
Release notes for the Genode OS Framework 12.02
The release of Genode 12.02 marks an exciting point in the history of the project as it is the first version developed in the open rather than within the chambers of Genode Labs. Thereby, we have embraced GitHub as central facility for discussion and source-code management. This change has benefits for users and developers of the framework alike. For users, it has become possible to get hold of the latest developments using the official genodelabs/master branch and get involved with discussing the current activities. For regular Genode developers, the public Git repository replaces a former mix of public Subversion and company-internal Mercurial repositories, making life much easier. In Section Liberation of the development process, we outline the motivation behind this change and give pointers to the new resources.
The major new additions to the base system are a new framework API for accessing memory-mapped I/O resources, special support for using Genode as user-level component framework on Linux, and API support for the reuse of existing components in the form of sandboxed libraries. These changes are accompanied with new device-driver infrastructure such as the first version of a device driver manager and a new ACPI parser.
Feature-wise, the current release takes the first steps towards the goal of the Roadmap for 2012, turning Genode into a general-purpose OS ready for everyday use by its developers. According to the roadmap, we enhanced the Noux runtime with fork semantics so that we can run command-line based GNU programs such as the bash shell and coreutils unmodified and natively on various microkernels. Furthermore, the library infrastructure has been enhanced by porting and updating libraries such as Qt 4.7.4 and the MuPDF PDF rendering engine.
Liberation of the development process
In summer 2011, we started a discussion within Genode Labs about changing the mode of how Genode is developed. Until then, most design discussions and the actual development work took place locally at the company. At quarterly intervals, we used to publish our work in the form of official Genode releases. This way of development seemed to work quite well for us, we were satisfied about the pace of development, and with each release, our project got more recognition.
However, the excellent book Producing Open Source Software made us realize that even though we released our work under an Open-Source license, our development process was actually far from being open and may have discouraged participation of people outside the inner circle of developers. Because we believe that the framework has reached a state where it becomes interesting for a wider audience of users and developers, the idea was born to liberate the project from its closed fashion of development.
In the beginning of December, the vague idea has become a plan. So we finally brought the topic to our mailing list (Steps towards an open development process). We decided to take the release cycle for Genode 12.02 as the opportunity to put our plan to practice. The central element of this endeavour was moving the project over to GitHub and adapt our workflows and tooling support accordingly. First, we started to embrace GitHub's issue tracker for the management of working topics:
- https://github.com/genodelabs/genode/issues
-
Issue Tracker
The most significant step was leaving our Genode-Labs-internal code repositories behind and starting a completely public Git repository instead:
- https://github.com/genodelabs
-
Genode Labs at GitHub
With the code repository going public, the way was cleared to opening up design discussions as well. Instead of having such discussions internally at Genode Labs, we try to increasingly take them to our mailing list and issue tracker. With this new way of development, we hope to make the project much more approachable for people who want to get involved and let Genode reach far out beyond the reach of our little company.
The changes mentioned above are actually just the tip of the iceberg. For example, the transition phase required us to rethink the way the project website is maintained. From now on, almost all of the content of genode.org comes directly from the project's Git repository. So maintaining website content is done in the same coherent and transparent way as working on Genode's code base. So we could finally put the old Wiki to rest. In the process, we largely revisited the existing content. For example, we rewrote the contributions document in a tutorial-like style and incorporated several practical hints, in particular related to the recommended use of Git.
Although it is probably too early to judge the outcome of our transition, we are excited how smooth this massive change went. We attribute this pleasant experience mostly to the excellent GitHub hosting platform, which instantly ignited a spirit of open collaboration among us. We are excited to see new people approaching us and showing their interest for teaming up, and we are curious about where this new model of development will take Genode in the future.
Base framework, low-level OS infrastructure
RPC framework refinements
Until now, the RPC framework did not support const RPC functions. Rather than being a limitation inherent to the concept, const RPC functions plainly did not exist. So supporting them was not deemed too important. However, there are uses of RPC interfaces that would benefit from a way to declare an RPC function as const. Candidates are functions like Framebuffer::Session::mode() and Input::Session::is_pending().
