling to become time-period driven. An added signalling facility allows clients to synchronize themselves with nitpicker's periodic redraw processing. To allow the window manager to switch the keyboard focus according to the policy of the window layouter, we added a way to manage the focus using the nitpicker interface. In order to move the formerly built-in mouse cursor and status bar from nitpicker to separate programs, we introduced the notion of domains and layers. More details about those features are provided in Section Nitpicker GUI server.
All the components have in common that they have no access to the file system, the network, or any other parts of the system that are unrelated to the GUI. Each of the two security-critical (potential multi-level) components nitpicker and the window manager consists of less than 3000 lines of code and are unlikely to grow much in the future. So we succeeded in separating the security-critical parts from complex parts. At the same time, the new architecture promises a lot of flexibility. The look and behaviour can be customized by implementing interchangeable window layouters and decorators. As nitpicker and the window manager can be used at the same time, special programs (like panels or on-screen displays) can be connected to nitpicker directly while regular applications are managed through the window manager. There even can be multiple window managers running at the same time. E.g., on a multi-level security system, each security domain could have a distinct window manager. This would further increase the degree of isolation because such window-manager instances would not be shared by applications of different security levels. Performance-wise the implementation performs reasonably well on the Raspberry Pi.

|
|
The new window manager, decorator, floating window layouter, backdrop, and status bar in action. Windows 7 is executed in VirtualBox while the WebKit-based Arora web browser is running as Genode application. The entire scenario runs on the NOVA microhypervisor.
|
For test-driving the new GUI architecture, please have a look at the gems/run/wm.run script. Furthermore, we have switched all Qt5 examples to take advantage of the new window manager.
Low-level OS infrastructure
Nitpicker GUI server
To accommodate the new GUI architecture, we significantly improved nitpicker. At the API level, the most important change is the revisited session interface that allows for the batching of multiple view operations into an atomic RPC request. The mouse pointer and status bar are no longer parts of nitpicker but are realized as separate programs located at os/src/app/pointer and os/src/app/status_bar. The os/run/demo.run script contains a working example of how those components can be tied together. The feature set has been enhanced with the notion of domains, layers, and virtualized coordinate systems. The following excerpt of nitpicker's updated documentation explains how these features can be used by means of configuration. Details about further configuration options can be found at os/src/server/nitpicker/README.
- Domains
Nitpicker clients are grouped into so-called domains where each domain can be subjected to a different policy. The assignment of clients to domains is expressed via <policy> nodes as illustrated by the following example:
<config> ... <policy label="pointer" domain="pointer"/> <policy label="status_bar" domain="panel"/> <policy label="" domain=""/> ... </config>
When a session is created, the session label as provided with the creation request determines the policy rule to apply to the session. The policy with the longest matching label comes into effect. In the example above, the client labeled as "pointer" will be assigned to the domain named "pointer". The client labeled as "status_bar" will be assigned to the domain "panel". All other clients will be assigned to the third domain with an empty name.
The properties of each domain are declared via <domain> nodes. For example:
<config> ... <domain name="pointer" layer="1" xray="no" origin="pointer" /> <domain name="panel" layer="2" xray="no" /> <domain name="" layer="3" ypos="18" height="-18" /> ... </config>
- Layering
The name attribute of a <domain> node corresponds to the domain declarations of the <policy> nodes. Each domain requires the definition of a layer, which is a number. It allows for constraining the stacking position of the domain's views to a certain part of the global view stack. The front-most layer has the number 0. In the example above, all views of the "pointer" domain are presented in front of all others because the "pointer" domain is assigned to the lowest layer. All views of the "panel" domain are placed behind the "pointer" but in front to all other views that belong to the unnamed domain.
- Domain-specific coordinate systems
The operations issued by nitpicker clients refer to screen coordinates. For each domain, the coordinate system can be constrained in the following ways.
The origin attribute specifies the location of the coordinate (0,0) on screen. It can take the values "top_left", "top_right", "bottom_left", "bottom_right", and "pointer". By default, the coordinate origin (0,0) refers to the top-left screen corner. When configured to use the "pointer" as origin, all views of the domain are positioned relative to the current pointer position. When moving the mouse, the movement will be applied to all views of the domain. This enables the realization of pointer shapes outside of the nitpicker server.
