
Release notes for the Genode OS Framework 19.11
On our road map for this year, we stated "bridging worlds" as our guiding theme of 2019. The current release pays tribute to this ambition on several accounts.
First, acknowledging the role of POSIX in the real world outside the heavens of Genode, the release vastly improves our (optional) C runtime with respect to the emulation of POSIX signals, execve, and ioctl calls. With the line of work described in Section C runtime with improved POSIX compatibility, we hope to greatly reduce the friction when porting and hosting existing application software directly on Genode.
Second, we identified the process of porting or developing application software worth improving. Our existing tools were primarily geared to operating-system development, not application development. Application developers demand different work flows and tools, including the freedom to use a build system of their choice. Section New tooling for bridging existing build systems with Genode introduces our new take on this productivity issue.
Third, in cases where the porting of software to Genode is considered infeasible, virtualization comes to the rescue. With the current release, a new virtual machine monitor for the 64-bit ARM architecture enters the framework. It is presented in Section Virtualization of 64-bit ARM platforms.
As another goal for 2019, we envisioned a solution for block-level device encryption, which is a highly anticipated feature among Genode users. We are proud to present the preliminary result of our year-long development in Section Preliminary block-device encrypter.
Preliminary block-device encrypter
Over the past year, we worked on implementing a block-device encryption component that makes use of the SPARK programming language for its core logic. In contrast to common block-device encryption techniques where normally is little done besides the encryption of the on-disk blocks, the consistent block encrypter (CBE) aims for more. It combines multiple techniques to ensure integrity - the detection of unauthorized modifications of the block-device - and robustness against data loss. Robustness is achieved by keeping snapshots of old states of the device that remain unaffected by the further operation of the device. A copy-on-write mechanism (only the differential changes to the last snapshot are stored) is employed to maintain this snapshot history with low overhead. To be able to access all states of the device in the same manner, some kind of translation from virtual blocks to blocks on the device is needed. Hash-trees, where each node contains the hash of its sub-nodes, combine the aspect of translating blocks and ensuring their integrity in an elegant way. During the tree traversal, the computed hash of each node can be easily checked against the hash stored in the parent node.
The CBE does not perform any cryptography by itself but delegates cryptographic operations to another entity. It neither knows nor cares about the used algorithm. Of all the nodes in the virtual block device (VBD), only the leaf nodes, which contain the data, are encrypted. All other nodes, which only contain meta-data, are stored unencrypted.
Design
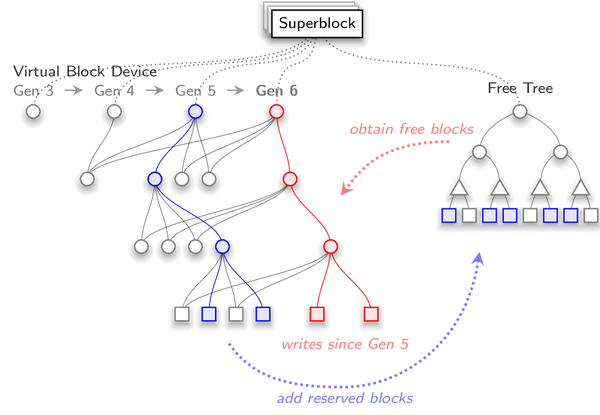
As depicted in Figure 1, all information describing the various parts of the CBE is stored in the superblock. The referenced VBD is a set of several hash trees, each representing a certain device state including the current working state. Only the tree of the current working state is used to write data to the block device. All other trees represent snapshots of older states and are immutable. Each stored device state has a generation number that provides the chronological order of the states.
As you can see, in the depicted situation, there exist four device states - the snapshot with generation 3 is the oldest, followed by two newer snapshots and generation 6 that marks the working state of the virtual device. The tree with generation 6 is the current working tree. Each tree contains all changes done to the VBD since the previous generation (for generation 6 the red nodes). All parts of a tree that didn't change since the previous generation are references into older trees (for generation 6 the gray nodes). Note that in the picture, nodes that are not relevant for generation 6 are omitted to keep it manageable. The actual data blocks of the virtual device are the leaf nodes of the trees, shown as squares.
|
Whenever a block request from the client would override data blocks in generation 6 that are still referenced from an older generation, new blocks for storing the changes are needed. Here is where the so-called Free Tree enters the picture. This tree contains and manages the spare blocks. Spare blocks are a certain amount of blocks that the CBE has in addition to the number of blocks needed for initializing the virtual device. So, after having initialized a virtual device, they remain unused and are only referenced by the Free Tree. Therefore, in case the VBD needs new blocks, it consults the Free Tree (red arrow).
