
Release notes for the Genode OS Framework 25.08
Genode 25.08 is ripe with deeply technical topics that have been cooking since the beginning of the year or even longer. In particular our new kernel scheduler as the flagship feature of this release has been in the works since February 2024. Section Kernel scheduling for fairness and low latency tells its background story and explains the approach taken. Another culmination of a long-term endeavor is the introduction of an alternative to XML syntax, specifically designed for the usage patterns of Genode and Sculpt OS. Section Consideration of a lean alternative to XML kicks off the practical evaluation of an idea that gradually evolved over more than two years. Also the holistic storage optimizations presented in Section Block-storage stack renovations are the result of careful long-term analysis, planning, and execution.
Besides these technical deep dives, the release delivers the update of all of Genode's Linux-based PC device drivers to kernel version 6.12 (Section Linux-based device drivers updated to kernel version 6.12). Thanks to these annually scheduled updates, users can rely on drivers on par with Linux while using any of the framework's supported microkernels. Speaking of kernels, the release continues our effort of widening the usage scenarios of the seL4 kernel with Genode by addressing several scalability bottlenecks and by updating the kernel to the latest release (Section seL4 kernel updated to version 13.0).
Kernel scheduling for fairness and low latency
In Genode 14.11, we added a specifically tailored quota-aware scheduling policy to our custom base-hw kernel. In more than ten years of use, we gathered precious insights into where it shines and where it falls behind. Trading CPU quota and preventing starvation in priority-based scheduling are two aspects where it certainly delivered. Nevertheless, with Sculpt OS as a major use case with a strong focus on dynamic workloads, we reviewed how well the base-hw scheduler still fulfills the following updated requirements:
Most importantly, scheduling must be fair, i.e. every thread shall get an equal or proportional share of CPU time. For instance, if three threads compete for the CPU, each thread is scheduled for one third of the time (equal shares) or, alternatively, CPU time is distributed proportional to the weight of the threads. The fundamental consequence of fairness is that there is no starvation.
Another essential aspect is that scheduling must support the combination of low-latency workload and high-throughput workload. While low-latency workload needs to be scheduled with limited waiting time and potentially smaller and more regular time slices, high-throughput workload should be scheduled with fewer preemptions (i.e., longer time slices).
Lastly, ease of configuration is not to be neglected. In a system such as Sculpt OS where components are added dynamically at runtime, assignment of scheduling parameters should be user-friendly and with as little side effects as possible. In this aspect, the base-hw scheduler fell a bit short because its prioritization of low-latency workload was only effective when a CPU quota was assigned. Moreover, when a thread exceeded its CPU quota, it did not receive any prioritization anymore until the end of the scheduler's super period. In consequence, small changes in workload could drastically impact the quality of service or require non-trivial adaptations to CPU-quota assignment. An ideal scheduling policy would instead gracefully degrade in cases of suboptimal configuration.
With these requirements and observations in mind, we reviewed existing scheduling policies and particularly entered the realm of virtual-time scheduling. In virtual-time scheduling, the (virtual) time of a scheduled thread advances inversely proportional to its assigned weight. In other words, threads that shall receive a larger share of CPU time advance slower in time. By picking the thread with the smallest virtual time upon each scheduling decision, one elegantly achieves proportionally fair scheduling.
Yet, we found one drawback with most virtual-time scheduling policies: Tuning threads for low latency requires increasing a thread's CPU share. This is a bit counter-intuitive as low-latency threads do not necessarily do a lot of computation. Fortunately, we came across a publication by Duda and Cheriton from 1999 with the title "Borrowed-virtual-time (BVT) scheduling: supporting latency-sensitive threads in a general-purpose scheduler". The main idea of BVT is that a thread is able to "borrow" time from its future CPU share, i.e., execute earlier than it would normally be eligible. The borrowed time is compensated by a longer waiting time for the next time slice. This mechanism is termed warping. BVT also elegantly answered the question of assigning time slices by letting each thread execute for up to a certain amount ahead of the other threads' virtual time. This ensures a minimum size of time slices and lets threads with a higher weight execute with longer time slices (i.e., fewer preemptions). Consequently, BVT comes with dedicated tunable parameters for CPU share (thread weight), latency (warp value) as well as number of preemptions.