In addition to the coarse definition of the origin, it is possible to further shift the origin by a fixed amount of pixels using the xpos and ypos attributes. By specifying an ypos value of 18 as in the example above, an operation that places a view at (0,0) will position the view at (0,18). This is useful to preserve a certain screen area for a panel.
The combination of the origin attribute with xpos and ypos allows the constraining of the screen at each border without the need to specify values that depend on the screen dimension. E.g., for placing a panel at the right screen border, the origin attribute can be set to "top_right" and the xpos value to a negative width of the panel.
- Domain-specific screen size constraints
The screen dimensions reported when a client requests the size of the screen can be tweaked per domain. E.g., when preserving a part of the screen for a panel, it is sensible to reduce the screen size reported to normal clients by the size of the panel so that such clients can adjust themselves to the part of the screen not covered by the panel. The screen-size constrains are expressed via the width and height attributes. If specifying a positive value, the value is reported to the client as is. If specifying a negative value, the value is subtracted from the physical dimensions. It is thereby possible to shrink the reported screen size independent of the physical screen size.
- X-Ray mode
The behavior of nitpicker's X-ray mode can be defined for each domain individually. Each domain can have an associated color configured via the color attribute. This color is used by nitpicker while the X-ray mode is active.
By setting the xray attribute to "frame" (default), the views of the domain will be surrounded by a thin frame of the domain color. The content of all non-focused views will be tinted using the domain color.
When setting the xray value to "opaque", the view's content will be replaced by the opaque session color. This is useful for domains that display many tiny views, e.g., window handles.
By assigning the value "none", the X-ray mode will not be applied to the domain. This is useful for trusted domains such as the pointer or a global panel. When X-ray mode gets activated, the views of those trusted clients remain unobstructed.
Nitpicker-based virtual framebuffer (nit_fb)
The existing nit_fb server has been reimplemented using the server API. It thereby enables dynamic resizing of the framebuffer.
Note that the new implementation does not feature the ability to perform a periodic refresh via the refresh_rate configuration argument. This feature was removed because the refresh policy can (and should) always be implemented on the client side.
ROM session interface
Originally, the ROM session interface had been designed for providing boot modules to the user land. Later, in version 12.05, we enhanced the interface to support dynamic updates of ROM modules to facilitate the reconfiguration of components at runtime. In the meanwhile, the dynamic updating of ROM modules has become commonplace within Genode, which prompted us to optimize the performance of the update mechanism.
The new Rom_session::update function can be used to request the update of an existing ROM dataspace. If the new data fits into the existing dataspace, a subsequent call of dataspace can be omitted. This way, ROM dataspace updates don't suffer from page-fault-handling costs that would occur when replacing the dataspace with each update.
Input session interface
Until now, all components that responded to user input used to poll the input-session interface at a rate of 10-20 milliseconds. This approach was fine in the presence of a few GUI applications but it does not scale. It also becomes a problem when chaining multiple GUI components. For example, when virtualizing the interface of the nitpicker GUI server or when nesting multiple nitpicker instances, input latencies would accumulate.
Hence, we changed both the Input::Session interface and the skeleton for the server-side implementation of this interface input/component.h. The Input::Session interface offers a new sigh function, which can be called by the client to register a signal handler. The signal handler gets notified on the arrival of new input. This alleviates the need to poll for input events at the client side.
The server-side skeleton for implementing input services underwent a redesign that makes it more modular and robust. I.e., there are no global functions needed at the server side and the event-queue enable/disable mechanism is implemented at a central place (in the root component) rather than inside each driver.
Loader session interface
The loader provides a service that allows clients to dynamically create Genode subsystems via a session interface. In contrast to a process that is spawning a new subsystem as an immediate child process, a loader client has very limited control over the spawned subsystem. It can merely define the binaries and configuration to start, define the position where the loaded subsystem will appear on screen, and kill the subsystem. But it is not able to interfere with the operation of the subsystem during its lifetime. The most illustrative use case is the execution of web-browser plugins where neither the browser trusts the plugin nor the plugin trusts the browser.
