
Release notes for the Genode OS Framework 13.08
The release of version 13.08 marks the 5th anniversary of the Genode OS framework. We celebrate this anniversary with the addition of three major features that we have much longed for, namely the port of Qt5 to Genode, profound multi-processor support, and a light-weight event tracing framework. Additionally, the new version comes with new device drivers for SATA 3.0 and power management for the Exynos-5 SoC, improved virtualization support on NOVA on x86, updated kernels, and integrity checks for downloaded 3rd-party source code.
Over the course of the past five years, Genode's development was primarily motivated by adding and cultivating features to make the framework fit for as many application areas as possible. Now that we have a critical mass of features, the focus on mere functionality does not suffice anymore. The question of what Genode can do ultimately turns into the question of how well Genode can do something: How stable is a certain workload? How does networking perform? How does it scale to multi-processor systems? Because we are lacking concise answers to these kind of questions, we have to investigate.
When talking about stability, our recently introduced automated testing infrastructure makes us more confident than ever. Each night, over 200 automated tests are performed, covering various kernels and several hardware platforms. All those tests are publicly available in the form of so-called run scripts and are under continues development.
Regarding performance investigations, recently we have begun to benchmark application performance focusing on network throughput. Interestingly, our measurements reveal significant differences between the used kernels, but also shortcomings in our software stack. For example, currently we see that our version of lwIP performs poorly with gigabit networking. To thoroughly investigate such performance issues, the current version adds support for tracing the behaviour of Genode components. This will allow us to get a profound understanding of all inter-component interaction that are on the critical path for the performance of complex application-level workloads. Thanks to the Genode architecture, we could come up with a strikingly simple, yet powerful design for a tracing facility. Section Light-weight event tracing explains how it works.
When it comes to multi-processor scalability, we used to shy away from such inquiries because, honestly, we haven't paid much consideration to it. This view has changed by now. With the current release, we implemented the management of CPU affinities right into the heart of the framework, i.e., Genode's session concept. Additionally, we cracked a damn hard nut by enabling Genode to use multiple CPUs on the NOVA hypervisor. This kernel is by far the most advanced Open-Source microkernel for the x86 architecture. However, NOVA's MP model seemed to inherently contradict with the API design of Genode. Fortunately, we found a fairly elegant way to go forward and we're able to tame the beast. Section Enhanced multi-processor support goes into more detail.
Functionality-wise, we always considered the availability of Qt on Genode as a big asset. With the current release, we are happy to announce that we finally made the switch from Qt4 to Qt5. Section Qt5 available on all kernels gives insights into the challenges that we faced during porting work.
In addition to those highlights, the new version comes with improvements all over the place. To name a few, there are improved support for POSIX threads, updated device drivers, an updated version of the Fiasco.OC kernel and L4Linux, and new device drivers for Exynos-5. Finally, the problem of verifying the integrity of downloaded 3rd-party source codes has been addressed.
Qt5 available on all kernels
Since its integration with Genode version 9.02, Qt4 is regarded as one of the most prominent features of the framework. For users, combining Qt with Genode makes the world of sophisticated GUI-based end-user applications available on various microkernels. For Genode developers, Qt represents by far the most complex work load natively executed on top of the framework API, thereby stressing the underlying system in any way imaginable. We have been keeping an eye on Qt version 5 for a while and highly anticipate the direction where Qt is heading. We think that the time is right to leave Qt4 behind to embrace Qt5 for Genode.
For the time being, both Qt4 and Qt5 are available for Genode, but Qt4 is declared as deprecated and will be removed with the upcoming version 13.11. Since Qt5 is almost API compatible to Qt4, the migration path is relatively smooth. So we recommend to move your applications over to Qt5 during the next release cycle.
In the following, we briefly describe the challenges we faced while adding Qt5 support to Genode, point you to the place where to find Qt5 in the source tree, and give quick-start instructions for getting a Qt5 application scenario running.
We found that the biggest architectural difference between version 4 and version 5 is the use of the so-called Qt Platform Abstraction (QPA) interface, which replaces the former Qt Window System (QWS).
Moving from QWS to QPA
With Qt4, we relied on QWS to perform the window handling. A Qt4 application used to create a session to Genode's GUI server (called nitpicker) and applied its graphical output onto a virtual framebuffer. The virtual framebuffer was not visible per se. To make portions of the virtual framebuffer visible on screen, the application had to create so-called nitpicker views. A view is a rectangular area of the physical screen that displays a (portion of) the virtual framebuffer. The position, size, and stacking order of views is managed by the application. For each Qt window, the application would simply create a corresponding nitpicker view and maintain the consistency of the view with the geometry of the Qt window. Even though each Qt application seemingly operated as a full-screen application with the windows managed by the application-local QWS, the use of nitpicker views still allowed the integration of any number of Qt applications into one windowed environment.
With the advent of compositing window managers, the typical way of how an application interacts with the window system of the OS changed. Whereas old-generation GUIs relied on a tight interplay of the application with the window server in order to re-generate newly exposed window regions whenever needed (e.g., revealing the window content previously covered by another window), the modern model of a GUI server keeps all pixels of all windows in memory regardless of whether the window is visible or covered by other windows. The use of one pixel buffer per window seems wasteful with respect to memory usage when many large windows are overlapping each other. On the other hand, this technique largely simplifies GUI servers and makes the implementation of fancy effects, like translucent windows, straight forward. Since memory is cheap, the Qt developers abandoned the old method and fully embraced the buffer-per-window approach by the means of QPA.
