
Release notes for the Genode OS Framework 10.05
With version 10.05, the Genode project aimed at creating the infrastructure needed to accommodate usage scenarios of ever increasing complexity. We are excited to have reached the milestone to run the first version the fully-fledged Arora web browser as native Genode process. The other major leap regarding Genode's infrastructure is a new configuration concept that lets us realize usage scenarios that we have dreamed of for a long time.
With the new configuration concept, we are now able to leverage the full power of Genode's hierarchical process structure. It enables us to implement fine-grained access control to all services that our system is comprised of. But the concept just as well offers extremely flexible ways of routing client-session requests throughout the Genode process tree to a matching server. We are looking forward to present several showcase scenarios of this new tool soon.
The second major focus for the current release was adding support for audio output. We created a modular audio-streaming solution consisting of device drivers for popular sound cards, an audio-mixer component, and a client application interface. The combination of these new components with real-time priorities introduced with the previous release and Genode's new configuration concept lays the foundation for high-quality audio processing on Genode.
Apart from these major topics, the new version comes with numerous functional improvements. For example, our ongoing efforts to tightly integrate the paravirtualized OKLinux kernel with native Genode components have culminated in the added support for the seamless integration of the X Window System with Genode's nitpicker GUI.
To boost the productivity of the Genode developers, we have implemented a new build system, which is compatible with the original one but operates much faster, in particular when used on systems with multiple CPUs.
Enabling mandatory access control
Since drafting the Genode architecture, we envisioned a flexible way to construct complex usage scenarios out of Genode's process nodes used as generic building blocks. Thanks to the strictly hierarchic and, at the same time, recursive structure of Genode, a parent has full control over the way, its children interact with each other and with the parent. The initial implementation provided three different examples of such policies, core's policy regarding the init process, the static policy of the init process, and a more dynamic policy of the interactive launchpad application.
- Core's policy
-
assigns all resources not used by core itself to init. Session requests coming from init could only refer to one of core's locally implemented services. Because init is the only child of core, there is no policy about the interaction between multiple children.
- Init's policy
-
is driven by a configuration file, which declares a number of children, their respective memory quotas and file names. Each child is able to announce services but each service can be announced only once. Any attempt of a child to announce an already existing service is denied. Session requests of all children are resolved in a uniform way. If the requested session refers to a service provided by core, init delegates the session request to its parent. These services are hard-coded to RAM, PD, RM, ROM, CPU, IRQ, IO_MEM, IO_PORT, CAP, SIGNAL, and LOG. Otherwise, the session request is delegated to one of the children. If the requested service is not yet announced, the aspiring client is put to halt until the service becomes available.
- Launchpad's policy
-
enriches init's policy by a small detail, but with a great effect. Instead of using fixed set of service names to take the decision about whether to forward a session request to the parent or to one of the other children, it implements the following rule: If the requested service was announced by a child of launchpad, the request is delegated to the child. Otherwise, the request is delegated to the parent. This simple modification allows children to override arbitrary services normally provided by core. For example, the nitlog application implements core's LOG interface. After started, all requests for a LOG session end up at nitlog instead of core, and this way, LOG output could be easily routed to the screen rather than to core's debug output. Another example is exercised by the tutorial of Genode default demo scenario, which allows for starting a second instance of the nitpicker GUI server within a windowed frame buffer, which, in turn, relies on the first instance of nitpicker.
Those three policies served us well for the past three years. Core's policy is simple and exactly what core needs for starting and accommodating the init process. Launchpad's policy illustrates well the power of Genode's recursive structure. But the limitations of init's policy have become apparent with our more recent use cases. We observed the following limitations.
-
The set of services provided by the parent is predefined and hard-coded in the source code of init. Even though init's configuration concept allows for running multiple nested init instances, the fixed set of parent services severe limits the practical use of this feature. In fact, for some use cases, we had to combine different init implementations to achieve our goals.
-
Within one instance of init, there is no way to restrict the access of one child to services provided by another child or to core's services.
-
Among children of one init instance, each service can be announced only once, based on a first-come-first-serve policy. There is no restriction about which child is permitted to announce which service. But there are legitimate uses of having multiple implementations of one interface present. For example, in the presence of more than one network cards, multiple network drivers may need to announce a NIC service each.
Despite of these limitations, the init configuration has one strong point, which is ease of use. Our challenge with designing a new configuration concept was to overcome the mentioned limitations while preserving the ease of use as far as possible.