The far-reaching changes of the nitpicker GUI server required the loader interface to be partially redesigned. In the original version, the client could get hold of the view capability of the subsystem's view. In order to display the loaded subsystem on screen using the new version, the client has to supply a view capability that will be used as the parent view of the subsystem's view. The subsystem's view will no longer become accessible to the client. Instead, the client performs view operations (like positioning the view relative to the parent view) directly using the loader-session interface.
Pluggable VFS file systems
The virtual file system (VFS) infrastructure introduced with version 14.05, supports a number of built-in file-system types such as the TAR, ROM, FS, block, terminal, or LOG file systems. It allows the tailoring of the file-system environment specifically for each individual program.
To make the VFS even more flexible, we have added support for external VFS file systems. Such file systems come in the form of shared libraries that are loaded on demand when the corresponding file-system type is encountered in the process' VFS configuration. By convention, this library is named after the file-system type it provides. For example, a file system that provides a random file-system node would be called vfs_random.lib.so. It is still possible to give the node another name in the VFS. The following configuration snippet illustrates this idea:
<config>
<libc>
<vfs>
<dir name="dev"> <jitterentropy name="random"/> </dir>
</vfs>
</libc>
</config>
Here the "jitterentropy" file system, implemented in vfs_jitterentropy.lib.so, provides a file-system node named "random" in the dev/ directory. When traversing the <vfs> section of the configuration, the C runtime will request the ROM module vfs_jitterentropy.lib.so from its parent and load it as a shared library. The actual program is able to conveniently access the file system by opening /dev/random.
C-runtime support for time functions
Up to now, we only used the uptime as base period for all programs using the libc. Though unfortunately the time stamp of changed files used to show a wrong date, it posed no major issue but was merely an inconvenience. But it becomes a major issue when dealing with TLS/SSL. To check a given certificate, the TLS code needs a reasonable base period to validate the period stored in the certificate. Therefore, we needed a way to provide a more accurate base period. Most systems feature a hardware real-time clock (RTC), which is able to give a current date. However, not all platforms supported by Genode have a usable hardware real-time-clock, e.g., some ARM-based boards lack a battery to sustain power to its RTC.
For this reason, it is necessary to provide a way to use different base-period sources in a uniform way. We extended the <vfs> section of the libc configuration with a rtc attribute to accommodate for this requirement. By using this attribute, one can use any node of the process' VFS to provide the base period of the libc. The following configuration snippet illustrates this idea:
<config>
<libc>
<vfs rtc="/dev/rtc">
<dir name="dev"> <rtc/> </dir>
</vfs>
</libc>
</config>
In this example, the libc uses the /dev/rtc node to get access to the actual base-period source. On that account, we implemented a VFS file system called "rtc" that uses a Rtc_session to query the RTC value of the system. Currently this file system only works on x86-based platforms because it is the only platform that provides a RTC driver. Other platforms may use other ways to provide a RTC source. It is actually possible to use a "inline" file system to supply an arbitrary virtual time to a program:
<vfs rtc="/dev/inline_rtc">
</dir name="dev">
<inline name="inline_rtc">2014-08-26 13:46
</inline>
</dir>
</vfs>
The format of the output of any base-period source is by definition %Y-%m-%d %H:%M\n (the man page of date(1) contains an explanation of these sequences).
The gettimeofday(3) as well as the clock_gettime(3) function implemented in Genode's libc backend will query the base-period source on the first execution of these functions. They then add the current uptime in seconds and return this value. If there is no such source, the functions just return the uptime as they did before.
Improved support for cache attributes
On ARM it's important to not merely distinguish between ordinary cached memory and write-combined one, but also to consider non-cached memory. To insert the appropriate page table entries, e.g., in the base-hw kernel, we need to pass the information about the kind of memory from the user-level program that performs the allocation to the core process. Therefore, we introduced a new Cache_attribute type, which replaces the former write_combined flag where necessary, in particular the RAM session interface.