With the current version, we clear the way towards declaring such functions as const. Even though the change is pretty straight-forward, the thorough support for const-qualified RPC functions would double the number of overloads for the call_member function template (in base/include/util/meta.h). For this reason, as of now, the support of const functions is limited to typical getter functions with no arguments. This appears to be the most common use of such functions.
API support for enslaving services
While evolving and using the framework, we always keep an eye on recurring patterns of how its API is used. Once such a pattern becomes obvious, we try to take a step back, generalize the observed pattern, and come up with a new building block that unifies the former repetitive code fragments.
One of those patterns that was far from obvious when we designed Genode years ago is the use of a service running as child of its own client. At the first glance, this idea seems counter-intuitive because normally, services are understood as components that operate independently and protected from their (untrusted) clients. But there is a class of problems where this approach becomes extremely useful: The reuse of protocol implementations as a library-like building block. Most services are actually protocol stacks that translate a low-level protocol to a more abstract API. For example, a block device driver translates a specific device API to the generic Block_session interface. Or the iso9660 service translates the Block_session interface to the Rom_session interface by parsing the ISO9660 file system. Or similarly, the tar_rom service parses the tar file format to make its content available via the Rom_session interface.
If a particular functionality is needed by multiple programs, it is common practice to move this functionality into a dedicated library to avoid the duplication of the same code at many places. For example, if a program would need to parse a tar archive, it might be tempting to move the tar-parsing code from the tar_rom service into a dedicated library, which can then be used by both the tar_rom service and the new program. An alternative approach is to just re-use the tar_rom service as a black box and treat it like it was a library. That is, start the tar_rom service as a child process, supply the resources the component needs to operate and, in turn, use its API (now in the form of an RPC interface) to get work done. Because the service is started as a mere tool at the discretion of its client, we call it slave. It turns out that this idea works exceedingly well in many cases. In a way, it resembles the Unix philosophy to solve complex problems by combining many small tools each with a specific purpose. In contrast to the use of libraries, the reuse of entire components has benefits with regard to fault isolation. Because the reused functionality is sandboxed within a distinct process, the environment exposed to this code can be tailored to a rigid subset of the host program's environment. In the event of a fault within the reused component, the reach of problem is therefore limited.
On the other hand, we observed that even though this idea works as intended, implementing the idea for a particular use case involved a good deal of boiler-plate code where most of this code is needed to define the slave's environment and resources. Hence, we reviewed the existing occurrences of the slave pattern and condensed their common concerns into the Slave_policy and Slave classes residing in os/include/os/slave.h. The Slave class is meant to be used as is. It is merely a convenience wrapper for a child process and its basic resources. The Slave_policy is meant as a hook for service-specific customizations. The best showcase is the new d3m component located at gems/src/server/d3m. D3m extensively uses the slave pattern by instantiating and destroying drivers and file-system instances on-the-fly. A further instance of this pattern can be found in the new ACPI driver introduced with the current release.
Support for resizable framebuffers
The framebuffer-session interface has remained largely untouched since the original release of Genode in 2008. Back then, we were used to rely on C-style out parameters in RPC functions. The current RPC framework, however, promotes the use of a more object-oriented style. So the time has come to revisit the framebuffer session interface. Instead of using C-style out parameters, the new mode() RPC call returns the mode information as an object of type Mode. Consequently, mode-specific functions such as bytes_per_pixel() have been moved to the new Framebuffer::Mode class. The former info() function is gone.
In addition to the overhaul of the RPC interface, we introduced basic support for resizable framebuffers. The new mode_sigh() function enables a client to register a signal handler at the framebuffer session. This signal handler gets notified in the event of server-side mode changes. Via the new release() function, the client is able to acknowledge a mode change. By calling it, the client tells the framebuffer service that it no longer uses the original framebuffer dataspace. So the server can replace it by a new one. After having called release(), the client can obtain the dataspace for the new mode by calling dataspace() again.