Configuration
At the parent-child interface, there are two operations that are subject to policy decisions of the parent, the child announcing a service and the child requesting a service. If a child announces a service, the parent is up to decide if and how to make this service accessible to its other children. When a child requests a service, the parent may deny the session request, delegate the request to its own parent, implement the requested service locally, or open a session at one of its other children. This decision may depend on the requested service or session-construction arguments provided by the child. Apart from assigning resources to children, the central element of the policy implemented in the parent is a set of rules to route session requests. Therefore, the new configuration concept is laid out around processes and the routing of session requests. The concept is best illustrated by an example (executable on Linux):
<config>
<parent-provides>
<service name="CAP"/>
<service name="LOG"/>
</parent-provides>
<start name="timer">
<resource name="RAM" quantum="1M"/>
<provides> <service name="Timer"/> </provides>
<route>
<service name="CAP"> <parent/> </service>
</route>
</start>
<start name="test-timer">
<resource name="RAM" quantum="1M"/>
<route>
<service name="Timer"> <child name="timer"/> </service>
<service name="LOG"> <parent/> </service>
</route>
</start>
</config>
First, there is the declaration of services provided by the parent of the configured init instance. In this case, we declare that the parent provides a CAP service and a LOG service. For each child to start, there is a <start> node describing resource assignments, declaring services provided by the child and holding a routing table for session requests originating from the child. The first child is called "timer" and implements the "Timer" service. To implement this service, the timer requires a CAP session. In the routing table, we define that a CAP session request gets delegated to init's parent. The second process called "test-timer" is a client of the timer service. In its routing table, we see that requests for "Timer" sessions should be routed to the "timer" child whereas requests for "LOG" sessions should be delegated to init's parent. Per-child service routing rules provide a flexible way to express arbitrary client-server relationships. For example, service requests may be transparently mediated through special policy components acting upon session-construction arguments. There might be multiple children implementing the same service, each addressed by different routing tables. If there is no valid route to a requested service, the service is denied. In the example above, the routing tables act effectively as a whitelist of services the child is allowed to use.
In practice, usage scenarios become more complex than the basic example, increasing the size of routing tables. Furthermore, in many practical cases, multiple children may use the same set of services, and require duplicated routing tables within the configuration. In particular during development, the elaborative specification of routing tables tend to become an inconvenience. To alleviate this problem, there are two mechanisms, wildcards and a default route. Instead of specifying a list of single service routes targeting the same destination, the wildcard <any-service> becomes handy. For example, instead of specifying
<route> <service name="ROM"> <parent/> </service> <service name="RAM"> <parent/> </service> <service name="RM"> <parent/> </service> <service name="PD"> <parent/> </service> <service name="CPU"> <parent/> </service> </route>
the following shortcut can be used:
<route> <any-service> <parent/> </any-service> </route>
The latter version is not as strict as the first one because it permits the child to create sessions at the parent, which were not whitelisted in the elaborative version. Therefore, the use of wildcards is discouraged for configuring untrusted components. Wildcards and explicit routes may be combined as illustrated by the following example:
<route> <service name="LOG"> <child name="nitlog"/> </service> <any-service> <parent/> </any-service> </route>
The routing table is processed starting with the first entry. If the route matches the service request, it is taken, otherwise the remaining routing-table entries are visited. This way, the explicit service route of "LOG" sessions to "nitlog" shadows the LOG service provided by the parent.
To emulate the traditional init policy, which allows a child to use services provided by arbitrary other children, there is a further wildcard called <any-child>. Using this wildcard, the traditional policy can be expressed as follows:
<route> <any-service> <parent/> </any-service> <any-service> <any-child/> </any-service> </route>
This rule would delegate all session requests referring to one of the parent's services to the parent. If no parent service matches the session request, the request is routed to any child providing the service. The rule can be further reduced to:
<route> <any-service> <parent/> <any-child/> </any-service> </route>
Potential ambiguities caused by multiple children providing the same service are detected automatically. In this case, the ambiguity must be resolved using an explicit route preceding the wildcards.
To reduce the need to specify the same routing table for many children in one configuration, there is a <default-route> mechanism. The default route is declared within the <config> node and used for each <start> entry with no <route> node. In particular during development, the default route becomes handy to keep the configuration tidy and neat.
We believe that with the combination of explicit routes and wildcards, we have designed a solution that scales well from being convenient to use during development towards being highly secure at deployment time. If only explicit rules are present in the configuration, the permitted relationships between all processes are explicitly defined and can be easily verified. Note however that the degree those rules are enforced at the kernel-interface level depends on the used base platform.
Advanced features
In addition to the service routing facility described in the previous section, the following features are worth noting:
Resource quota saturation
If a specified resource (i.e., RAM quota) exceeds the available resources. The available resources are assigned completely to the child. This makes it possible to assign all remaining resources to the last child by simply specifying an overly large quantum.
Multiple instantiation of a single ELF binary
Each <start> node requires a unique name attribute. By default, the value of this attribute is used as file name for obtaining the ELF binary at the parent's ROM service. If multiple instances of the same ELF binary are needed, the binary name can be explicitly specified using a <binary> sub node of the <start> node:
<binary name="filename"/>
This way, the unique child names can be chosen independently from the binary file name.
Nested configuration
Each <start> node can host a <config> sub node. The content of this sub node is provided to the child when a ROM session for the file name "config" is requested. Thereby, arbitrary configuration parameters can be passed to the child. For example, the following configuration starts timer-test within an init instance within another init instance. To show the flexibility of init's service routing facility, the "Timer" session of the second-level timer-test child is routed to the timer service started at the first-level init instance.
<config>
<parent-provides>
<service name="CAP"/>
<service name="LOG"/>
<service name="ROM"/>
<service name="RAM"/>
<service name="CPU"/>
<service name="RM"/>
<service name="PD"/>
</parent-provides>
<start name="timer">
<resource name="RAM" quantum="1M"/>
<provides><service name="Timer"/></provides>
<route>
<service name="CAP"> <parent/> </service>
</route>
</start>
<start name="init">
<resource name="RAM" quantum="1M"/>
<config>
<parent-provides>
<service name="Timer"/>
<service name="LOG"/>
</parent-provides>
<start name="test-timer">
<resource name="RAM" quantum="1M"/>
<route>
<service name="Timer"> <parent/> </service>
<service name="LOG"> <parent/> </service>
</route>
</start>
</config>
<route>
<service name="Timer"> <child name="timer"/> </service>
<service name="LOG"> <parent/> </service>
<service name="ROM"> <parent/> </service>
<service name="RAM"> <parent/> </service>
<service name="CAP"> <parent/> </service>
<service name="CPU"> <parent/> </service>
<service name="RM"> <parent/> </service>
<service name="PD"> <parent/> </service>
</route>
</start>
</config>
The services ROM, RAM, CPU, RM, and PD are required by the second-level init instance to create the timer-test process.