Utilities
Object life-time management using weak pointers
The management of object lifetimes is one of the most challenging problems of dynamic systems. If not handled properly, references to no-longer existing objects may remain in the system. When dereferenced, such a dangling pointer will eventually lead to memory corruption. In the presence of multiple threads (which usually imply a certain degree of indeterminism), such problems become a nightmare to debug. They cannot be easily reproduced and their symptoms vary a lot because any part of the memory may become corrupted. Most popular high-level languages address this problem via garbage collection. At the low level where Genode operates, however, we cannot rely on a garbage-collecting runtime to relieve us from dealing with this issue.
One way to approach this problem is to explicitly notify the holders of those pointers about the disappearance of the object. But this would require the object to keep references to those pointer holders, which, in turn, might disappear as well. Hence, this approach implies that both the pointed-to object and the pointer holders know each other, which creates unwanted circular dependencies. Consequently, this approach yields complex implementations, which are prone to deadlocks or race conditions when multiple threads are involved. Within Genode's core process, we employ a more elegant pattern called "weak pointers" to overcome the problem. With the current release, we promote this mechanism to become part of the framework API in the form of the new header base/include/base/weak_ptr.h. So regular components can use it for managing object lifetimes.
An object that might disappear at any time is represented by the Weak_object class template. It keeps track of a list of so-called weak pointers pointing to the object. A weak pointer, in turn, holds privately the pointer to the object alongside a validity flag. It cannot be used to dereference the object. For accessing the actual object, a locked pointer must be created from a weak pointer. If this creation succeeds, the object is guaranteed to be locked (not destructed) until the locked pointer gets destroyed. If the object no longer exists, the locked pointer will be invalid. This condition can (and should) be detected via the Locked_ptr::is_valid() function prior dereferencing the pointer.
In the event a weak object gets destructed, all weak pointers that point to the object are automatically invalidated. So a subsequent conversion into a locked pointer will yield an invalid pointer, which can be detected (in contrast to a dangling pointer).
To use this mechanism, the destruction of a weak object must be deferred until no locked pointer points to the object anymore. This is done by calling the function Weak_object::lock_for_destruction() at the beginning of the destructor of the to-be-destructed object. When this function returns, all weak pointers to the object will have been invalidated. So it is save to destruct and free the object.
New utility for tracking dirty rectangles
One problem shared by many graphical applications is the book-keeping of two-dimensional areas to update - be it a widget library that needs to redraw a certain part of a window or be it driver that needs keep the information about which pixels to flush to the physical device. The new Dirty_rect class template provided by os/include/util/dirty_rect.h provides a convenient solution to this book-keeping problem. It maintains the information about dirty areas in the form of a configurable number of rectangles. When a new dirty area gets registered, it changes the geometry of those rectangles to represent a compound of all reported dirty areas in a way that includes only a low number of non-dirty pixels.
Ultimately, by employing the Dirty_rect utility, graphical programs can easily gain two desired features: the dropping of intermediate states so that subsequent graphical operations won't queue up, and the merging of many small operations into a few large operations, reducing the overhead of per-operation setup-costs.
Libraries and applications
Port of the CPU Jitter Random-Number Generator
When using cryptographic algorithms, it is essential to have a source of good random numbers. Common operating systems use all kinds of sources to gather entropy such as device drivers to provide good random numbers to the kernel as well as to the userland. This mostly happens in the kernel itself because most common operating systems are using a monolithic kernel architecture. Such a kernel can access all kinds of sources to gather entropy and is thereby able to produce good random numbers.
Since Genode is component-based, it is more difficult to gather entropy. A specific protocol is needed to exchange and gather entropy because all components are isolated by default.
As a first step to address this issue, we ported Stephan Mueller's CPU Jitter Random Number Generator. This random-number generator uses the CPU execution-time jitter as entropy source and can be deployed in a de-centralized fashion, e.g., in the application itself. For the port of the number generator, we utilize the rdtsc instruction on x86-based platform whereas on ARM-based platforms, we use the available performance counters as more or less high-resolution timers. Though one entropy source is arguably not enough to provide good random numbers, it offers a way to gather at least some entropy while developing or porting applications that rely on it. As a practical example of using the library, the vfs_jitterentropy file system uses the number generator to provide the /dev/random node to libc based applications.