For Genode, we faced the challenge that we don't have a window server in the usual sense. With nitpicker, we have a GUI server, but with a more radical design. In particular, nitpicker leaves the management of window geometries and stacking to the client. In contrast, QPA expects the window system to provide both means for a user to interactively change the window layout and a way for an application to define the properties (such as the geometry, title, and visibility) of its windows. The obviously missing piece was the software component that deals with window controls. Fortunately, we already have a bunch of native nitpicker applications that come with client-side window controls, in particular the so-called liquid framebuffer (liquid_fb). This nitpicker client presents a virtual framebuffer in form of a proper window on screen and, in turn, provides a framebuffer and input service. These services can be used by other Genode processes, for example, another nested instance of nitpicker. This way, liquid_fb lends itself to be the interface between the nitpicker GUI server and QPA.
For each QPA window, the application creates a new liquid_fb instance as a child process. The liquid_fb instance will request a dedicated nitpicker session, which gets routed through the application towards the parent of the application, which eventually routes the request to the nitpicker GUI server. Finally, the liquid_fb instance announces its input and framebuffer services to its parent, which happens to be the application. Now, the application is able to use those services in order to access the window. Because the liquid_fb instances are children of the application, the application can impose control over those. In particular, it can update the liquid_fb configuration including the window geometry and title at any time. Thanks to Genode's dynamic reconfiguration mechanism, the liquid_fb instances are able to promptly respond to such reconfigurations.
Combined, those mechanisms give the application a way to receive user input (via the input services provided by the liquid_fb instances), perform graphical output (via the virtual framebuffers provided by the liquid_fb instances), and define window properties (by dynamically changing the respective liquid_fb configurations). At the same time, the user can use liquid_fb's window controls to move, stack, and resize application windows as expected.
|
Steps of porting Qt5
Besides the switch to QPA, the second major change was related to the build system. For the porting work, we use a Linux host system to obtain the starting point for the build rules. The Qt4 build system would initially generate all Makefiles, which could be inspected and processed at once. In contrast, Qt5 generates Makefiles during the build process whenever needed. When having configured Qt for Genode, however, the build on Linux will ultimately fail. So the much-desired intermediate Makefiles won't be created. The solution was to have configure invoke qmake -r instead of qmake. This way, qmake project files will be processed recursively. A few additional tweaks were needed to avoid qmake from backing out because of missing dependencies (qt5_configuration.patch). To enable the build of the Qt tools out of tree, qmake-specific files had to be slightly adapted (qt5_tools.patch). Furthermore, qtwebkit turned out to use code-generation tools quite extensively during the build process. On Genode, we perform this step during the make prepare phase when downloading and integrating the Qt source code with the Genode source tree.
For building Qt5 on Genode, we hit two problems. First, qtwebkit depends on the ICU (International Components for Unicode) library, which was promptly ported and can be found in the libports repository. Second, qtwebkit apparently dropped the support of the QThread API in favor of POSIX-thread support only. For this reason, we had to extend the coverage of Genode's pthread library to fulfill the needs of qtwebkit.
Once built, we entered the territory of debugging problems at runtime.
-
We hit a memory-corruption problem caused by an assumption of QArrayData with regard to the alignment of memory allocated via malloc. As a work-around, we weakened the assumptions to 4-byte alignment (qt5_qarraydata.patch).
-
Page faults in QWidgetAnimator caused by use-after-free problems. Those could be alleviated by adding pointer checks (qt5_qwidgetanimator.patch).
-
Page faults caused by the slot function QWidgetWindow::updateObjectName() with a this pointer of an incompatible type QDesktopWidget*. As a workaround, we avoid this condition by delegating the QWidgetWindow::event() that happened to trigger the slot method to QWindow (base class of QWidgetWindow) rather than to a QDesktopWidget member (qt5_qwidgetwindow.patch).
-
We observed that Arora presented web sites incomplete, or including HTTP headers. During the evaluation of HTTP data, a signal was sent to another thread, which activated a "user provided download buffer" for optimization purposes. On Linux, the receiving thread was immediately scheduled and everything went fine. However, on some kernels used by Genode, scheduling is different, so that the original thread continued to execute a bit longer, ultimately triggering a race condition. As a workaround, we disabled the "user provided download buffer" optimization.
-
Page faults in the JavaScript engine of Webkit. The JavaScript RegExp.exec() function returned invalid string objects. We worked around this issue by deactivating the JIT compiler for the processing of regular expressions (ENABLE_YARR_JIT).
The current state of the Qt5 port is fairly complete. It covers the core, gui, jscore, network, script, scriptclassic, sql, ui, webcore, webkit, widgets, wtf, and xml modules. That said, there are a few known limitations and differences compared to Qt4. First, the use of one liquid_fb instance per window consumes more memory compared to the use of QWS in Qt4. Furthermore, external window movements are not recognized by our QPA implementation yet. This can cause popup menus to appear at unexpected positions. Key repeat is not yet handled. The QNitpickerViewWidget is not yet adapted to Qt5. For this reason, qt_avplay is not working yet.