As illustrated by this example, the use of the nested configuration feature enables the construction of arbitrarily complex process trees via a single configuration file.
Priority support
The number of CPU priorities to be distinguished by init can be specified with prio_levels attribute of the <config> node. The value must be a power of two. By default, no priorities are used. To assign a priority to a child process, a priority value can be specified as priority attribute of the corresponding <start> node. Valid priority values lie in the range of
-prio_levels + 1 (maximum priority degradation) to 0 (no priority degradation).
Using the new configuration concept
With the current release, the old configuration concept is still enabled by default. With the upcoming release, we will change the default to the new concept and declare the old concept as obsolete and to-be-removed. To enable the new concept now, all you need to do is adding the following line to your <build-dir>/etc/specs.conf file:
SPECS += use_new_init
By adding this line, the build system will build the init variant at os/src/init/experimental rather than the default variant at os/src/init. To get acquainted with the new configuration format, there are two example configuration files located at os/src/init/experimental, which are both ready-to-use with the Linux version of Genode. Both configurations produce the same scenario but they differ in the way policy is expressed. The explicit_routing example is an example for the elaborative specification of all service routes. All service requests not explicitly specified are denied. So this policy is a whitelist enforcing mandatory access control on each session request. The example illustrates well that such a elaborative specification is possible in an intuitive manner. However, it is significantly more comprehensive than a traditional configuration file of init. In cases where the elaborative specification of service routing is not fundamentally important, in particular during development, the use of wildcards can help to simplify the configuration. The wildcard example demonstrates the use of a default route for session-request resolution and wildcards. This variant is less strict about which child uses which service. For development, its simplicity is beneficial but for deployment, we recommend to remove wildcards (<default-route>, <any-child>, and <any-service>) altogether. The absence of such wildcards is easy to check automatically to ensure that service routes are explicitly whitelisted.
Base framework
This section provides a description of a number of small changes of the base framework. It is rather detailed to ease the migration of existing code to the new Genode version.
New child management framework
To realize the new configuration concept of init, we completely reworked the child-management classes in base/child.h, base/service.h, and init/child.h. The Child class used to implement the most basic policy that applies to all children, which comprises the protocols for trading memory quota and the handling of the child's environment sessions. It was meant to be derived by more a specialized policy such as init's policy. Thereby, each derived implementation of the Child class used to tailor the policy to a further degree. We identified two problems with this approach. First, the policy resulting from tweaking one or more inherited policies became hard to grasp because it was spread in multiple files. For example, launchpad's policy is influenced by launchpad.h, init/child.h, and base/child.h. Second, we observed that the generic program logic for resource trading was closely intermingled with policy-specific code. This way, modifying an inherited policy resulted in duplicating program logic code of the inherited class.
With the new implementation, we completely separated the raw mechanisms needed for running a child process from its policy. To illustrate the change, lets look at the difference between the old and new Child constructor:
The original version looked a follows:
Child(const char *name,
Dataspace_capability elf_ds,
Ram_session_capability ram,
Cpu_session_capability cpu,
Cap_session *cap,
char *args[])
The Child class used to aggregate several pieces needed to run a child. In particular, it contained a dedicated entry point and server-activation thread to serve the parent interface for the child. The cap argument was merely required to construct the entry point. This design resulted in a number of problems: The stack size of the server-activation thread was fixed and could not be changed by an inherited class. Because the entry point and server-activation thread were embedded in the child, special accessor functions were needed to let the creator of a Child interact with them. For example, the start of the server activation had to be triggered by a special finalize_construction call. For using the entry point for serving additional local services, the special accessor function parent_entrypoint was needed.
The new Child constructor looks as follows:
Child(Dataspace_capability elf_ds,
Ram_session_capability ram,
Cpu_session_capability cpu,
Server_entrypoint *entrypoint,
Child_policy *policy)
One prominent change is that the entry point is now supplied as an argument, which in principle allows for sharing one entry point by multiple children and local services, and enables the use of arbitrary stack sizes. The more significant change is the new Child_policy argument, supplied to the new child. The Child_policy interface consists of the following functions:
const char *name() const;
The name function returns the name of the child, which was previously be directly supplied as argument to the Child constructor.
Service *resolve_session_request(const char *service_name,
const char *args);
This function is central to routing service requests to service providers. A Service is either a locally implemented service, a service provided by the parent, or a service provided by another child. If the service request is denied altogether, the function returns 0. Thanks to the args argument, the resolution of the service requests can be made dependent on session-construction arguments, for example a filename argument supplied to a new ROM session.
void filter_session_args(const char *service,
char *args, size_t args_len);
This function enables the transformation of session-construction arguments. Its uses are manifold. For example, labeling each session by prefixing the label session argument with the child name informs the server about the identity of the client (see Child_policy_enforce_labeling). Another example is the transformation applied to the CPU priority as introduced by the Genode version 10.02 (see Child_policy_handle_cpu_priorities).
bool announce_service(const char *name,
Root_capability root,
Allocator *alloc)
This function takes note of new service announcements coming from the child. An announcement can be denied by returning 0. Otherwise, the policy is free to consider the new service for subsequent resolve_session_request calls coming from other children.