After a bit of experimentation and simulation, we decided to implement a BVT-inspired scheduler for our base-hw kernel. More precisely, we implemented a hierarchical policy with two levels. The first level provides a fixed set of four groups that relate to the four scheduling priorities used by Sculpt OS (device driver, multimedia, default, and background). Weight and warp parameters are defined on this level to reserve a certain CPU share for each group and to preferably schedule, e.g., the device-driver group over all other groups in order to reflect the different latency requirements. The warp state of a group depends on the warp state of the currently selected thread in this group. On the second level, we decided to start with equal sharing (all threads have fixed weight 1). When a thread becomes ready (e.g., due to a signal or IRQ), it automatically enters the warped state, in which the warp value assigned to its group is subtracted from its virtual time. When a warping thread has been scheduled for a certain time (currently 50ms), it will be unwarped.
Currently, the resulting scheduling priorities for Sculpt OS are not yet mapped to the four scheduling groups. However, in preparation, we increased the number of priority levels of Sculpt's runtime init and lowered the driver, multimedia, default, and background components each by one priority level. This reserves the top-most priority for the runtime init instead of sharing the priority level with the device-driver components.
For a deep dive into the discussions and evaluations, please refer to the issue tracker.
- Issue #5117 (base-hw: scheduling fairness and latency optimization)
- Issue #5604 (scheduling benchmarks)
Consideration of a lean alternative to XML
From day one, Genode pragmatically uses XML as configuration syntax: A non-eccentric established format, capable of nested structures, simple to parse. It served us so well that we started using the format for state reporting in Genode 14.02 as well, making its role throughout the framework more prominent. This usage pattern eventually evolved to the publish-subscribe concept predominant in today's Genode systems like Sculpt OS. The advent of Sculpt OS, specifically, gave rise to the dynamic use of XML as interactive user interface, which is arguably far beyond the original use cases of XML we foresaw when we started.
Although Genode's use of XML received occasional criticism, we never really questioned it - until inspiration kissed us 2.5 years ago. A series of long evenings of exclusively using XML as interactive user interface of Sculpt OS made us contemplate about potential improvements that would make such interactions not just as practical as they are, but joyful! It followed a period of several months of casual experimentation, prototyping, casual iteration of ideas, and open-ended brain-storming sessions as a side activity. Out of this process evolved a format dubbed human-readable data (HRD) that received early feedback here and there.
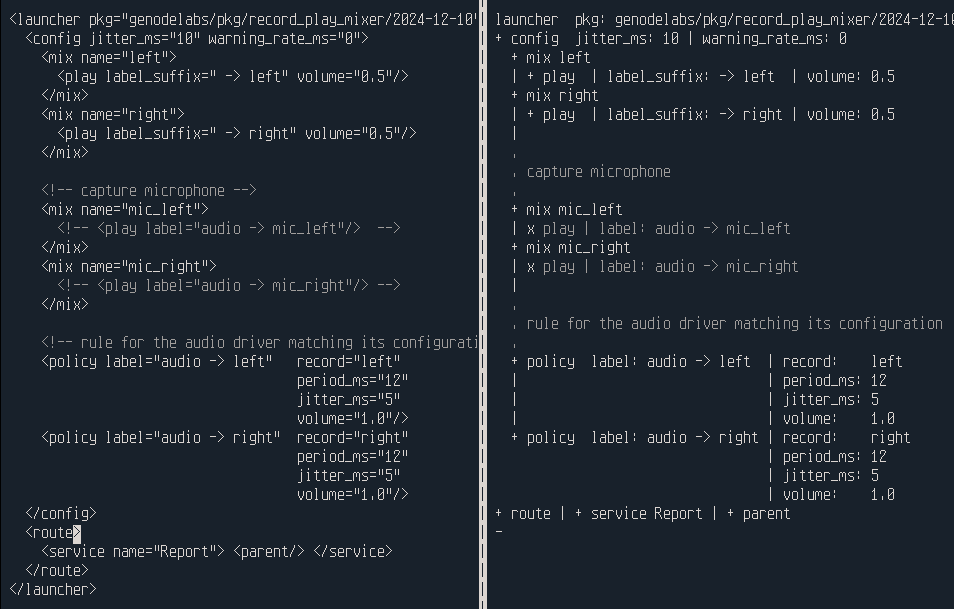
|
|
XML on the left, human readable data (HRD) on the right
|
The road map for this year promised the practical evaluation of this format as a potential avenue to depart from XML. With the current release, we have unlocked this evaluation by implementing the support for the HRD format throughout the framework using a step-wise approach.