New port of OpenVPN
OpenVPN enables a user to access remote resources through a secure tunnel by providing an encrypted connection to a remote host. Among others, it can be used to bridge independent networks on the ethernet layer. In the Genode world, OpenVPN represents a component that sits in-between a NIC server (such as a network driver) and a NIC client. That is, it requests a NIC session and, in turn, provides a NIC service by itself.
With the current release, we included an initial port of OpenVPN version 2.3.4 operating as an OpenVPN client. After parsing its configuration, the OpenVPN client tries to connect to the remote host. If the attempt is successful, it announces the NIC service that can be used by other programs. The OpenVPN port utilizes the existing POSIX front end. Therefore, the regular command-line options have to be used to configure the client:
<config>
<arg value="openvpn"/>
<arg value="--config"/>
<arg value="/client.conf"/>
<libc stdout="/dev/log" stderr="/dev/log" rtc="/dev/rtc">
<vfs>
<dir name="dev">
<log/>
<jitterentropy name="random"/>
<rtc/>
</dir>
<rom name="ca.crt"/>
<rom name="client.conf"/>
<rom name="client.crt"/>
<rom name="client.key"/>
</vfs>
</libc>
</config>
As shown in the configuration, all needed files are imported via the ROM service into the VFS of the OpenVPN process. To actually use the NIC service provided by the OpenVPN client, the TCP/IP stack has to be configured accordingly to reach the server, and the connection to the NIC service must be routed from the application to the OpenVPN client. For example:
<config>
<libc stdin="/dev/null" stdout="/dev/log" stderr="/dev/log"
tx_buf_size="2M" rx_buf_size="2M" ip_addr="10.8.0.50"
netmask="255.255.255.0" gateway="10.8.0.4">
...
</libc>
</config>
<route>
<service name="Nic"> <child name="openvpn"/> </service>
<any-service> <parent/> <any-child/> </any-service>
</route>
The TCP/IP stack has to be configured statically because processing DHCP requests in the OpenVPN client is not implemented for the time being.
Networking for VirtualBox
With this release, we enabled network support in our port of VirtualBox. Based on the VirtualBox TAP back-end driver, we derived a Genode network driver, which directly uses the Genode NIC-session interface. Together with Genode's nic_bridge, the so-called bridged networking mode of VirtualBox is now available. The network cards and models we support are pcnet and e1000. The VirtualBox networking can be configured as follows:
<start name="virtualbox">
<resource name="RAM" quantum="1G"/>
<config>
<net model="e1000"/>
<net model="pcnet"/>
...
</config>
</start>
SMP for the Seoul virtual-machine monitor
To leverage multiple virtual CPUs and placing them on different host CPUs, we extended the x86 VMM interface in ports/include/vmm. With this change, a Cpu_session can be specified on vCPU construction. By providing different CPU sessions - which control the affinity and priority of threads and vCPUs - a VMM can now place vCPUs at different physical CPUs.
To evaluate this feature, we synchronized our Seoul branch with the vanilla branch and incorporated the patch series of Jacek Galowicz and Markus Partheymueller dealing with improvements of Seoul. In particular, we enabled the creation of several vCPUs, which will be assigned to all available host CPUs in a round-robin fashion.
For the Seoul VMM, several vCPUs can be instantiated by adding the vCPU parameters several times to the Seoul machine configuration:
<machine> ... <vcpu/> <halifax/> <vbios/> <lapic/> <!-- vCPU 1 --> <vcpu/> <halifax/> <vbios/> <lapic/> <!.. vCPU 2 --> ... </machine>
Additionally, all run scripts for Seoul now feature a convenience variable to specify the number of vCPUs.
Integration of Qt5
Since we introduced the original port of Qt5 one year ago, we have steadily worked on improving its integration with the framework. This release is no exception. Closely related to the new GUI stack described in Section New GUI architecture, we switched to the new window manager. So Qt windows will appear alongside other windows in a uniform way.
The redesign of the nitpicker GUI server had a significant effect on the Qt5 port. Nitpicker's new asynchronous mode of operation prompted us to implement double buffering in our back end of the Qt platform abstraction (QPA). This is needed to avoid intermediate drawing states to become visible on screen.