With this policy toolkit, it was not only possible to easily reconstruct the original behaviour of Core_child, Init::Child, and Launchpad::Child, it also enabled the new configuration concept and service routing described in Section Enabling mandatory access control. The Child class defined in base/child.h is no longer meant as a base class for customized child policies but it solely contains the program logic for managing open sessions and performing resource trading.
Because base/child.h is closely related to base/service.h, the classes defined in the latter were also subject to a major overhaul. The new Service interface removed the need for differently typed service pools. Instead there is now a single Service_registry. Since the Service class abstracts from parent, local, or child servers, it obsoleted the Session_control interface.
Flexible page sizes
Core's generic page-fault handling code has become able to handle any page size supported by underlying platforms. On OKL4, L4ka::Pistachio, NOVA, and L4/Fiasco, core uses flexpages as big as possible. The used subset of supported page size can be tailored for each platform using a new helper function in the platform-specific core/include/util.h. The function constrain_map_size_log2 takes a page size (log2) as argument and returns a nearest (lower or equal than the argument) possible page size to be used for a mapping on this platform.
To further unify the code among different kernels, we made the generic code agnostic about the mapping source. On some kernels (e.g., OKL4, Codezero), map operations refer to a physical address as source. On other kernels (typically, kernels that rely on a mapping database), a core-local virtual address is used as mapping source. Now, we introduced the function map_src_addr, which takes both a core-local and a physical address as argument and returns one of those, depending on the kernel.
Miscellaneous changes
- Exception types
-
Structured exception types of Parent interface
-
Introduced Rom_connection_failed exception to the Rom_connection interface. Often, Rom_connection errors are caused by user errors, which are hard to come by when the program aborts with a Parent::Service_denied exception. The new exception type make the problem cause easier to spot.
-
Removed redundant Rom_file_missing exception from the Rom_session interface. By definition, this exception cannot occur because a ROM session for a non-existing file will throw a Parent::Service_denied exception.
- Growing heap chunks
The heap used to grow by chunks of 16 KB (on 32 bit) respectively 32 KB (on 64 bit) blocks for small allocations. Each block is backed by an independent dataspace. On Linux, this is problematic because each dataspace is represented as a distinct file attached to the local address space via mmap. Because on Linux, the maximum number of open file descriptors is limited to 1024, Genode processes on Linux could not use more than 16/32 MB of small memory blocks. This limitation became noticeable with Qt4 applications, which rely on a large number of small allocations. To alleviate this problem, we changed the allocation of heap chunks from a fixed block size to an exponentially growing block size, capped at a maximum block size of 4/8 MB.
- String parsing functions
We unified the various ascii-parsing functions such as ascii_to_ulong, ascii_to_long, ascii_to_size, ascii_to_double defined in util/string.h to be overloads of a single function template called ascii_to<T>:
template <typename T>
size_t ascii_to(const char *s, T *result,
unsigned base = 0);
There are specializations for long, unsigned long, and double. For parsing size values suffixed with K, M, or G, there is a helper class called Number_of_bytes wrapping size_t. When passing a pointer to such an object as argument to ascii_to, the suffix-handling specialization is selected.
The use of overloading makes it easier to use the parsing functionality from function templates which can thereby stay type-independent. For example, Xml_node::value already benefits from this unification. Please note that we removed the string-length argument that was supported by some of the previous parsing functions. All ascii_to implementations do expect null-terminated strings.
- Tokenizer
The Token class is used by the Arg_string class and the XML parser, which used to employ the same syntactic rules for identifiers. Because this is no longer the case, we made those rules customizable by turning the Token class into a class template taking a scanner policy as argument. The scanner policy consists of a boolean function identifier_char for classifying a character as part of an identifier.
- Synchronization
-
Removed a rare race condition in the generic Cancelable_lock implementation introduced by a compiler optimization. We discovered this problem first while running multiple instances of OKLinux under heavy load.
-
Corrected the handling of lock cancellations for locks that were doubly locked by the same thread. The cancellation condition is detected by verifying the current lock owner when being waked up. If the unblocking was caused by a regular unlock by the old lock owner, the unblocked thread is the new lock owner. Otherwise, the blocking was canceled. However, if a thread took a lock twice, it is the lock owner, regardless of the cause of getting unblocked. So lock cancellations went undetected in this special case. We solved this ambiguity by reseting the lock ownership when the current lock owner tries to take the lock again.
- Startup code and C++ runtime
In _main, we make sure to initialize the exception handling prior processing global constructors. This way, exceptions that occur while executing such constructors can be handled. Because the exception-handling initialization relies on malloc, which in turn relies on the heap, which in turn, depends on Genode::env(), global constructors must no longer be used in the base framework. Otherwise, this change would result in cyclic dependencies. Hence, we replaced the last few occurrences of global constructors with local static constructors. For example, in base-okl4/src/base/console/okl4_console.cc, we replaced:
static Okl4_console okl4_console;
with
static Okl4_console &okl4_console()
{
static Okl4_console static_okl4_console;
return static_okl4_console;
}
and replaced the use of the okl4_console object by the respective call of okl4_console().