First, we decoupled the code base from the hard-wired use of XML by introducing a new syntax-agnostic framework API at base/node.h (Section Syntax-agnostic configuration and reporting) and adjusting the components accordingly. During this work, we identified all potential points of friction, e.g., code that accessed the raw byte representation of the input, and reworked these parts.
Second, we added an HRD parser and generator at util/hrd.h, and enabled the syntax-agnostic API to accept both XML and HRD, transparently dispatching API calls to Xml_node or Hrd_node. Both formats are distinguished by looking at the first character of the input. After this step, all components have become able to transparently handle both formats. The syntax-agnostic Generator has been extended to support the output of both formats, controlled by a component-global switch. By default, it produces XML. When setting any component's configuration attribute generate_xml to "no", HRD is generated instead. This is entirely transparent to the component implementations.
Third, we test-ran several scenarios of increased sophistication by temporarily changing the global default to HRD. This step revealed residual interoperability corner cases that we addressed on a case-by-case basis. We took this line of work as far as running the entirety of Sculpt/Linux using the new syntax. So we are well on track of publishing an experimental HRD variant of the next official version of Sculpt OS scheduled for October.
Our intermediate findings are:
-
HRD is structurally equivalent to XML and covers all of Genode's use cases. This is quite exactly what we anticipated.
-
Thanks to the hybrid support for both formats, the migration from XML to HRD can in principle be pursued gradually. A migration path has not merely been sketched but it already exists.
-
There are minor incompatibilities between both formats that are better avoided than being addressed. In particular, HRD attribute values are always trimmed, ruling out the interpretation of leading/trailing spaces. As another detail, HRD attribute values cannot contain |, which is used as delimiting character. Both cases can be covered by using HRD's quoted content (lines starting with a colon).
-
In Genode's implementation, HRD requires about 40% less code than XML.
-
The hybrid support of both formats comes at added costs in terms of code complexity and executable binary size. Hence, down the road, we should settle on only one format.
As an invitation for exploring the use of HRD, we have added the initial version of a tool for processing the new format at /tool/hrd. The tool allows for converting XML to HRD and vice versa. It also offers commands for querying and modifying HRD files. Please refer to the tool's built-in --help for usage information.
Block-storage stack renovations
Prompted by questions about the I/O performance in virtual machines running on Genode, we investigated the status quo and started the journey of adapting the block-I/O stack in an attempt to optimize it. The work is accompanied by an in-depth article at Genodians.org.
The current release brings the first set of changes in form of the renovated VFS block plugin and the adjusted partition multiplexer.
VFS block plugin
The plugin itself has a long history as it was first conceived for noux, which itself has long been retired, and showed its age already. Besides the off-and-on maintenance changes, the plugin had not seen many alterations. With this release, we replaced its direct usage of the block connection with the block-job API that simplified the implementation as it handles some corner-cases internally.
As before, the plugin still creates one connection to a block-service provider but requests are now passed asynchronously. Thus, multiple concurrent requests can be in-flight if multiple VFS handles are used and request batching becomes possible.