Test drive
Unlike Qt4, which was hosted in the dedicated qt4 repository, Qt5 is integrated in the libports repository. It can be downloaded and integrated into the Genode build system by issuing make prepare from within the libports repository. The Qt5 versions of the known Qt examples are located at libports/src/app/qt5. Ready-to-use run scripts for those examples are available at libports/run.
Migration away from Qt4 to Qt5
The support for Qt4 for Genode has been declared as deprecated. By default, it's use is inhibited to avoid name aliasing problems between both versions. Any attempt to build a qt4-based target will result in a message:
Skip target app/qt_launchpad because it requires qt4_deprecated
To re-enable the use of Qt4, the SPEC value qt4_deprecated must be defined manually for the build directory:
echo "SPECS += qt4_deprecated" >> etc/specs.conf
We will keep the qt4 repository in the source tree during the current release cycle. It will be removed with version 13.11.
Light-weight event tracing
With Genode application scenarios getting increasingly sophisticated, the need for thorough performance analysis has come into spotlight. Such scenarios entail the interaction of many components. For example, with our recent work on optimizing network performance, we have to consider several possible attack points:
-
Device driver: Is the device operating in the proper mode? Are there CPU-intensive operations such as allocations within the critical path?
-
Interface to the device driver: How frequent are context switches between client and device driver? Is the interface designed appropriately for the access patterns?
-
TCP/IP stack: How does the data flow from the raw packet level to the socket level? How dominant are synchronization costs between the involved threads? Are there costly in-band operations performed, e.g., dynamic memory allocations per packet?
-
C runtime: How does integration of the TCP/IP stack with the C runtime work, for example how does the socket API interfere with timeout handling during select calls?
-
Networking application
-
Timer server: How often is the timer consulted by the involved components? What is the granularity of timeouts and thereby the associated costs for handling them?
-
Interaction with core: What is the profile of the component's interaction with core's low-level services?
This example is just an illustration. Most real-world performance-critical scenarios have a similar or even larger scope. With our traditional tools, it is hardly possible to gather a holistic view of the scenario. Hence, finding performance bottlenecks tends to be a series of hit-and-miss experiments, which is a tiresome and costly endeavour.
To overcome this situation, we need the ability to gather traces of component interactions. Therefore, we started investigating the design of a tracing facility for Genode one year ago while posing the following requirements:
-
Negligible impact on the performance, no side effects: For example, performing a system call per traced event is out of question because this would severely influence the flow of control (as the system call may trigger the kernel to take a scheduling decision) and the execution time of the traced code, not to speak of the TLB and cache footprint.
-
Kernel independence: We want to use the same tracing facility across all supported base platforms.
-
Accountability of resources: It must be clearly defined where the resources for trace buffers come from. Ideally, the tracing tool should be able to dimension the buffers according to its needs and, in turn, pay for the buffers.
-
Suitable level of abstraction: Only if the trace contains information at the right level of abstraction, it can be interpreted for large scenarios. A counter example is the in-kernel trace buffer of the Fiasco.OC kernel, which logs kernel-internal object names and a few message words when tracing IPC messages, but makes it almost impossible to map this low-level information to the abstraction of the control flow of RPC calls. In contrast, we'd like to capture the names of invoked RPC calls (which is an abstraction level the kernel is not aware of). This requirement implies the need to have useful trace points generated automatically. Ideally those trace points should cover all interactions of a component with the outside world.
-
(Re-)definition of tracing policies at runtime: The question of which information to gather when a trace point is passed should not be solely defined at compile time. Instead of changing static instrumentations in the code, we'd prefer to have a way to configure the level of detail and possible conditions for capturing events at runtime, similar to dtrace. This way, a series of different hypotheses could be tested by just changing the tracing policy instead of re-building and rebooting the entire scenario.
-
Straight-forward implementation: We found that most existing tracing solutions are complicated. For example, dtrace comes with a virtual machine for the sandboxed interpretation of policy code. Another typical source of complexity is the synchronization of trace-buffer accesses. Because for Genode, low TCB complexity is of utmost importance, the simplicity of the implementation is the prerequisite to make it an integral part of the base system.
-
Support for both online and offline analysis of traces.
We are happy to report to have come up with a design that meets all those requirements thanks to the architecture of Genode. In the following, we present the key aspects of the design.
The tracing facility comes in the form of a new TRACE service implemented in core. Using this service, a TRACE client can gather information about available tracing subjects (existing or no-longer existing threads), define trace buffers and policies and assign those to tracing subjects, obtain access to trace-buffer contents, and control the tracing state of tracing subjects. When a new thread is created via a CPU session, the thread gets registered at a global registry of potential tracing sources. Each TRACE service manages a session-local registry of so-called trace subjects. When requested by the TRACE client, it queries new tracing sources from the source registry and obtains references to the corresponding threads. This way, the TRACE session becomes able to control the thread's tracing state.