MMIO access framework
As the arsenal of native device drivers for Genode grows, we are observing an increased demand to formalize the style of how drivers are written to foster code consistency. One particular cause of inconsistency used to be the way of how memory-mapped I/O registers are accessed. C++ has poor support for defining bit-accurate register layouts in memory. Therefore, driver code usually carries along a custom set of convenience functions for reading and writing registers of different widths as well as a list of bit definitions in the form of enum values or #define statements. To access parts of a register, the usual pattern is similar to the following example (taken from the pl011 UART driver:
enum {
UARTCR = 0x030, /* control register */
UARTCR_UARTEN = 0x0001, /* enable bit in control register */
...
}
...
/* enable UART */
_write_reg(UARTCR, _read_reg(UARTCR) | UARTCR_UARTEN);
This example showcases two inconveniences: The way the register layout is expressed and the manual labour needed to access parts of registers. In the general case, a driver needs to also consider MASK and SHIFT values to implement access to partial registers properly. This is not just inconvenient but also error prone. For lazy programmers as ourselves, it's just too easy to overwrite "undefined" bits in a register instead of explicitly masking the access to the actually targeted bits. Consequently, the driver may work fine with the current generation of devices but break with the next generation.
So the idea was born to introduce an easy-to-use formalism for this problem. We had two goals: First, we wanted to cleanly separate the declaration of register layouts from the program logic of the driver. The actual driver program should be free from any intrinsics in the form of bit-masking operations. Second, we wanted to promote uncluttered driver code that uses names (i.e., in the form of type names) rather than values to express its operations. The latter goal is actually achieved by the example above by the use of enum values, but this is only achieved through discipline. We would prefer to have an API that facilitates the use of proper names as the most convenient way to express an operation.
The resulting MMIO API comes in the form of two new header files located at base/include/util/register.h and base/include/util/mmio.h.
Register declarations
The class templates found in util/register.h provide a means to express register layouts using C++ types. In a way, these templates make up for C++'s missing facility to define accurate bitfields. Let's take a look at a simple example of the Register class template that can be used to define a register as well as a bitfield within this register:
struct Vaporizer : Register<16>
{
struct Enable : Bitfield<2,1> { };
struct State : Bitfield<3,3> {
enum{ SOLID = 1, LIQUID = 2, GASSY = 3 };
};
static void write (access_t value);
static access_t read ();
};
In the example, Vaporizer is a 16-bit register, which is expressed via the Register template argument. The Register class template allows for accessing register content at a finer granularity than the whole register width. To give a specific part of the register a name, the Register::Bitfield class template is used. It describes a bit region within the range of the compound register. The bit 2 corresponds to true if the device is enabled and bits 3 to 5 encode the State. To access the actual register, the methods read() and write() must be provided as backend, which performs the access of the whole register. Once defined, the Vaporizer offers a handy way to access the individual parts of the register, for example:
/* read the whole register content */ Vaporizer::access_t r = Vaporizer::read(); /* clear a bit field */ Vaporizer::Enable::clear(r); /* read a bit field value */ unsigned old_state = Vaporizer::State::get(r); /* assign new bit field value */ Vaporizer::State::set(r, Vaporizer::State::LIQUID); /* write whole register */ Vaporizer::write(r);
Memory-mapped I/O
The utilities provided by util/mmio.h use the Register template class as a building block to provide easy-to-use access to memory-mapped I/O registers. The Mmio class represents a memory-mapped I/O region taking its local base address as constructor argument. Let's take a simple example to see how it is supposed to be used:
class Timer : Mmio
{
struct Value : Register<0x0, 32> { };
struct Control : Register<0x4, 8> {
struct Enable : Bitfield<0,1> { };
struct Irq : Bitfield<3,1> { };
struct Method : Bitfield<1,2>
{
enum { ONCE = 1, RELOAD = 2, CYCLE = 3 };
};
};
public:
Timer(addr_t base) : Mmio(base) { }
void enable();
void set_timeout(Value::access_t duration);
bool irq_raised();
};
The memory-mapped timer device consists of two registers: The 32-bit Value register and the 8-bit Control register. They are located at the MMIO offsets 0x0 and 0x4, respectively. Some parts of the Control register have specific meanings as expressed by the Bitfield definitions within the Control struct.