The Genode-specific additions to the Qt API for seamlessly integrating existing nitpicker applications into Qt programs underwent an almost complete rewrite. The QNitpickerViewWidget allows for the embedding of nitpicker clients. It is, for example, used by qt_avplay to run the video codec as a separate sandboxed program with a direct channel to the GUI server. The QPluginWidget provides a web-plugin mechanism to download a Genode subsystem from an URL and run it using the loader server. It is used by our port of the Arora web browser.
Furthermore, our port of Qt5 has been adapted to the new ports mechanism introduced with the previous release. At installation time of the "qt5" port, the Qt source codes are merely downloaded and integrated into the respective contrib directory but no further steps (like building QMake) are taken. All required host tools are built as side effects when building Qt. The tools will be built within the respective build directory instead of the source tree. This keeps the source tree clean from binaries and other compilation artifacts.
As a minor change, the Qt launchpad application has been updated to handle its configuration in the same way as the Scout launchpad.
New backdrop application
A new backdrop application found at gems/src/app/backdrop replaces the old program that was hosted in the demo repository. It composes a background image out of a solid color and an arbitrary number of PNG image files. It is able to dynamically respond to configuration changes as well as a changed screen size. For more details, please refer to the accompanied README file.
Device drivers
Timer on NOVA
Thanks to the new support of semaphore timeouts by the NOVA kernel, we retired the PIT-based timer driver on the NOVA platform and switched to a NOVA-specific timer variant instead. This step alleviates the performance overhead caused by programming the PIT via subsequent I/O port operations and reduces the inter-processor-interrupt (IPI) load.
DDE Linux updated to version 3.14.5
With the prospect to support more and up-to-date device drivers in the future, we updated the DDE-Linux code base from Linux version 3.9.0 to 3.14.5. This update includes all USB drivers (network, HID, storage) on all supported platforms (x86, Exynos5, OMAP, and Raspberry Pi) as well as the port of Linux's TCP/IP stack. Genode's new server framework implementation, which allows delivery of signals to an entry point, gave us the opportunity to make the server code truly single threaded. That is, only one thread executes Linux code, which relieves us from the burden of having to implement Linux's lock semantics.
As a functional addition, the USB driver gained support for HID multitouch devices.
Platforms
Execution on bare hardware (base-hw)
New source-tree structure
As the development of the base-hw project was always intended to serve us as guinea pig for experiments in kernel design, the resulting code couldn't be protected from accumulating some fundamental inconsistencies in style and methodology. However, now that this project enjoys more and more interest, not just among the inner circle of Genode developers, the time had come to clean up and consolidate some basic concepts for further contributions.
- Build configuration of core
Most of the core configuration moved to the new core library, leaving a generic src/core/target.mk that solely states the library dependency. In the course of this modification, we overcame three different - mainly stylistic - issues. First, the new solution avoids loads of "skipping target" messages during build process. Second, we removed many configuration redundancies that were caused by the fact that the prior core configuration was split up only by board specifiers such as arndale or panda. Now, this is done more fine-grained as, for example, demonstrated by the core configuration files for the Pandaboard:
lib/mk/platform_panda/core.mk .. include arm_v7/core.inc lib/mk/arm_v7/core.inc .. include arm/core.inc lib/mk/arm/core.inc .. include core.inc lib/mk/core.inc
The third aspect is the way, in which the interplay of multiple orthogonal specifiers is expressed. A good example for this is the trustzone specifier that can be present or not, depending on platform support for ARM Trustzone and the endeavor to use this optional feature. The presence or absence of the trustzone specifier shall be considered when building for i.MX53 or VEA9X4 boards only and shall then select the board specific enablement or disablement of the Trustzone feature. To achieve this, we define three additional libraries that act as extensions to the core library. The i.MX53 and VEA9X4 specific configuration of the core library itself states a dependency to core_trustzone. The configuration for this library is then automatically taken from lib/mk/core_trustzone.mk or lib/mk/trustzone/core_trustzone.mk according to the state of the trustzone specifier. The former variant now states a dependency to the core_trustzone_off library while the latter states a dependency to the core_trustzone_on library. As with core_trustzone.mk, core_trustzone_on.mk and core_trustzone_off.mk exist in different variants that allow for board distinction in the enablement and disablement configuration. So in summary, the files for, e.g., i.MX53-Trustzone configuration look as follows:
lib/mk/platform_imx53/core.mk .. add lib core_trustzone lib/mk/core-trustzone.mk .. add lib core_trustzone_off lib/mk/trustzone/core-trustzone.mk .. add lib core_trustzone_on lib/mk/platform_imx53/core-trustzone_off.mk lib/mk/platform_imx53/core-trustzone_on.mk
The same scheme applies to other examples of orthogonal specifiers such as the interplay of perf_counter and arm_v6 respectively arm_v7. It can also be enhanced to more than two dimensions of specifiers by adding further "switch" libraries like core_trustzone.