To keep the tracing overhead as low as possible, we assign a separate trace buffer to each individually traced thread. The trace buffer is a shared memory block mapped to the virtual address space of the thread's process. Capturing an event comes down to a write operation into the thread-local buffer. Because of the use of shared memory for the trace buffer, no system call is needed and because the buffer is local to the traced thread, there is no need for synchronizing the access to the buffer. When no tracing is active, a thread has no trace buffer. The buffer gets installed only when tracing is started. The buffer is not installed magically from the outside of the traced process but from the traced thread itself when passing a trace point. To detect whether to install a new trace buffer, there exists a so-called trace-control dataspace shared between the traced process and its CPU service. This dataspace contains control bits for each thread created via the CPU session. The control bits are evaluated each time a trace point is passed by the thread. When the thread detects a change of the tracing state, it actively requests the new trace buffer from the CPU session and installs it into its address space. The same technique is used for loading the code for tracing policies into the traced process. The traced thread actively checks for policy-version updates by evaluating the trace-control bits. If an update is detected, the new policy code is requested from the CPU session. The policy code comes in the form of position-independent code, which gets mapped into the traced thread's address space by the traced thread itself. Once mapped, a trace point will call the policy code. When called, the policy module code returns the data to be captured into the trace buffer. The relationship between the trace monitor (the client of TRACE service), core's TRACE service, core's CPU service, and the traced process is depicted in Figure 2.
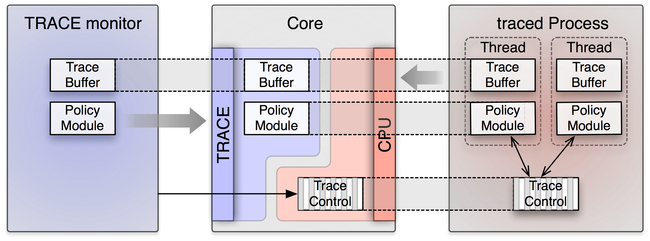
|
There is one trace-control dataspace per CPU session, which gets accounted to the CPU session's quota. The resources needed for the trace-buffer dataspaces and the policy dataspaces are paid-for by the TRACE client. On session creation, the TRACE client can specify the amount of its own RAM quota to be donated to the TRACE service in core. This enables the TRACE client to define trace buffers and policies of arbitrary sizes, limited only by its own RAM quota.
In Genode, the interaction of a process with its outside world is characterized by its use of inter-process communication, namely synchronous RPC, signals, and access to shared memory. For the former two types of inter-process communication, Genode generates trace points automatically. RPC clients generate trace points when an RPC call is issued and when a call returned. RPC servers generate trace points in the RPC dispatcher, capturing incoming RPC requests as well as RPC replies. Thanks to Genode's RPC framework, we are able to capture the names of the RPC functions in the RPC trace points. This information is obtained from the declarations of the RPC interfaces. For signals, trace points are generated for submitting and receiving signals. Those trace points form a useful base line for gathering tracing data. In addition, manual trace points can be inserted into the code.
State of the implementation
The implementation of Genode's tracing facility is surprisingly low complex. The addition to the base system (core as well as the base library) are merely 1500 lines of code. The mechanism works across all base platforms.
Because the TRACE client provides the policy code and trace buffer to the traced thread, the TRACE client imposes ultimate control over the traced thread. In contrast to dtrace, which sandboxes the trace policy, we express the policy module in the form of code executed in the context of the traced thread. However, in contrast to dtrace, such code is never loaded into a large monolithic kernel, but solely into the individually traced processes. So the risk of a misbehaving policy is constrained to the traced process.
In the current form, the TRACE service of core should be considered as a privileged service because the trace-subject namespace of each session contains all threads of the system. Therefore, TRACE sessions should be routed only for trusted processes. In the future, we plan to constrain the namespaces for tracing subjects per TRACE session.
The TRACE session interface is located at base/include/trace_session/. A simple example for using the service is available at os/src/test/trace/ and is accompanied with the run script os/run/trace.run. The test demonstrates the TRACE session interface by gathering a trace of a thread running locally in its address space.
Enhanced multi-processor support
Multi-processor (MP) support is one of those features that most users take for granted. MP systems are so ubiquitous, even on mobile platforms, that a limitation to utilizing a single CPU only is almost a fallacy. That said, MP support in operating systems is hard to get right. For this reason, we successively deferred the topic on the agenda of Genode's road map.
For some base platforms such as the Linux or Codezero kernels, Genode always used to support SMP because the kernel would manage the affinity of threads to CPU cores transparently to the user-level process. So on these kernels, there was no need to add special support into the framework.
However, on most microkernels, the situation is vastly different. The developers of such kernels try hard to avoid complexity in the kernel and rightfully argue that in-kernel affinity management would contribute to kernel complexity. Another argument is that, in contrast to monolithic kernels that have a global view on the system and an "understanding" of the concerns of the user processes, a microkernel is pretty clueless when it comes to the roles and behaviours of individual user-level threads. Not knowing whether a thread works as a device driver, an interactive program, or a batch process, the microkernel is not in the position to form a reasonably useful model of the world, onto which it could intelligently apply scheduling and affinity heuristics. In fact, from the perspective of a microkernel, each thread does nothing else than sending and receiving messages, and causing page faults.