The size of the I/O buffer, i.e., the shared-memory dataspace between the components, can be configured via the io_buffer attribute, the default value is now 4 MiB. The previously used block_buffer_count was removed and the plugin will issue a warning if it is specified. Requests that are larger than the configured I/O buffer are transparently handled by the job API.
Mediating partition multiplexer
Genode's part_block partition multiplexer makes each partition on a block device available as a separate block session. It uses one connection to a block provider, usually the block-device driver, to access the block storage. Concurrent requests from different block-client sessions are scheduled onto this connection where each client session accesses a virtual block device that covers the whole partition. Until now, the translation from virtual to physical block numbers was performed by the part-block component. This mode of operation was a trade-off. On the one hand, the design naturally enforced the isolation between clients accessing different partitions. On the other hand, between the multiplexer and its clients, data had to be copied by the CPU. The induced CPU load ultimately depended on the I/O patterns and number of clients. Those cycles, however, could also be used to perform other duties.
With this in mind, we decided to explore the opportunity of taking the part-block component off the I/O path. It would be still responsible for parsing the partition-table and make different block sessions available, but it should no longer play an active role in transferring data. Consequently, a good share of the I/O logic was moved from part_block into the block providers.
To realize this idea, we structured the effort into the following steps as this line of work involved changes to the block session as well as the block providers:
-
Constrain the view of the block session to a portion of a block device directly at the connection level. The view forms a virtual block device.
-
Add means to handle multiple clients at the block provider (some providers might allow for handling multiple clients separately while others require help in dealing with them).
-
Alter the part-block component such that it solely deals with parsing the partition table and mediates access to a given partition by merely parametrizing the block-session creation at the block provider.
For the first step, we added a constraining view type to the block session, which constrains the virtual view of the client to a block-device portion and supports the virtual-to-physical translation of block numbers. On the client side, the session can be augmented with the following new arguments to configure the virtual block device.
-
The offset argument specifies the first physical block number of the virtual block device.
-
The num_blocks argument specifies the number of blocks that are covered by the virtual block device.
-
The writeable argument specifies if the virtual block device allows write access. The writeable property of connection and policy of the block provider must match. So it ultimately decides if write-access is allowed.
The next step was the adaptation of the various block providers - AHCI, NVMe, SD-card, USB-block, and VFS-block. These providers used to expect only a single client for a given device, but now have to support multiple clients. The provider has to separate the access of different clients by evaluating the respective block-session argument. As all block providers by now make use of the request-stream facilities, dealing with the concrete block requests is already taken care of within its implementation.
However, as some block providers are limited by their available hardware resources, e.g. I/O queues, we had to employ a multiplexing scheme in those cases. It follows the implementation of the original part-block component where clients are scheduled in a round-robin fashion onto a single I/O connection. The outlier for now is the NVMe driver where commonly multiple I/O queues are available. As fallback, a single-queue multiplexing scheme is also available but needs to be activated explicitly by setting the force_sq attribute. All other block-device drivers use single-queue multiplexing under the hood. In all cases, the shared-memory dataspace between the block provider and its clients is used as DMA target whenever possible.
The last step involved switching the partition multiplexer into mediating mode. By using the virtual block-device notion (i.e., constrained view) and the ability of the block provider to manage multiple clients, the multiplexer can now solely mediate access to the block device and its partitions. It still parses the partition table but only forwards block-session requests augmented by the partition parameters (i.e., first block and number of blocks) to the block provider. For the actual data path, the client collaborates with the block provider directly.
As the part-block component only needs its own block connection to parse the partition-table, this connection is ephemeral in nature and is closed after the parsing has been completed. The io_buffer attribute has become obsolete as the client now specifies the I/O buffer size itself and thus may select a more fitting one for its own use case.