Of course, global constructors outside the Genode base frameworks are fully supported.
- Dedicated I/O-port thread in core
To reduce the temporal inter-dependency of I/O port accesses from core's services, we moved the I/O port service to a separate thread within core. This way, I/O port operations are performed out of band with other core's services. The immediate effect is an improved accuracy of the PIC timer driver.
Operating-system services and libraries
XML parser
Since the initial Genode release, we employ a simple XML parser for runtime configuration purposes. The parser comes in the form of the single header file os/include/util/xml_node.h. We tied the feature set of the parser to the simple structures that we use for the init process, supporting nested <tags> and </endtags> as well as XML comments. This simple parser served as well over the last two years. The new configuration concept introduced with the current release, however, prompted us to reconsider its feature set. We noted that although using the existing markup to express complex attributes and relations is principally possible, the resulting configuration files tend to become incomprehensible and hard to maintain. After exemplarily applying XML attributes and empty-element tags to our show-case configurations, we observed that those negative effects could be entirely mitigated. On the other hand, extending the XML parser would imply an increase in code complexity, which we generally want to avoid. Fortunately, with around 100 lines of code added for the provisioning of XML attributes and empty-element tags, the effect on code complexity turned out to be reasonably low so that we decided for the extension of the XML parser. Because this extension would require an API change, we took the chance of further streamlining the interface and implementation of the XML parser. The changes are:
-
The length-limited parsing of XML data is now fully implemented.
-
The supported forms for tag names are no longer a subset of the XML standard. Now, underline, colon, dot, and minus characters are supported.
-
Optimized the search through an XML node for a specified node type by omitting a call of _num_sub_nodes. This way, the XML node is walked only once per call, not twice.
-
The accessor functions for the content of an XML node (content, read) had been unified to the template function value, which allows for the interpretation of all types supported by the ascii_to overloads defined in base/include/util/string.h.
-
Renamed function is_type to has_type
-
Added support for empty-element tags of the form '<element/>
-
Added support for XML attributes using the new Xml_node::Attribute class
-
Renamed exception type Nonexistent_subnode to Nonexistent_sub_node to foster consistence with the Genode coding style
Timed semaphore
We added a semaphore variant supporting timeouts to the os repository. The new Timed_semaphore extends the interface of the original semaphore with a new down function taking a timeout as argument. The implementation relies on a jiffies thread that is started the first time a timeout is used. The timeout granularity is set to 50 ms to accommodate our current use cases (TCP timeouts and select timeouts).
Added select to C library
We enhanced our C library with a select implementation that interplays with the libc plugin concept. This way, a libc plugin such as the lwIP back end can wake up blocking select calls that include their respective file descriptors. Furthermore, the new select implementation includes support for timeouts. The timeout handling is provided via a timed semaphore.
Further changes are the addition of lseek and _open to the plugin interface, and the a sanitized dummy for gai_strerror, which is required for running Arora.
Device-class interfaces for NIC and Audio-out
While looking into implementing further device class interfaces, we observed recurring patterns in the use of Genode's packet stream API. Naturally, there are four use cases that are related to packet streams.
-
A client transmits packets
-
A server receives packets
-
A client receives packets
-
A server transmits packets
For each of these cases, we have created utility classes to ease the realization of packet-stream-based inter-component interfaces. We grouped the first two cases (transmit channel - TX) and the latter two cases (receive channel - RX). The corresponding utility classes reside in os/include/packet_stream_rx/ and os/include/packet_stream_tx/. Each of both directories contain the usual elements of an RPC interface, an abstract interface shared between client and server (called packet_steam_rx.h or packet_stream_tx.h), the client-side interface (client.h) and the server-side interface (server.h).
By applying these new generalized utility classes to the existing Nic_session interface, we were able significantly reduce the code complexity of this device-class interface and expect less code duplications when introducing further device classes.
Note that the change of the Nic_session interface implies a slight API change. The former wrapper functions such as rx_packet_avail() were removed in favor for a generic accessor to the stream interface. So this code must be changed to rx()->packet_avail() and respectively for the other wrapper functions.
Audio playback sessions
The audio-out interface extends Genode's device-class interfaces by a facility for audio-stream playback. It is based on the packet-stream framework and uses one TX stream per audio channel. Therefore, the channel configuration is not limited by the interface and audio-out servers are free to provide custom channel configurations to clients. For example, standard stereo playback creates to sessions - one for "left" and one for "right". More sophisticated applications may request 5.1 surround sound with channels for front left/center/right and rear left/right plus low-frequency effects (LFE).
The actual PCM stream data uses 32-bit floating point numbers. This implementation fosters complex audio applications with multi-channel mixers and effect chains on all platforms supported by Genode.
Servers
Nitpicker
We implemented the per-client background handling. Each client is free to select one of its views as background. If the user activates the client, the background view gets displayed as desktop background. In the presence of multiple window systems as nitpicker clients, each window system can have its own fully operational desktop. Depending on the client the user is currently interacting with, the corresponding desktop is displayed.
Audio-out mixer
Based on the new audio-out session interface, we implemented an audio mixer, which currently supports up to 16 stereo inputs and uses one stereo output. We also added a simple audio-test program that plays configured raw stereo float-PCM streams. The configuration snippet configures input to direct all Audio_out sessions to the mixer except for the mixer itself, which uses the audio driver as back end. The complete example can be found in os/config/mixer:
<config>
...