For these reasons, microkernel developers tend to provide the bootstrapping procedure for the physical CPUs and a basic mechanism to assign threads to CPUs but push the rest of the problem to the user space, i.e., Genode. The most straight-forward way would make all physical CPUs visible to all processes and require the user or system integrator to assign physical CPUs when a thread is created. However, on the recursively structured Genode system, we virtualize resources at each level, which calls for a different approach. Section Management of CPU affinities explains our solution.
When it comes to inter-process communication on MP systems, there is a certain diversity among the kernel designs. Some kernels allow the user land to use synchronous IPC between arbitrary threads, regardless of whether both communication partners reside on the same CPU or on two different CPUs. This convenient model is provided by Fiasco.OC. However, other kernels do not offer any synchronous IPC mechanism across CPU cores at all, NOVA being a poster child of this school of thought. If a user land is specifically designed for a particular kernel, those peculiarities can be just delegated to the application developers. For example, the NOVA user land called NUL is designed such that a recipient of IPC messages spawns a dedicated thread on each physical CPU. In contrast, Genode is meant to provide a unified API that works well across various different kernels. To go forward, we had four options:
-
Not fully supporting the entity of API semantics across all base platforms. For example, we could stick with the RPC API for synchronous communication between threads. Programs just would happen to fail on some base platforms when the called server resides on a different CPU. This would effectively push the problem to the system integrator. The downside would be the sacrifice of Genode's nice feature that a program developed on one kernel usually works well on other kernels without any changes.
-
Impose the semantics provided by the most restrictive kernel onto all users of the Genode API. Whereas this approach would facilitate that programs behave consistently across all base platforms, the restrictions would be artificially imposed onto all Genode users, in particular the users of kernels with less restrictions. Of course, we don't change the Genode API lightheartedly, which attributes to our hesitance to go into this direction.
-
Hiding kernel restrictions behind the Genode API. This approach could come in many different shapes. For example, Genode could transparently spawn a thread on each CPU when a single RPC entrypoint gets created, following the model of NUL. Or Genode could emulate synchronous IPC using the core process as a proxy.
-
Adapting the kernel to the requirements of Genode. That is, persuading kernel developers to implement the features we find convenient, i.e., adding a cross-CPU IPC feature to NOVA. History shows that our track record in doing that is not stellar.
Because each of those options is like opening a different can of worms, we used to defer the solution of the problem. Fortunately, however, we finally kicked off a series of practical experiments, which led to a fairly elegant solution, which is detailed in Section Adding multi-processor support to Genode on NOVA.
Management of CPU affinities
In line with our experience of supporting real-time priorities in version 10.02, we were seeking a way to express CPU affinities such that Genode's recursive nature gets preserved and facilitated. Dealing with physical CPU numbers would contradict with this mission. Our solution is based on the observation that most MP systems have topologies that can be represented on a two-dimensional coordinate system. CPU nodes close to each other are expected to have closer relationship than distant nodes. In a large-scale MP system, it is natural to assign clusters of closely related nodes to a given workload. Genode's architecture is based on the idea to recursively virtualize resources and thereby lends itself to the idea to apply this successive virtualization to the problem of clustering CPU nodes.
In our solution, each process has a process-local view on a so-called affinity space, which is a two-dimensional coordinate space. If the process creates a new subsystem, it can assign a portion of its own affinity space to the new subsystem by imposing a rectangular affinity location to the subsystem's CPU session. Figure 3 illustrates the idea.
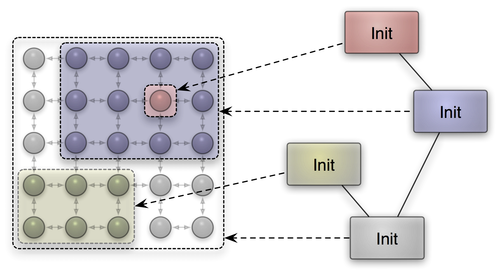
|
Following from the expression of affinities as a rectangular location within a process-local affinity space, the assignment of subsystems to CPU nodes consists of two parts, the definition of the affinity space dimensions as used for the process and the association of sub systems with affinity locations (relative to the affinity space). For the init process, the affinity space is configured as a sub node of the config node. For example, the following declaration describes an affinity space of 4x2:
<config> ... <affinity-space width="4" height="2" /> ... </config>
Subsystems can be constrained to parts of the affinity space using the <affinity> sub node of a <start> entry:
<config>
...
<start name="loader">
<affinity xpos="0" ypos="1" width="2" height="1" />
...
</start>
...
</config>
As illustrated by this example, the numbers used in the declarations for this instance of the init process are not directly related to physical CPUs. If the machine has just two cores, init's affinity space would be mapped to the range 0,1 of physical CPUs. However, in a machine with 16x16 CPUs, the loader would obtain 8x8 CPUs with the upper-left CPU at position (4,0). Once a CPU session got created, the CPU client can request the physical affinity space that was assigned to the CPU session via the Cpu_session::affinity() function. Threads of this CPU session can be assigned to those physical CPUs via the Cpu_session::affinity() function, specifying a location relative to the CPU-session's affinity space.