Combined, the changes of the VFS plugin as well as the drivers and the partition multiplexer streamline the I/O path. In case of the VFS plugin, the complexity of the implementation has decreased while opening up new possibilities. The partition multiplexer has become simpler at the expense of the block providers, whose complexity has increased. That being said, all in all the balance was kept while we could measurably lower the CPU load and at the same time increase the I/O throughput. The effects are especially noticeable on lower-end systems that are more likely to be CPU-bound. Also, scenarios where multiple virtual machines perform concurrent I/O operations targeting different partitions benefit particularly, because their respective data paths have become largely decoupled now.
Experimental libc POSIX AIO support
In an attempt to tap into the existing bandwidth and concurrency available by contemporary block devices, guided by the alterations to the block stack described in the previous section, we added rudimentary support for the POSIX AIO API at the libc level. For the moment, that support is mostly exercised by fio via its posixaio I/O engine and modeled after its requirements and serves exploration and testing purposes. As such, the implementation does not support asynchronous notification mechanisms, and thus relies on polling via aio_suspend.
AIO is implemented in a standalone fashion, which allows for changing the implementation almost independently of other parts of the libc. Apart from potentially triggering additional features in contrib code, it should not influence existing ports.
Under the hood, the libc will open multiple VFS handles for a given file-descriptor and use these to issue multiple requests concurrently. It is then up to the layers below to make proper use of them, i.e. order or batch them accordingly.
Base framework and OS-level infrastructure
Finalized hardening of XML-parsing utilities
The previous release introduced welcome API-safety improvements of the framework's pervasive XML-parsing utilities, facilitating the rigidly scoped use of references. The current release wraps up this line of work by ultimately replacing the unsafe Xml_node::sub_node interface by the safe with_sub_node. To make this transition possible, with_sub_node has now been equipped with the ability of returning values from a sub node's scope. The traditional sub_node method is no longer used throughout the code base and has been marked as deprecated.
Another widely used utility now scheduled for removal is Session_policy, which relies on the C++ exception mechanism. The code base has been migrated to the use of the exception-less with_matching_policy utility now.
Syntax-agnostic configuration and reporting
In anticipation of the potential change of Genode's universal use of XML to another syntax (Section Consideration of a lean alternative to XML) and to improve the conciseness of our code, we dropped the ceremonial "Xml_" prefix throughout our code base. The existing Xml_node and Xml_generator classes have now been supplemented by the syntax-agnostic types Node and Generator, which wrap the concrete parser implementation behind an API that is more rigid and independent of a concrete syntax. The util/xml_node.h and util/xml_generator.h utilities should no longer be used directly. Their functionality is now covered by the syntax-agnostic base/node.h API, which also offers Buffered_node and Generated_node as replacement of os/buffered_xml.h.
The from_xml class functions of geometry.h and affinity.h are now accompanied by counterparts named from_node. In the same spirit, Attached_rom_dataspace::xml has now received the sister method node. The with_matching_policy and util/list_model.h have been made compatible with both Node and Xml_node. The Reporter::generate and Expanding_reporter::generate methods provide a Generator & now. As a transition step, the original hard-wired use of XML is still available via the generate_xml methods. By convention, Generator instances are named g.
With these precautions in place, the update of existing code to the syntax-agnostic API comes mostly down to renaming Xml_node to Node, and Xml_generator &xml to Generator &g.
Quoted content
However, code that used to rely on accessing the raw bytes of the XML data (via with_raw_node and with_raw_content) must be reconsidered. In most cases, such code manually interpreted or merely copied CDATA. The access of node content for manual interpretation is now covered by the Node::for_each_quoted_line and Node::Quoted_content, which implicitly perform the decoding of preserved characters (e.g., converting > to >). The syntax-agnostic counterpart of Node::Quoted_content for the Generator comes in the form of append_quoted, append_node, and append_node_content methods, which take care of the syntax-specific encoding of special characters.
Note that node content is either interpreted as structured data (accessed as sub nodes) or as quoted data, never a mix of both. The clear-cut decision of one or the other depends on the use case. Hence, we revisited and clarified the existing places.