Using these declarations, accessing the individual bits becomes almost a verbatim description of how the device is used. For example:
void enable()
{
/* access an individual bitfield */
write<Control::Enable>(true);
}
void set_timeout(Value::access_t duration)
{
/* write complete content of a register */
write<Value>(duration);
/* write all bitfields as one transaction */
write<Control>(Control::Enable::bits(1) |
Control::Method::bits(Control::Method::ONCE) |
Control::Irq::bits(0));
}
bool irq_raised()
{
return read<Control::Irq>();
}
In addition to those basic facilities, further noteworthy features of the new API are the support for register arrays and the graceful overflow handling with respect to register and bitfield boundaries.
C Runtime
We extended our FreeBSD-based C runtime to accommodate the needs of the Noux runtime environment and our port of the MuPDF application.
-
The dummy implementation of _ioctl() has been removed. This function is called internally within the libc, i.e., by tcgetattr(). For running libreadline in Noux, we need to hook into those ioctl operations via the libc plugin interface.
-
The libc/regex and libc/compat modules have been added to the libc. These libraries are needed by the forthcoming port of Slashem to Noux.
-
We added a default implementation of chdir(). It relies on the sequence of open(), fchdir(), close().
-
The new libc plugin libc_rom enables the use of libc file I/O functions to access ROM files as provided by Genode ROM session.
-
We changed the libc dummy implementations to always return ENOSYS. Prior this change, errno used to remain untouched by those functions causing indeterministic behaviour of code that calls those functions, observes the error return value (as returned by most dummies), and evaluates the error condition reported by errno.
-
If using the libc for Noux programs, the default implementations of time-related functions such as gettimeofday() cannot be used because they rely on a dedicated timeout-scheduler thread. Noux programs, however, are expected to contain only the main thread. By turning the functions into weak symbols, we enabled the noux libc-plugin to provide custom implementations.
DDE Kit
Linux DDE used to implement Linux spin locks based on dde_kit_lock. This works fine if a spin lock is initialized only once and used from then on. But if spin locks are initialized on-the-fly at a high rate, each initialization causes the allocation of a new dde_kit_lock. Because in contrast to normal locks, spinlocks cannot be explicitly destroyed, the spin-lock emulating locks are never freed. To solve the leakage of locks, we complemented DDE Kit with the new os/include/dde_kit/spin_lock.h API providing the semantics as expected by Linux drivers.
Libraries and applications
New and updated libraries
- Qt4 updated to version 4.7.4
-
We updated Qt4 from version 4.7.1 to version 4.7.4. For the most part, the update contains bug fixes as detailed in the release notes for the versions 4.7.2, 4.7.3, and 4.7.4.
- Update of zlib to version 1.2.6
-
Because zlib 1.2.5 is no more available at zlib.net, we bumped the zlib version to 1.2.6.
- New ports of openjpeg, jbig2dec, and mupdf
-
MuPDF is a fast and versatile PDF rendering library with only a few dependencies. It depends on openjpeg (JPEG2000 codec) and jbig2dec (b/w image compression library). With the current version, we integrated those libraries alongside the MuPDF library to the libports repository.
GDB monitor refinements and automated test
We improved the support for GDB-based user-level debugging as introduced with the previous release.
For the x86 architecture, we fixed a corner-case problem with using the two-byte INT 0 instruction for breakpoints. The fix changes the breakpoint instruction to the single-byte HLT. HLT is a privileged instruction and triggers an exception when executed in user mode.
The new gdb_monitor_interactive.run script extends the original gdb_monitor.run script with a startup sequence that automates the initial break-in at the main() function of a dynamically linked binary.
The revised gdb_monitor.run script has been improved to become a full automated test case for GDB functionalities. It exercises the following features (currently on Fiasco.OC only):
-
Breakpoint in main()
-
Breakpoint in a shared-library function
-
Stack trace when not in a syscall
-
Thread info
-
Single stepping
-
Handling of segmentation-fault exception
-
Stack trace when in a syscall
PDF viewer
According to our road map for 2012, we pursued the port of an existing PDF viewer as native application to Genode.