Adding multi-processor support to Genode on NOVA
The NOVA kernel has been supporting MP systems for a long time. However Genode did not leverage this capability until now. The main reason was that the kernel does not provide - intentionally by the kernel developer - the possibility to perform synchronous IPC between threads residing on different CPUs.
To cope with this situation, Genode servers and clients would need to make sure to have at least one thread on a common CPU in order to communicate. Additionally, shared memory and semaphores could be used to communicate across CPU cores. Both options would require rather fundamental changes to the Genode base framework and the API. An exploration of this direction should in any case be pursued in evolutionary steps rather than as one big change, also taking into account that other kernels do not impose such hard requirements on inter-CPU communication. To tackle the challenge, we conducted a series of experiments to add some kind of cross-CPU IPC support to Genode/NOVA.
As a general implication of the missing inter-CPU IPC, messages between communication partners that use disjoint CPUs must take an indirection through a proxy process that has threads running on both CPUs involved. The sender would send the message to a proxy thread on its local CPU, the proxy process would transfer the message locally to the CPU of the receiver by using process-local communication, and the proxy thread on the receiving CPU would deliver the message to the actual destination. We came up with three options to implement this idea prototypically:
-
Core plays the role of the proxy because it naturally has access to all CPUs and emulates cross-CPU IPC using the thread abstractions of the Genode API.
-
Core plays the role of the proxy but uses NOVA system calls directly rather than Genode's thread abstraction.
-
The NOVA kernel acts as the proxy and emulates cross-CPU IPC directly in the kernel.
After having implemented the first prototypes, we reached the following conclusions.
For options 1 and 2 where core provides this service: If a client can not issue a local CPU IPC, it asks core - actually the pager of the client thread - to perform the IPC request. Core then spawns or reuses a proxy thread on the target CPU and performs the actual IPC on behalf of the client. Option 1 and 2 only differ in respect to code size and the question to whom to account the required resources - since a proxy thread needs a stack and some capability selectors.
As one big issue for option 1 and 2, we found that in order to delegate capabilities during the cross-CPU IPC, core has to receive capability mappings to delegate them to the target thread. However, core has no means to know whether the capabilities must be maintained in core or not. If a capability is already present in the target process, the kernel would just translate the capability to the target's capability name space. So core wouldn't need to keep it. In the other case where the target receives a prior unknown capability, the kernel creates a new mapping. Because the mapping gets established by the proxy in core, core must not free the capability. Otherwise, the mapping would disappear in the target process. This means that the use of core as a proxy ultimately leads to leaking kernel resources because core needs to keep all transferred capabilities, just for the case a new mapping got established.
For option 3, the same general functionality as for option 1 and 2 is implemented in the kernel instead of core. If a local CPU IPC call fails because of a BAD_CPU kernel error code, the cross-CPU IPC extension will be used. The kernel extension creates - similar as to option 1 and 2 - a semaphore (SM), a thread (EC), and a scheduling context (SC) on the remote CPU and lets it run on behalf of the caller thread. The caller thread gets suspended by blocking on the created semaphore until the remote EC has finished the IPC. The remote proxy EC reuses the UTCB of the suspended caller thread as is and issues the IPC call. When the proxy EC returns, it wakes up the caller via the semaphore. Finally, the proxy EC and SC de-schedule themselves and the resources get to be destroyed later on by the kernel's RCU mechanism. Finally, when the caller thread got woken up, it takes care to initiate the deconstruction of the semaphore.
The main advantage of option 3 compared to options 1 and 2 is that we don't have to keep and track the capability delegations during a cross-CPU IPC. Furthermore, we do not have potentially up to two additional address space switches per cross-CPU IPC (from client to core and core to the server). Additionally, the UTCB of the caller is reused by the proxy EC and does not need to be allocated separately as for option 1 and 2.
For these reasons, we decided to go for the third option. From Genode's API point of view, the use of cross-CPU IPC is completely transparent. Combined with the affinity management described in the previous section, Genode/NOVA just works on MP systems. As a simple example for using Genode on MP systems, there is a ready-to-use run script available at base/run/affinity.run.
Base framework
Affinity propagation in parent, root, and RPC entrypoint interfaces
To support the propagation of CPU affinities with session requests, the parent and root interfaces had to be changed. The Parent::Session and Root::Session take the affinity of the session as a new argument. The affinity argument contains both the dimensions of the affinity space used by the session and the session's designated affinity location within the space. The corresponding type definitions can be found at base/affinity.h.
Normally, the Parent::Session function is not used directly but indirectly through the construction of a so-called connection object, which represents an open session. For each session type there is a corresponding connection type, which takes care of assembling the session-argument string by using the Connection::session() convenience function. To maintain API compatibility, we kept the signature of the existing Connection::session() function using a default affinity and added a new overload that takes the affinity as additional argument. Currently, this overload is used in cpu_session/connection.h.
For expressing the affinities of RPC entrypoints to CPUs within the affinity space of the server process, the Rpc_entrypoint takes the desired affinity location of the entrypoint as additional argument. For upholding API compatibility, the affinity argument is optional.
CPU session interface
The CPU session interface underwent changes to accommodate the new event tracing infrastructure and the CPU affinity management.