- File structure
With broadening the diversity of supported ARM platforms, the base-hw file structure had become hard to follow. It not only didn't coincide with the directory organization of other Genode repositories, it also lacked consistent rules itself. Especially the platform-specific files were affected by this deficiency so much that even regular developers found themselves wondering where to find a desired piece of code. Moreover, these conditions led to sub-directories and files that solely satisfied bureaucracy or patched up conceptual gaps.
After discussing several solutions, we decided to take an approach that is not far from what other Genode repositories do but also copes with the high diversity of specifier-dependent files in base-hw. First of all, all headers moved into include directories. Additionally, every file whose application depends on the presence of a specifier x, moved into a sub-directory spec/x and is named after the role it fulfills. For example, the code for the core driver of the i.MX53 interrupt controller now resides in src/core/include/spec/imx53/pic.h and src/core/spec/imx53/pic.cc. But a role might also be composed of code that depends on multiple specifiers, just as, for example, the PandaBoard CPU is a combination of ARM, ARMv7, and Cortex-A9 specific code. In this case, the driver headers would be:
core/include/spec/cortex_a9/cpu.h .. include spec/arm_v7/cpu_support.h core/include/spec/arm_v7/cpu_support.h .. include spec/arm/cpu_support.h core/include/spec/arm/cpu_support.h
where the cpu_support.h files are only included by drivers of ARM and ARMv7 CPUs, by using the generic include path as base (e.g. #include <spec/arm/cpu_support.h>) and can thus exist multiple times for a target platform. The cpu.h file on the other hand must be unique for each platform and is used by the rest of the core code without the specifier prefix (#include <cpu.h>). Corresponding source files would be located as follows:
core/spec/arm/cpu.cc core/spec/arm_v7/cpu.cc core/spec/cortex_a9/cpu.cc
The support postfix is not needed here as the files are directly selected in the appropriate Makefiles, using the generic source directory as base (e.g., SRC_CC += spec/arm_v7/cpu.cc).
Last but not least, there are roles that shall be encapsulated in an extra directory and name space, like the thread implementation of the kernel. This avoids clashes with filenames and symbols of, in this case, the Genode implementation of threads. Such a distinction is expressed as follows for generic files:
core/include/kernel/thread.h core/kernel/thread.cc
And for specifier-dependent files like those of the ARM specific thread_base role:
core/include/spec/arm/kernel/thread_base.h core/spec/arm/kernel/thread_base.cc
Enabling branch prediction
During recent experiments with branch prediction on ARM, the performance boost for general work loads took us by surprise. We observed time savings of about 30 percent in the noux_tool_chain_auto test. That motivated us to dig deeper.
However, our existing assembly code paths for MMU context switches did not consider out-of-order memory accesses, which are triggered by speculative instruction fetches. Such speculative behaviour, however, occurs when using branch prediction. We solved the problem by introducing a transitional translation table with global mappings only to bridge the switch phase without flushing the branch predictor each time.
With this solution in place, the branch predictor saves more then 50 percent of execution time in the noux_tool_chain_auto test, which exceeds all of our expectations and is a remarkable step towards common usability. We merely have to flush the predictor at startup and after adding a new entry to a translation table whereas the latter case may be an opportunity for even further optimization.