We first looked at the libpoppler, which seems to be the most popular PDF rendering engine in the world of freedesktop.org. To get a grasp on what the porting effort of this engine may be, we looked at projects using this library as well as the library source code. By examining applications such as the light-weight epdfview application, we observed that libpoppler's primary design goal is to integrate well with existing freedesktop.org infrastructure rather than to reimplement functionality that is provided by another library. For example, fontconfig is used to obtain font information and Cairo is used as rendering backend. In the context of freedesktop.org, this makes perfect sense. But in our context, porting libpoppler would require us to port all this infrastructure to Genode as well. To illustrate the order of magnitude of the effort needed, epdfview depends on 65 shared libraries. Of course, at some point in the future, we will be faced to carry out this porting work. But for the immediate goal to have a PDF rendering engine available on Genode, it seems overly involved. Another criterion to evaluate the feasibility of integrating libpoppler with Genode is its API. By glancing at the API, it seems to be extremely feature rich and complex - certainly not a thing to conquer in one evening with a glass of wine. The Qt4 backend of the library comprises circa 8000 lines of code. This value can be taken as a vague hint at the amount of work needed to create a custom backend, i.e., for Genode's framebuffer-session interface.
Fortunately for us, there exists an alternative PDF rendering engine named MuPDF. The concept of MuPDF is quite the opposite of that of libpoppler. MuPDF tries to be as self-sufficient as possible in order to be suitable for embedded systems without comprehensive OS infrastructure. It comes with a custom vector-graphics library (instead of using an existing library such as Cairo) and it even has statically linked-in all font information needed to display PDF files that come with no embedded fonts. That said, it does not try to reinvent the wheel in every regard. For example, it relies on common libraries such as zlib, libpng, jpeg, freetype, and openjpeg. Most of them are already available on Genode. And the remaining libraries are rather free-standing and easy to port. To illustrate the low degree of dependencies, the MuPDF application on GNU/Linux depends on only 15 shared libraries. The best thing about MuPDF from our perspective however, is its lean and clean API, and the wonderfully simple example application. Thanks to this example, it was a breeze to integrate the MuPDF engine with Genode's native framebuffer-session and input-session interfaces. The effort needed for this integration work lies in the order of less than 300 lines of code.
At the current stage, the MuPDF rendering engine successfully runs on Genode in the form of a simple interactive test program, which can be started via the libports/run/mupdf run script. The program supports the basic key handling required to browse through a multi-page PDF document (page-up or enter -> next page, page-down or backspace -> previous page).
Improved terminal performance
The terminal component used to make all intermediate states visible to the framebuffer in a fully synchronous fashion. This is an unfortunate behaviour when scrolling through large text outputs. By decoupling the conversion of the terminal state to pixels from the Terminal::write() RPC function, intermediate terminal states produced by sub sequential write operations do not end up on screen one by one but only the final state becomes visible. This improvement drastically improves the speed in situations with a lot of intermediate states.
Noux support for fork semantics
Genode proclaims to be a framework out of which operating systems can be built. There is no better way of putting this claim to the test than to use the framework for building a Unix-like OS. This is the role of the Noux runtime environment.
During the past releases, Noux evolved into a runtime environment that is able to execute complex command-line-based GNU software such as VIM with no modification. However, we cannot talk of Unix without talking about its fundamental concept embodied in the form of the fork() system call. We did not entirely dismiss the idea of implementing fork() into Noux but up to now, it was something that we willingly overlooked. However, the primary goal of Noux is to run the GNU userland natively on Genode. This includes a good deal of programs that rely on fork semantics. We could either try to change all the programs to use a Genode-specific way of starting programs or bite in the bullet and implement fork. With the current release, we did the latter.
The biggest challenge of implementing fork was to find a solution that is not tied to one kernel but one that works across all the different base platforms. The principle problem of starting a new process in a platform-independent manner is already solved by Genode in the form of the Process API. But this startup procedure is entirely different from the semantics of fork. The key to the solution was Genode's natural ability to virtualize the access to low-level platform resources. To implement fork semantics, all Noux has to do is to provide local implementations of core's RAM, RM, and CPU session interfaces.
The custom implementation of the CPU session interface is used to tweak the startup procedure as performed by the Process class. Normally, processes start execution immediately at creation time at the ELF entry point. For implementing fork semantics, however, this default behavior does not work. Instead, we need to defer the start of the main thread until we have finished copying the address space of the forking process. Furthermore, we need to start the main thread at a custom trampoline function rather than at the ELF entry point. Those customizations are possible by wrapping core's CPU service.