Originally the Cpu_session::num_cpus() function could be used to determine the number of CPUs available to the session. This function has been replaced by the new affinity_space function, which returns the bounds of the CPU session's physical affinity space. In the simplest case of an SMP machine, the affinity space is one-dimensional where the width corresponds to the number of CPUs. The affinity function, which is used to bind a thread to a specified CPU, has been changed to take an affinity location as argument. This way, the caller can principally express the affiliation of the thread with multiple CPUs to guide load-balancing in a CPU service.
New TRACE session interface
The new event tracing mechanism as described in Section Light-weight event tracing is exposed to Genode processes in the form of the TRACE service provided by core. The new session interface is located under base/include/trace_session/. In addition to the new session interface, the CPU session interface has been extended with functions for obtaining the trace-control dataspace for the session as well as the trace buffer and trace policy for a given thread.
Low-level OS infrastructure
Event-driven operation of NIC bridge
The NIC bridge component multiplexes one physical network device among multiple clients. It enables us to multiplex networking on the network-packet level rather than the socket level and thereby take TCP/IP out of the critical software stack for isolating network applications. As it represents an indirection in the flow of all networking packets, its performance is important.
The original version of NIC bridge was heavily multi-threaded. In addition to the main thread, a timer thread, and a thread for interacting with the NIC driver, it employed one dedicated thread per client. By merging those flows of control into a single thread, we were able to significantly reduce the number of context switches and improve data locality. These changes reduced the impact of the NIC bridge on the packet throughput from 25% to 10%.
Improved POSIX thread support
To accommodate qtwebkit, we had to extend Genode's pthread library with working implementations of condition variables, mutexes, and thread-local storage. The implemented functions are attr_init, attr_destroy, attr_getstack, attr_get_np, equal, mutex_attr, mutexattr_init, mutexattr_destroy, mutexattr_settype, mutex_init, mutex_destroy, mutex_lock, mutex_unlock, cond_init, cond_timedwait, cond_wait, cond_signal, cond_broadcast, key_create, setspecific, and getspecific.
Device drivers
SATA 3.0 on Exynos 5
The previous release featured the initial version of our SATA 3.0 driver for the Exynos 5 platform. This driver located at os/src/drivers/ahci/exynos5 has reached a fully functional state by now. It supports UDMA-133 with up to 6 GBit/s.
For driver development, we set the goal to reach a performance equal to the Linux kernel. To achieve that goal, we had to make sure to operate the controller and the disks in the same ways as Linux does. For this reason, we modeled our driver closely after the behaviour of the Linux driver. That is, we gathered traces of I/O transactions to determine the initialization steps and the request patterns that Linux performs to access the device, and used those behavioral traces as a guide for our implementation. Through step-by-step analysis of the traces, we not only succeeded to operate the device in the proper modes, but we also found opportunities for further optimization, in particular regarding the error recovery implementation.
This approach turned out to be successful. We measured that our driver generally operates as fast (and in some cases even significantly faster) than the Linux driver on solid-state disks as well as on hard disks.
Dynamic CPU frequency scaling for Exynos 5
As the Samsung Exynos-5 SoC is primarily targeted at mobile platforms, power management is an inherent concern. Until now, Genode did not pay much attention to power management though. For example, we completely left out the topic from the scope of the OMAP4 support. With the current release, we took the first steps towards proper power management on ARM-based platforms in general, and the Exynos-5-based Arndale platform in particular.
First, we introduced a general interface to regulate clocks and voltages. Priorly, each driver did its own part of configuring clock and power control registers. The more device drivers were developed, the higher were the chances that they interfere when accessing those clock, or power units. The newly introduced "Regulator" interface provides the possibility to enable or disable, and to set or get the level of a regulator. A regulator might be a clock for a specific device (such as a CPU) or a voltage regulator. For the Arndale board, an exemplary implementation of the regulator interface exists in the form of the platform driver. It can be found at os/src/drivers/platform/arndale. Currently, the driver implements clock regulators for the CPU, the USB 2.0 and USB 3.0 host controller, the eMMC controller, and the SATA controller. Moreover, it provides power regulators for SATA, USB 2.0, and USB 3.0 host controllers. The selection of regulators is dependent on the availability of drivers for the platform. Otherwise it wouldn't be possible to test that clock and power state doesn't affect the device.
Apart from providing regulators needed by certain device drivers, we implemented a clock regulator for the CPU that allows changing the CPU frequency dynamically and thereby giving the opportunity to scale down voltage and power consumption. The possible values range from 200 MHz to 1.7 GHz whereby the last value isn't recommended and might provoke system crashes due to overheating. When using Genode's platform driver for Arndale it sets CPU clock speed to 1.6 GHz by default. When reducing the clock speed to the lowest level, we observed a power consumption reduction of approximately 3 Watt. Besides reducing dynamic power consumption by regulating the CPU clock frequency, we also explored the gating of the clock management and power management to further reduce power consumption.
With the CPU frequency scaling in place, we started to close all clock gates not currently in use. When the platform driver for the Arndale board gets initialized, it closes everything. If a device driver enables its clock regulator, all necessary clock gates for the device's clock are opened. This action saves about 0.7 Watt. The initial closing of all unnecessary power gates was much more effective. Again, everything not essential for the working of the kernel is disabled on startup. When a driver enables its power regulator, all necessary power gates for the device are opened. Closing all power gates saves about 2.6 Watt.