</parent-provides>
<default-route>
<!-- all clients use the mixer for audio per default -->
<service name="Audio_out"> <child name="mixer"/> </service>
<any-service> <parent/> <any-child/> </any-service>
</default-route>
...
<start name="audio_out_drv">
<resource name="RAM" quantum="8M"/>
<provides> <service name="Audio_out"/> </provides>
</start>
<start name="mixer">
<resource name="RAM" quantum="1M"/>
<provides> <service name="Audio_out"/> </provides>
<route>
<!-- use the actual driver as mixer back end -->
<service name="Audio_out"> <child name="audio_out_drv"/> </service>
<any-service> <parent/> <any-child/> </any-service>
</route>
</start>
<start name="test-audio_out">
<resource name="RAM" quantum="12M"/>
<config>
<!-- a bunch of raw media files in 2-channel FLOAT -->
<filename>silence.f32</filename>
<filename>silence.f32</filename>
</config>
</start>
</config>
The scenario includes the audio test with two configured PCM-stream files.
Device drivers
Audio out
With the introduction of the audio-out session interface, we implemented drivers for certain audio back ends. Currently, each of them provides two channels - "front left" and "front right".
On Linux, the audio_out_drv uses the ALSA libraries and opens the ALSA device hw. Therefore, it needs exclusive access to the sound hardware and other media applications should be closed. For real hardware support, we ported the following drivers in DDE Linux 2.6:
-
Ensoniq ES1370 (ens1370.c)
-
Intel earlier ICH and before (intel8x0.c)
-
Intel HD Audio
If you use the Qemu emulator to run Genode, activate the sound hardware with the -soundhw all command line switch. Please note that the default sound back end may stutter on some systems. In this case, you may try other back ends by configuring the QEMU_AUDIO_DRV environment variable (see qemu -audio-help for more information). The following worked best on our systems:
QEMU_AUDIO_DRV=oss qemu -soundhw all -cdrom genode.iso
Timer
We improved the accuracy of the Linux-specific and PIT-based timer implementations. On Linux, the timer relies on absolute time provided by the gettimeofday system call rather than accumulated sleep times. For the PIT timer driver, we removed the caching of the current time and instead read the PIT counter register directly as needed.
Input
Added input driver for PL050 PS/2 mouse and keyboard as found on the VersatilePB platform.
Protocol stacks and libraries
zlib and libpng
Since the first Genode release, the demo repository contains ports of zlib and libpng to enable the Scout tutorial browser to display PNG images. These libraries were meant to be used with the mini_libc that is also part of the demo repository. For other use cases than Scout, this port is incomplete. To provide a fully-fledged zlib and libpng to Qt4, we renamed the old library ports to libz_static and libpng_static, and added fresh ports of the current zlib-1.2.5 and libpng-1.4.1 to the libports repository. In contrast to the old libraries, the new versions are built as shared objects.
libSDL
We integrated Stefan Kalkowski's original port of libSDL-1.2.13 into the libports repository. Currently, it comes with back ends for SDL video using Genode's Framebuffer interface and SDL events using Genode's Input interface.
Qt4
-
Enabled support for handling JPEG, GIF, and PNG files. Qt4 does no longer depends on the libz and libpng libraries of the demo depository. It uses shared libraries provided by the libports repository instead.
-
Qt4 threads are now named as "Qt <noname>"
-
Let Qt4 use the standard C++ library that comes with the GCC tool chain. This change removed the need for custom new and delete operators.
-
The timeout handling is now accomplished using the new select implementation of the C library.
-
Added support for more mouse buttons than only the left one
-
Avoid unsupported timezone conversions
-
Some Qt4 applications use to rely on local pipes for internal thread synchronization. Such pipes do not carry payload but are used only as a mechanism to block and wake up threads. To support such applications, we added a libc plugin with a simplified implementation of pipe(), which is essentially a lock. The libc plugin is called qt_libc_pipe and comes as a shared library with the qt4 repository.
-
Enabled networking support by reverting to the original event dispatcher implementation using the new select() and pipe() functions of the C library
-
Added Thread_qt::stack_base() function to return the stack base of a thread as this function is required by Webkit's Javascript engine.
-
We moved the Dejavu-Sans font to a library because we use to link this TTF font as a static resource to various Qt4 applications. By placing it into a library, we avoid duplicating the font file in the source tree.
lwIP stack
-
The lwIP-specific timed semaphore implementation and the corresponding alarm thread have been replaced by the new generic timed semaphore provided by the os repository.
-
We improved the integration of lwIP with the C library. The libc_lwip plugin supports the new select implementation. To improve the convenience of configuring lwIP, we added two helper libraries libc_lwip_loopback and libc_lwip_nic_dhcp. If either of both libraries is linked against a lwIP-using target, the IP stack gets configured to use a loopback device or a NIC adaptor with a dynamically acquired IP address. This facilitates the reuse of existing BSD-socket-based networking code on Genode without modifications. For an example, please see libports/src/test/lwip/loopback. The http_srv example is still using lwIP directly without relying on the libc_lwip plugin.
X event tracker
We refined our window event tracker used for the seamless integration of the X Window System with the nitpicker GUI. (either on Linux using Xvfb, or with OKLinux using our Genode-FB stub driver) We improved the accuracy of window stack operations and reduced pixel artifacts regarding the mouse cursor. The latter problem, however, is not yet completely solved. Unfortunately, the X mouse cursor is not captured by the X damage extension used to track screen updates. Therefore, we need to employ heuristics, which have still room for improvement.