The custom implementation of the RAM session interface provides a pool of RAM shared by Noux and all Noux processes. The use of a shared pool alleviates the need to assign RAM quota to individual Noux processes. Furthermore, the custom implementation is needed to get hold of the RAM dataspaces allocated by each Noux process. When forking a process, the acquired information is used to create a shadow copy of the forking address space.
Finally, a custom RM service implementation is used for recording all RM regions attached to the region-manager session of a Noux process. Using the recorded information, the address-space layout can then be replayed onto a new process created via fork.
With the virtualized platform resources in place, the only puzzle piece that is missing is the bootstrapping of the new process. When its main thread is started, it has an identical address-space content as the forking process but it has to talk to a different parent entrypoint and a different Noux session. The procedure of re-establishing the relationship of the new process to its parent is achieved via a small trampoline function that re-initializes the process environment and then branches to the original forking point via setjmp/longjmp. This mechanism is implemented in the libc_noux plugin.
As the immediate result of this work, a simple fork test can be executed across all base platforms except for Linux (Linux is not supported yet). The test program is located at ports/src/test/noux_fork and can be started with the ports/run/noux_fork.run script.
Furthermore, as a slightly more exciting example, there is a run script for running a bash shell on a tar file system that contains coreutils. By starting the ports/run/noux_bash.run script, you get presented an interactive bash shell. The shell is displayed via the terminal service and accepts user input. It allows you to start one of the coreutils programs such as ls or cat. Please note that the current state is still largely untested, incomplete, and flaky. But considering that Noux is comprised of less than 2500 lines of code, we are quite surprised of how far one can get with such little effort.
Device drivers
Driver improvements to accommodate dynamic (re-)loading
To support the dynamic probing of devices as performed by the new d3m component, the ATAPI and USB device drivers have been enhanced to support the subsequent closing and re-opening of sessions.
First bits of the d3m device-driver manager
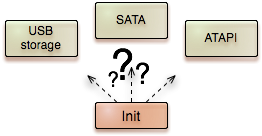
The abbreviation d3m stands for demo device-driver manager. It is our current solution for the automated loading of suitable drivers as needed for running Genode from a Live CD or USB stick. Because of the current narrow focus of d3m, it is not a generic driver-management solution but a first step in this direction. We hope that in the long run, d3m will evolve to become a generic driver-management facility so that we can remove one of the "D"s from its name. In the current form d3m solves the problems of merging input-event streams, selecting the boot device, and dealing with failing network drivers.
When using the live CD, we expect user input to come from USB HID devices or from a PS/2 mouse and keyboard. The live system should be operational if at least one of those sources of input is available. In the presence of multiple sources, we want to accumulate the events of all of them.
The live CD should come in the form of a single ISO image that can be burned onto a CDROM or alternatively copied to an USB stick. The live system should boot fine in both cases. The first boot stage is accommodated by syslinux and the GRUB boot loader using BIOS functions. But once Genode takes over control, it needs to figure out on its own from where to fetch data. A priori, there is no way to guess whether the ATAPI driver or the USB storage driver should be used.
|
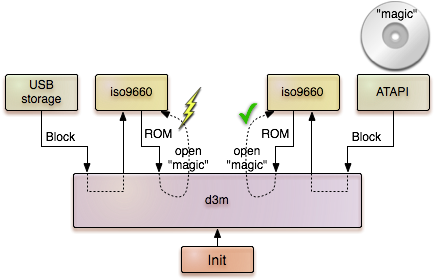
Therefore, d3m implements a probing mechanism that starts each of the drivers, probes for the presence of a particular file on an iso9660 file system.
|
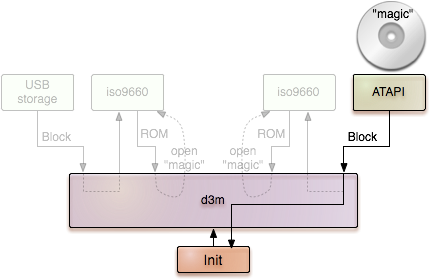
Once d3m observes a drivers that is able to successfully access the magic file, it keeps the driver and announces the driver's service to its own parent. For the system outside of d3m, the probing procedure is completely transparent. D3m appears to be just a service that always provides the valid block session for the boot medium.