If we consider all measures taken to save power, we were able to reduce power consumption to about 59% without performance degradation. When measuring power consumption after boot up, setting the CPU clock to 1.6 GHz, and fully load both CPU cores without the described changes, we measured about 8 Watt. With the described power saving provisions enabled, we measured about 4.7 Watt. When further reducing the CPU clock frequency to 200 MHz, only 1.7 Watt were measured.
VESA driver moved to libports
The VESA framebuffer driver executes the initialization code located in VESA BIOS of the graphics card. As the BIOS code is for real mode, the driver uses the x86emu library from X11 as emulation environment. We updated x86emu to version 1.20 and moved the driver from the os repository to the libports repository as the library is third-party code. Therefore, if you want to use the driver, the libports repository has to be prepared (make -C <genode-dir>/libports prepare PKG=x86emu) and enabled in your etc/build.conf.
Runtime environments
Seoul (aka Vancouver) VMM on NOVA
Since we repeatedly received requests for using the Seoul respectively Vancouver VMM on NOVA, we improved the support for this virtualization solution on Genode. Seoul now supports booting from raw hard disk images provided via Genode's block session interface. Whether this image is actually a file located in memory, or it is coming directly from the hard disk, or just from a partition of the hard disk using Genode's part_blk service, is completely transparent thanks to Genode's architecture.
Additionally, we split up the one large Vancouver run script into several smaller Seoul run scripts for easier usage - e.g. one for disk, one for network testing, one for automated testing, and one we call "fancy". The latter resembles the former vancouver.run script using Genode's GUI to let the user start VMs interactively. The run scripts prefixed with seoul- can be found at ports/run. For the fancy and network scripts, ready-to-use VM images are provided. Those images are downloaded automatically when executing the run script for the first time.
L4Linux on Fiasco.OC
L4Linux has been updated from version 3.5.0 to Linux kernel version 3.9.0 thus providing support for contemporary user lands running on top of L4Linux on both x86 (32bit) and ARM platforms.
Noux runtime for Unix software
Noux is our way to use the GNU software stack natively on Genode. To improve its performance, we revisited the address-space management of the runtime to avoid redundant revocations of memory mappings when Noux processes are cleaned up.
Furthermore, we complemented the support for the Genode tool chain to cover GNU sed and GNU grep as well. Both packages are available at the ports repository.
Platforms
Fiasco.OC updated to revision r56
Fiasco.OC and the required L4RE parts have been updated to the current SVN revision (r56). For us, the major new feature is the support of Exynos SOCs in the mainline version of Fiasco.OC (www.tudos.org). Therefore Genode's implementation of the Exynos5250 platform could be abandoned leading to less maintenance overhead of Genode on Fiasco.OC.
Furthermore, Genode's multi-processor support for this kernel has been improved so that Fiasco.OC users benefit from the additions described in Section Enhanced multi-processor support.
NOVA updated
In the process of our work on the multi-processor support on NOVA, we updated the kernel to the current upstream version. Additionally, our customized branch (called r3) comes with the added cross-CPU IPC system call and improvements regarding the release of kernel resources.
Integrity checks for downloaded 3rd-party software
Even though Genode supports a large variety of 3rd-party software, its source-code repository contains hardly any 3rd-party source code. Whenever 3rd-party source code is needed, Genode provides automated tools for downloading the code and integrating it with the Genode environment. As of now, there exists support for circa 70 software packages, including the tool chain, various kernels, libraries, drivers, and a few applications. Of those packages, the code for 13 packages comes directly from their respective Git repositories. The remaining 57 packages are downloaded in the form of tar archives from public servers via HTTP or FTP. Whereas we are confident with the integrity of the code that comes from Git repositories, we are less so about the archives downloaded from HTTP or FTP servers.
Fortunately, most Open-Source projects provide signature files that allow the user to verify the origin of the archive. For example, archives of GNU software are signed with the private key of the GNU project. So the integrity of the archive can be tested with the corresponding public key. We used to ignore the signature files for many years but this has changed now. If there is a signature file available for a package, the package gets verified right after downloading. If only a hash-sum file is provided, we check it against a known-good hash sum.
The solution required three steps, the creation of tools for validating signatures and hashes, the integration of those tools into Genode's infrastructure for downloading the 3rd-party code, and the definition of verification rules for the individual packages.
First, new tools for downloading and validating hash sums and signatures were added in the form of the shell scripts download_hashver (verify hash sum) and download_sigver (verify signature) found at the tool/ directory. Under the hood, download_sigver uses GNU GPG, and download_hashver uses the tools md5sum, sha1sum, and sha256sum provided by coreutils.
Second, hooks for invoking the verification tools were added to the tool-chain build script as well as the ports and the libports repositories.
The third and the most elaborative step, was going through all the packages, looking for publicly available signature files, and adding corresponding package rules. As of now, this manual process has been carried out for 30 packages, thereby covering the half of the archives.
Thanks to Stephan Mueller for pushing us into the right direction, kicking off the work on this valuable feature, and for the manual labour of revisiting all the 3rd-party packages!