DDE Kit
We added support for handling sub-page-size I/O memory regions. To hand out different I/O resources that reside on the same page to different processes, we changed the I/O memory allocator in core to use byte granularity. A page is handed out if the requested sub range is still available. Consequently, one and the same I/O memory page may be mapped to multiple drivers, each meant to access a portion of the page. At the DDE Kit API level, small I/O regions are handled completely transparent to the user of the API.
GUI and sound for paravirtualized Linux
With the current release, we brought forward the integration of OKLinux with native Genode components. This integration is achieved by so-called stub drivers — Linux device drivers that use Genode's services instead of hardware devices. Our original port of OKLinux to Genode came with stub drivers for virtual timer, user input, and framebuffer devices using Genode's timer-session, input-session, and framebuffer-session interfaces. We have now complemented our stub driver with drivers for the seamless integration of the X Window System with the nitpicker GUI and sound. The Genode stub drivers are unconditionally compiled into the OKLinux kernel. There is no need to enable them in the Linux kernel configuration.
GUI
The seamless integration of the X Window System running on OKLinux with the natively running nitpicker GUI is achieved by an enhanced Linux framebuffer device. The number of virtual framebuffer devices can be declared in the Genode configuration of the OKLinux kernel as follows:
<config>
<screens>
<framebuffer/>
<nitpicker/>
</screens>
</config>
The order in the screens section determine the order of visible devices in Linux. A <framebuffer/> entry declares a regular fb device corresponding to the Framebuffer session. A <nitpicker/> entry declares an enhanced fb device that supports the propagation with window-stacking events (via ioctl), which are needed for the seamless integration of the X Window System. The first device is typically used as boot console. For this reason, it should be a regular <framebuffer/>. To run the X Window System in seamless mode using the configuration above, the X server must be configured to use the /dev/fb1 device and the X session must start the X event tracker application, which feeds window-state transitions to the enhanced /dev/fb1 device. The X event tracker is a plain Linux program located at oklinux/src/app/xev_track. Note that this program must be build for a Linux host platformm using a separate build directory. This build directory must use the base-host repository and extend the SPECS variable with x11, xtest, and xdamage.
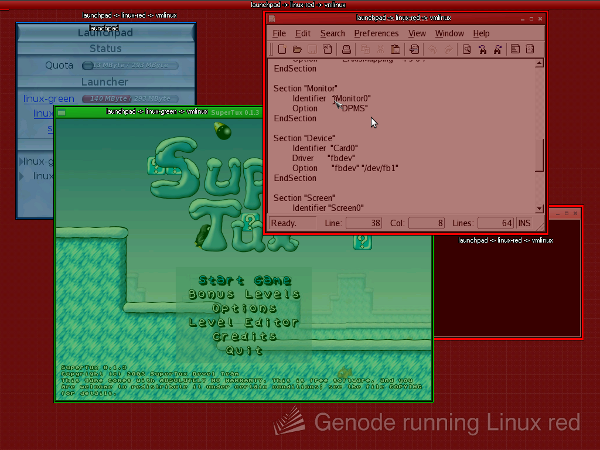
|
The screenshot shows two Linux instances and the native launchpad application seamlessly integrated into a single GUI. We slightly modified nitpicker to tint each client using a different color when activating the X-Ray mode. Even though multiple window systems are running in parallel, the tinting and nitpicker's floating labels reveal the information about which part of the screen belongs to which protection domain.
Applications
In the line of the libports repository, we added a new ports repository. Whereas libports is meant as a place for 3rd-party libraries, ports is the designated place for 3rd-party applications. The mechanism for downloading and preparing upstream source-code distributions is exactly the same. The first application is the Qt4-based Arora web browser.
Arora web browser
Arora has its origin as an example application for Qt4. However, it emancipated itself to be a separate project.
- https://arora.googlecode.com
-
Arora project website
Even though compared with other browsers, its popularity is relatively small but for us, it is perfect to stretch the bounds of our Genode infrastructure. The following screenshot shows Arora running as native Genode process.
|
Porting Arora to Genode motivated many improvements of our C library, the Qt4 port, and the lwIP stack. In the current state, the application is fully functional and can be used to browse complex websites. However, our port is still a proof of concept and not fully stable. As one interesting detail, Arora on Genode is directly linked against the lwIP stack, which obtains an IP address via DHCP.
To download the Arora source code, issue make prepare from the ports repository. For building the application, make sure to have also prepared the qt4 and libports repositories and specified those repositories in your <build-dir>/etc/build.conf file. From within your build directory, you can then issue make app/arora.