|
The network device drivers that we ported from the iPXE project cover the range of most common wired network adaptors, in particular the E1000 family. But we cannot presume that a computer running the live system comes equipped with one of the supported devices. If no supported network card could be detected the driver would simply fail. Applications requesting a NIC session would block until a NIC service becomes available, which won't happen. To prevent this situation, d3m wraps the NIC driver and provides a dummy NIC service in the event the drivers fails. This way, the client application won't block infinitely but receive an error on the first attempt to use the NIC.
ACPI support
To accommodate kernels like Fiasco.OC or NOVA that take advantage of x86's APIC, we have introduced a simple ACPI parser located at os/src/drivers/acpi. The server traverses the ACPI tables and sets the interrupt line of devices within the PCI config space to the GSIs found in the ACPI tables. Internally it uses Genode's existing PCI driver as a child process for performing PCI access and, in turn, announces a PCI service itself.
For obtaining the IRQ routing information from the ACPI tables without employing a full-blown ACPI interpreter, the ACPI driver uses an ingenious technique invented by Bernhard Kauer, which is described in the following paper:
- ATARE - ACPI Tables and Regular Expressions
-
TU Dresden technical report TUD-FI09-09, Dresden, Germany, August 2009
- Usage
Start the acpi_drv in your Genode environment. Do not start the pci_drv since this will be used as a slave of the acpi_drv. You still must load the pci_drv in your boot loader. To integrate the ACPI driver into your boot configuration, you may take the following snippet as reference:
<start name="acpi">
<resource name="RAM" quantum="2M"/>
<binary name="acpi_drv"/>
<provides><service name="PCI"/></provides>
<route>
<service name="ROM"> <parent/> </service>
<any-service> <any-child/> <parent/> </any-service>
</route>
</start>
- Limitations and known issues
Currently there is no interface to set the interrupt mode for core's IRQ sessions (e.g., level or edge triggered). This is required by Fiasco.OCs kernel interface. We regard this as future work.
Platform support
Fiasco.OC microkernel
The support for the Fiasco.OC base platform is still lacking proper handling for releasing resources such as kernel capabilities. Although this is a known issue, we underestimated the reach of the problem when Genode's signal API is used. Each emitted signal happens to consume one kernel capability within core, ultimately leading to a resource outage when executing signal-intensive code such as the packet-stream interface. The current release comes with an interim solution. To remedy the acute problem, we extended the Capability_allocator class with the ability to register the global ID of a Genode capability so that the ID gets associated with a process-local kernel capability. Whenever a Genode capability gets unmarshalled from an IPC message, the capability-allocator is asked, with the global ID as key, whether the kernel-cap already exists. This significantly reduces the waste of kernel-capability slots.
To circumvent problems of having one and the same ID for different kernel objects, the following problems had to be solved:
-
Replace pseudo IDs with unique ones from core's badge allocator
-
When freeing a session object, free the global ID after unmapping the kernel object, otherwise the global ID might get re-used in some process and the registry will find a valid but wrong capability for the ID
Because core aggregates all capabilities of all different processes, its capability registry needs much more memory compared to a regular process. By parametrizing capability allocators differently for core and non-core processes, the global memory overhead for capability registries is kept at a reasonable level.
Please note that this solution is meant as an interim fix until we have resolved the root of the problem, which is the proper tracking and releasing of capability selectors.
Linux
Linux is one of the two original base platforms of Genode. The original intension behind supporting Linux besides a microkernel was to facilitate portability of the API design and to have a convenient testing environment for platform-independent code. Running Genode in the form of a bunch of plain Linux processes has become an invaluable feature for our fast-paced development.
To our delight, we lately discovered that the use of running Genode on Linux can actually go far beyond this original incentive. Apparently, on Linux, the framework represents an equally powerful component framework as on the other platforms. Hence, Genode has the potential to become an attractive option for creating complex component-based user-level software on Linux.