NOVA microhypervisor
We updated our kernel branch of NOVA to the latest vanilla branch of Udo Steinberg. The new vanilla branch fixes some PCID (aka tagged TLB) issues we encountered and adds support to specify timeouts on semaphore-down operations. We use the latter feature to replace the user-mode timer service for Genode/NOVA (formerly relying on the PIT timer) by a NOVA-specific version leveraging the direct use of kernel semaphores.
Build system and tools
Finished transition to new ports mechanism
In version 14.05, we introduced new tools for integrating 3rd-party software with Genode and migrated the majority of our ports to the new mechanism. With the current version, we have finished the transition by migrating the remaining ports, namely Qt5, GCC, and GDB.
Run-tool enhancements
Loading boot images via OpenOCD
OpenOCD is an open-source JTAG debugger that supports a wide range of low-cost JTAG debug interfaces. We enhanced the run tool with the new target mode "jtag-serial" and the corresponding options --jtag-debugger and --jtag-board. In the "jtag" mode, the run tool invokes OpenOCD to load the result of a run script to the target.
For example, to use the Olimex JTAG debug interface with the Raspberry Pi (see https://github.com/dwelch67/raspberrypi/tree/master/armjtag for more information about connecting JTAG to the board), the following lines must be added to the <build-dir>/etc/build.conf file:
RUN_OPT += --target jtag --target serial RUN_OPT += --jtag-debugger interface/olimex-arm-usb-ocd-h.cfg RUN_OPT += --jtag-board ./raspi.cfg
In this example, the board-specific OpenOCD configuration is provided via the file <build-dir>/raspi.cfg. For reference, the following OpenOCD board configuration works for the Raspberry Pi:
telnet_port 4444
adapter_khz 6000
if { [info exists CHIPNAME] } {
set _CHIPNAME $CHIPNAME
} else {
set _CHIPNAME raspi
}
reset_config none
if { [info exists CPU_TAPID ] } {
set _CPU_TAPID $CPU_TAPID
} else {
set _CPU_TAPID 0x07b7617F
}
jtag newtap $_CHIPNAME arm -irlen 5 -expected-id $_CPU_TAPID
set _TARGETNAME $_CHIPNAME.arm
target create $_TARGETNAME arm11 -chain-position $_TARGETNAME
With this configuration in place, Genode scenarios can be executed on the Raspberry Pi with the usual work flow when using run scripts.
Booting from a GRUB2 disk image with an ext2 partition
By default, the run tool produces an ISO image when executed for one of the x86-based platforms. The resulting ISO image can be passed to Qemu (the default behaviour) or it can be written to a CD or an USB stick to be used as boot medium on a real machine.
The downside of the ISO-image approach is that the file system cannot be modified by the running Genode system. Real-world system scenarios call for a way to boot from an USB stick with an ordinary file system. The new target mode "disk" accommodates such use cases. It can be enabled by adding the following line to your <build-dir>/etc/build.conf file:
RUN_OPT += --target disk
The resulting disk image contains one ext2 partition with the binaries of the GRUB2 boot loader and the run scenario. The default disk size is calculated to fit all binaries, but it is configurable via the option --disk-size <size in MiB> in the RUN_OPT variable.
The feature depends on the GRUB2 boot loader, which is contained in binary form at tool/grub2-head.img but may also be compiled manually by executing tool/create_grub2. The script generates a disk image prepared for one partition, which contains files for GRUB2. All image-preparation steps that require super-user privileges are conducted by this script, which needs to be executed only once. To avoid the need for super-user privileges during the normal work flow, we use Rump kernel tools to populate the disk image with files. Those tools can be installed via the tool/tool_chain_rump script.
After executing a run script, however, super-user privileges are needed to write the entire image to a physical disk:
sudo dd if=<image file> of=<device> bs=8M conv=fsync
XML syntax validation of the init configuration
The init process provides very little diagnostic feedback when it encounters a configuration with an invalid syntax. To ease the spotting of such mistakes, we included an automated call of xmllint into the regular work flow. When installed, xmllint will check the Genode config file when executing the install_config step of a run script.