-
The dynamic ROM and ROM filter expect structured content because we did not observe any use case of delivering quoted content by these servers.
-
The <new-file> node of the fs_tool expects quoted content only.
-
The <inline> file system of the VFS supports both variants. In the presence of at least one line of quoted content (not wrapped in a node), the content is assumed to be quoted. Otherwise, the content is assumed to be structured data.
Avoiding leading/trailing space in attribute values
As a single notable point of friction between XML and HRD, we identified the interpretation of leading/trailing spaces in attribute values. In contrast to XML, HRD always trims attribute values, ignoring leading/trailing spaces. We encountered three cases where leading or trailing spaces were deliberately being used in attribute values. We opted to adapt those few corner cases instead of extending the HRD syntax with a way of quoting attribute values.
First, in the selection of server-side policies and session-routing conditions, exact matches (via label attributes) for sessions with no client-specified label have a trailing space because the " -> " character sequence is used as separator of the parts of the label. The reliance on the trailing space has now been relaxed by always trimming both strings before comparing.
Second, the menu-view's label widget used to take the text as attribute value. Sometimes, leading spaces are inserted for indentation/alignment purposes. We changed the label widget to take text as quoted content of a text sub node.
Third, environment variables for POSIX programs may feature significant trailing whitespace, e.g., for defining a gap after the shell prompt via PS1. To accommodate this case, we introduced an alternative way of specifying environment variables and arguments to POSIX programs. The new way supplies the values as node content (aka quoted content) instead of attributes. Backward compatibility to the original format is preserved.
Refined string utilities
During our parsing-related work in the current release cycle, we addressed long-standing limitations of the traditional text-parsing utilities provided by util/string.h that made their safe use more complicated than it should be.
Span
The existing non-copyable Const_byte_range_ptr is suitable for propagating references to parts of a text buffer along a chain of callers where the view on the buffer can be narrowed at each level. In other contexts such as the D language, such types are named Span, which appeals as shorter and thereby more ergonomic to use in parsing functions. Hence, we renamed Const_byte_range_ptr to Span while keeping Const_byte_range_ptr as an alias.
To aid the use of Span for parsing, we further equipped it with the following handy utilities: Span::cut and Span::split allow for the easy chopping of strings into sub strings at specific characters. Whereas cut splits a span into two parts separated by a given character, split cuts the span into all separated pieces, e.g., for iterating over lines separated by \n. The Span::trimmed method accesses the span without leading and trailing spaces. Finally, the Span::equals, starts_with, and ends_with methods ease string-matching code.
In order to conveniently combine these utilities with String<N> objects, we introduced the String::with_span method for safely accessing the string's content as Span.
Parse functions
The traditional ascii_to functions expect a null-terminated string. In most parsing situations, however, when operating on an immutable text buffer, parsing delimiters exists other than 0. To safely use ascii_to, one needs to copy-out text snippets of interest, or assure that there is indeed a null termination at the end of the entire input data.
To overcome this deficiency, we added new parse functions mirroring the existing ascii_to functions but operating on a Span const &. Following the established pattern of Genode's print approach, objects can now implement parse as a method, which is handy for parsing custom types and illustrated by util/color.h.
Minor cosmetics
The former Number_of_bytes utility has been shortened to Num_bytes and has become a plain struct with no constructor. Hence, plain integer values can no longer be directly assigned but need to be wrapped in { }.
Libraries and applications
VirtualBox 6
In preparation of improved support for modern Windows guest operating systems, we enabled optional EFI boot in VirtualBox 6. The boot variant can be selected in the .vbox configuration <Firmware type="..."/> node. Supported types are BIOS, EFI32, EFI64, and EFIDUAL. Moreover, we invested quite some time to render dynamic multi-monitor scenarios and handling of large screens more robust regarding resource consumption, synchronized access, and mouse-pointer positioning.