For a first test drive, we recommend to use the Linux version of Genode. On Linux, we can use Genode's TUN/TAP device driver located at os/src/drivers/nic/linux. This driver uses the tap0 device to send and receive raw Ethernet packets. To create such a device, issue the following command (use sudo):
tunctl -b -u <username>
This command should return the name of the TAP device. If no other TAP devices were created prior executing tunctl, this should be tap0. You can activate the device via:
ifconfig tap0 up
To associate tap0 with your Ethernet device connected to the internet, you will further need a bridge device:
brctl addbr br0
This command creates a new bridge device called br0. Let's now associate the bridge with both, your eth0 device (connected to the internet) and the tap0 device:
brctl addif br0 eth0 brctl addif br0 tap0
Now you can activate the bridge and try to obtain a fresh IP address.
ifconfig br0 up dhclient br0
After following these steps, the os/src/drivers/nic/linux driver should be functional and you can use the following init configuration (using the traditional version of init) for starting Arora on Linux:
<config>
<start>
<filename>fb_sdl</filename>
<ram_quota>2M</ram_quota>
</start>
<start>
<filename>timer</filename>
<ram_quota>0x20000</ram_quota>
</start>
<start>
<filename>nitpicker</filename>
<ram_quota>1M</ram_quota>
</start>
<start>
<filename>nic_drv</filename>
<ram_quota>1M</ram_quota>
</start>
<start>
<filename>arora</filename>
<ram_quota>2G</ram_quota>
</start>
</config>
Note that the default memory pool used by Genode on Linux might be too small for running Arora. To increase the amount of usable memory, change the _some_mem declaration in base-linux/src/core/platform.cc.
Platform-specific changes
- Codezero
-
Adapted Genode to the development branch of Codezero version 0.3 and the gcc-4.4 tool chain
-
Implemented the Genode lock using Codezero's kernel mutex as block/unblock mechanism. This way, the lock supports the full semantics of the lock API including lock cancellation. The design is the same as for the lock on NOVA. There is one kernel mutex per thread, which is part of the thread context. A tread can block itself by trying to acquire the mutex twice. Another thread can then wake up the thread by releasing the mutex.
-
Added a new mechanism for ROM modules via a separate ROM ELF image. The new mechanism relies on the new gen_romfs tool at base-codezero/tool. For changing the set of boot modules, core must no longer be modified or recompiled.
-
Implemented core's IRQ service for Codezero
- NOVA
To use NOVA on recent hardware, which often lacks RS232 ports, a serial PCI card can be used for debugging. Because such a card is not initialized by the BIOS, we added proper serial initialization code to NOVA core console.
Build system
New two-stage build system
Since the thorough analysis of the Genode build system by Ludwig Hähne in 2008, we were planning to incorporate his findings into Genode. In his study, he reimplemented Genode's make-based build system using SCons and compared both implementations. For us, the two most interesting conclusions were that recursive make is evil and that SCons scales worse than make with regard to memory usage.
The statement about recursive make was not entirely new to us but because we were not aware of a good alternative, our build system relies on this scheme for handling inter-library dependencies. This becomes troublesome if enabling parallel builds using -j. If two libraries A and B depend on the same library C, both A and B can be build concurrently, and both will issue the build process for library C. However, if one and the same library C is build twice in parallel, race conditions happen. For this reason, we explicitly disabled parallel execution of make rules using GNU make's .NOTPARALLEL feature. But this severe limits the scalability of the build system.
But according to the findings of the study, SCons seemed to be no viable alternative for other reasons, most importantly its memory foot print when dealing with large source trees. SCons uses to create a complete dependency graph by reading all SConscript files of the source tree. For building the complete tree, this is of course needed but most of the time, only little parts of the tree are of interest. In contrast, the Genode build system processes only those build-description files that are required for the current build, resulting in a constant memory usage regardless of the size of the source tree.
Finally, the study evidenced that flat make outperformed both SCons and recursive make in terms of performance, scalability regarding parallelism, and memory footprint.
Consequently, we sticked with our make-based solution but were seeking for a way to avoid recursive make. We have now realized a solution that replaces our original single-pass recursive make by a two-stage approach.
At the first stage, a library-dependency graph is generated by using recursive make with no parallelism. Starting from the set of targets specified at the top-level make instance, all library-description files required by those targets are traversed in a recursive manner. So libraries can depend on further libraries. During this process, a dependency graph for the particular set of targets is generated. It is represented as a makefile called <build-dir>/var/libdeps.
The second stage is driven by the generated <build-dir>/var/libdeps file, taking full advantage of parallelism. Because all inter-library dependencies are now specified at one flat makefile, race conditions cannot occur and the build performance effectively corresponds to a flat make. For building each single leaf of the dependency graph (either a library or a target), a sub make is used, which encapsulates the leaf-specific build environment such as custom compiler flags or defines.
Following the lines of the original build system, both stages visit only those build-description files that are required for the current set of targets. If this set is large, the first stage causes a clearly visible delay prior the actual build, which was formerly obscured in the call sequence of recursive make instances. The work flow of developing interdependent components such as an application, a protocol stack, and a device driver often comprehends a build command that is repetitively used. For example,
make drivers server app/stresstest
To avoid the costs for regenerating the same dependency graph again and again, the first stage can be skipped by using:
make again
This way, the current version of var/libdeps is reused for the second stage. In practice, this shortcut provides a welcome performance boost for such work flows.
From the developer's point of view, the new build system is fully compatible with the old one but faster. No build-description files need to be changed to take advantage of it. We slightly changed the build output because the grouping of build steps to targets is no longer useful when building in parallel. The best way for directing the build system to work in parallel is specifying a -j argument in your <build-dir>/etc/build.conf file, for example
'MAKE += -j 4'
Further improvements are a much faster clean rule, an improved handling of defect or missing libraries, and the detection of ambiguous target names.
Improved interplay between shared objects and static libraries
We reworked the interplay between static libraries and shared objects to cover cases where static libraries are linked against shared objects. Because this is possible, all libraries are now compiled as position-independent code (using the -fPIC compiler option) unless specified otherwise. This behaviour can be disabled per library by adding CC_OPT_PIC = to its library-description file.