For this intended use, however, the framework has to fulfill the following additional requirements:
-
Developers on Linux expect that their components integrate seamlessly with their existing library infrastructure including all shared libraries installed on Linux.
-
The use of a custom tool chain is hard to justify to developers who regard Genode merely as an application framework. Hence, a way to use the normal tool chain as installed on the Linux host system is desired.
-
Application developers are accustomed with using GDB for debugging and expect that GDB can be attached to an arbitrary Genode program in an intuitive way.
Genode's original support for Linux as base platform did not meet those expectations. Because Genode's libc would ultimately collide with the Linux glibc, Genode is built with no glibc dependency at all. It talks to the kernel directly using custom kernel bindings. In particular, Genode threads are created directly via the clone() system call and thread-local storage (TLS) is managed in the same way as for the other base platforms. This has two implications. First, because Genode's TLS mechanism is different than the Linux TLS mechanism, Genode cannot be built with the normal host tool chain. This compiler would generate code that would simply break on the first attempt to use TLS. We solved this problem with our custom tool chain, which is configured for Genode's needs. The second implication is that GDB is not able to handle threads created differently than those created via the pthread library. Even though GDB can be attached to each thread individually, the debugger would not correctly handle a multi-threaded Genode process as a multi-threaded Linux program. With regard to the use of Linux shared libraries, Genode used to support a few special programs that used both the Genode API and Linux libraries. Those programs (called hybrid Linux/Genode programs) were typically pseudo device drivers that translate a Linux API to a Genode service. For example, there exists a framebuffer service that uses libSDL as back end. Because those programs were a rarity, the support by the build system for such hybrid targets was rather poor.
Fortunately, all the problems outlined above could be remedied pretty easily. It turns out that our custom libc is simply not relevant when Genode is used as plain application framework on Linux. For this intended use, we always want to use the host's normal libc. This way, the sole reason for using plain system calls instead of the pthread library vanishes, which, in turn, alleviates the need for a custom tool chain. Genode threads are then simply pthreads compatible with the TLS code as emitted by the host compiler and perfectly recognised by GDB. With the surprisingly little effort of creating a new implementation of Genode's thread API to target pthreads instead of using syscalls, we managed to provide a decent level of support for using Genode as user-level component framework on Linux.
These technical changes alone, however, are not sufficient to make Genode practical for real-world use. As stated above, the few hybrid Linux/Genode programs used to be regarded as some leprous artifacts. When using Genode as Linux application framework, however, this kind of programs are becoming the norm rather than an exception. For this reason, we introduced new support for such hybrid programs into the build system. By listing the lx_hybrid library in the LIBS declaration of a target, this target magically becomes a hybrid Linux/Genode program. It gets linked to the glibc and uses pthreads instead of direct syscalls. Furthermore, host libraries can be linked to the program by stating their respective names in the LX_LIBS variable. For an example, please refer to the libSDL-based framebuffer at os/src/drivers/framebuffer/sdl/target.mk.
To enforce the build of all targets as hybrid Linux/Genode programs, the build system features the alyways_hybrid SPEC value. To make it easy to create a build directory with all targets forced to be hybrid, we have added the new lx_hybrid_x86 platform to the create_builddir tool.
OKL4
- Sending an invalid-opcode exception IPC on OKL4
When an invalid opcode gets executed, OKL4 switches to the kernel debugger console instead of sending an exception IPC to the userland. We fixed this problem by removing the code that invokes the debugger console from the kernel.
- Hard-wire OKL4 elfweaver to Python 2
Recent Linux distributions use Python version 3 by default. But OKL4's elfweaver is not compatible with this version of Python. For this reason, we introduced a patch for pinning the Python version used by elfweaver to version 2.
Both patches get automatically applied when preparing the base-okl4 repository via make prepare.
Build system and tools
- Facility for explicitly building all libraries
During its normal operation, the build system creates libraries as mere side effects of building targets. There is no way to explicitly trigger the build of libraries only. However, in some circumstances (for example for testing the thorough build of all libraries), a mechanism for explicitly building libraries would be convenient. Hence we introduced this feature in the form of the pseudo target located at base/src/lib/target.mk. By issuing make lib in a build directory, this target triggers the build of all libraries available for the given platform.