Device drivers
Linux-based device drivers updated to kernel version 6.12
During the 25.08 release cycle, we performed our yearly update of the DDE Linux kernel to version 6.12. As with release 24.08, we limited our efforts - as an initial step - to the emulation library itself, virt_linux, pc_linux, and the zynq_linux driver ports.
This implies that updated versions of the lxip TCP/IP stack, Wireguard, and USB devices are now available on all supported platforms. Additionally, Wifi and Ethernet adapters, Intel display, and USB-host controllers were updated for PC platforms as well as the SD-card driver for Zynq based SoCs.
The previous Linux-kernel sources (6.6) remain available as legacy_linux in repos/dde_linux/ports. So, in case your project still depends on the previous kernel version, this port can be used as a transitional stop-gap solution.
USB
Over the past months, we analyzed, debugged, and fixed a series of tricky issues regarding the dynamic handling of USB devices and sessions. All changes are under the hood of the drivers except the reintroduction of timeouts in the control-message API.
The USB-block driver now implements the SYNC block-session command by requesting SCSI SYNCHRONIZE CACHE at the device, which eliminates a small window of potential data corruption between applications (e.g., mkfs) requesting a SYNC before exit and the removal of the driver in Sculpt OS. Further, we merged a series of commits polishing the USB webcam driver that smoothen the use in Sculpt OS. The configuration attributes fps and format are now optional and by default libuvc is asked to select an appropriate setting for the detected device. Also, the enabled attribute was removed as the webcam is now configured on startup only and stays switched on until the app is terminated.
Platforms
Execution on bare hardware (base-hw)
The previous Genode release 25.05 was concerned with eliminating C++ exceptions from the base framework. Alternatively, new utilities safely ensure at compile-time that no error condition remains unconsidered, e.g., by using the Attempt compound type as result. However, exceptions have not completely vanished yet, which would enable us to compile the core component running on bare hardware without any C++ exception support (-fno-exceptions). The API to handle architecture-specific page tables still used exceptions to mark invalid insertion attempts, or memory shortage when trying to allocate new tables.
Therefore, we took the time to rework the page-table allocation and lookup API, and replaced all C++ exceptions by proper return types. Moreover, during this sanitizing operation, the different available page-table implementations for ARM (32/64 bit), RISCV, x86_64, and the different flavors for supporting hardware-assisted virtualization (AMD SVM, Intel VMX, ARM) got largely unified. Now, few generic template classes implement the whole traversal, insertion, and removal of page-table entries, and only the concrete entry layout is implemented architecture-wise, which reduced the overall code base significantly.
seL4 kernel updated to version 13.0
The seL4 microkernel project pursues the application of formal methods to the operating-systems domain. Even though we enabled the basic combination of Genode with the seL4 kernel as early as 2015, this line of work remained largely experimental and limited to the scope of rather static systems. Since the beginning of the year, however, we picked up this line of work, gradually lifted several limitations, and improved support for using seL4 with a larger variety of dynamic workloads. This ambition has been further fueled by the prospect of presenting Sculpt OS at the seL4 summit in September.
As continuation of the past two releases, we made the allocation of page tables per PD less static and thereby improved the performance of components with a large working set of virtual memory. In line with our larger goal of eliminating C++ exceptions from the base system, the seL4-specific code underwent a rework in this respect. As a practical feature, the reporting of CPU utilization has now been enabled on all CPUs. So our regular interactive performance-monitoring tools can be enjoyed on this kernel too. To enable the full arsenal of drivers of Sculpt OS, we added support for the re-allocation of I/O resources, like interrupts, and thereby unlocked Genode's pluggable drivers for this kernel. To accommodate memory-hungry workloads like the Falkon web browser on Sculpt OS, we increased the physical RAM limit from 4 to 8 GiB and widened the virtual address space to 16 GiB. With usage scenarios becoming more complex, the PIT-based timer called for being replaced by an HPET driver, which significantly reduces the CPU load induced by the timer driver. Last but not least, we updated the seL4 kernel to version 13.0.0, which is the latest release.