In the depicted situation, writing the first data block (red square) would require allocating 4 new blocks as all nodes in the branch leading to the corresponding leaf node - including the leaf node itself - have to be written. In contrast, writing the second data block would require allocating only one new block as the inner nodes (red circles) now already exist. Subsequent write requests affecting only the new blocks will not trigger further block allocations because they still belong to the current generation and will be changed in-place. To make them immutable we have to create a new snapshot.
The blocks in generation 5 that were replaced by the change to generation 6 (blue nodes) are not needed for the working state of the virtual device anymore. They are therefore, in exchange for the allocated blocks, added to the Free Tree. But don't be fooled by the name, they are not free for allocation yet, but marked as "reserved" only. This means, they are potentially still part of a snapshot (as is the case in our example) but the Free Tree shall keep checking, because once all snapshots that referenced the blue blocks have disappeared, they become free blocks and can be allocated again.
To create a new snapshot, we first have to make all changes done to the VBDs working state as well as the Free Tree persistent by writing all corresponding blocks to the block-device. After that, the new superblock state is written to the block-device. To safeguard this operation, the CBE always maintains several older states of the superblock on the block device. In case writing the new state of the superblock fails, the CBE could fall back to the last state that, in our example, would contain only generations 3, 4, and 5. Finally, the current generation of the superblock in RAM is incremented by one (in the example to generation 7). Thereby, generation 6 becomes immutable.
A question that remains is when to create snapshots. Triggering a snapshot according to some heuristics inside the CBE might result in unnecessary overhead. For instance, the inner nodes of the tree change frequently during a sequential operation. We might not want them to be re-allocated all the time. Therefore, the creation of a snapshot must be triggered explicitly from the outside world. This way, we can accommodate different strategies, for instance, client-triggered, time-based, or based on the amount of data written.
When creating a snapshot, it can be specified whether it shall be disposable or persistent. A disposable snapshot will be removed automatically by the CBE in two situations, either
-
When there are not enough usable nodes in the Free Tree left to satisfy a write request, or
-
When creating a new snapshot and all slots in the superblock that might reference snapshots are already occupied.
A persistent snapshot, or quarantine snapshot, on the other hand will never be removed automatically. Its removal must be requested explicitly.
During initialization, the CBE selects the most recent superblock and reads the last generation value from it. The current generation (or working state generation) is then set to the value incremented by one. Since all old blocks, that are still referenced by a snapshot, are never changed again, overall consistency is guaranteed for every generation whose superblock was stored safely on disk.
Implementation
Although we aimed for a SPARK implementation of the CBE, we saw several obstacles with developing it in SPARK right from the beginning. These obstacles mainly came from the fact that none of us was experienced in designing complex software in SPARK. So we started by conducting a rapid design-space exploration using our mother tongue (C++) while using only language features that can be mapped 1:1 to SPARK concepts. Additionally, we applied a clear design methodology that allowed us to keep implementation-to-test cycles small and perform a seamless and gradual translation into SPARK:
-
Control flow
The core logic of the CBE is a big state machine that doesn't block. On each external event, the state machine gets poked to update itself accordingly. C++ can call SPARK but SPARK never calls C++. The SPARK code therefore evolves as self-contained library.
-
Modularity
The complex state machine of the CBE as a whole is split-up into smaller manageable sub-state-machines, working independently from each other. These modules don't call each other directly. Instead, an additional superior module handles the interplay. This is done by constantly iterating over all modules with the following procedure until no further progress can be made:
-
Try to enter requests of other modules into the current one
-
Poke the state machine of the current module
-
The current module may have generated requests - Try to enter them into the targeted modules
-
The current module may have finished requests - Acknowledge them at the modules they came from
Each module is represented through a class (C++) respectively a package with a private state record (SPARK).
-
-
No global state
There are no static (C++) or package (SPARK) variables. All state is kept in members of objects (C++) respectively records (SPARK). All packages are pure and sub-programs have no side-effects. Therefore, memory management and communication with other components is left to OS glue-code outside the core logic.
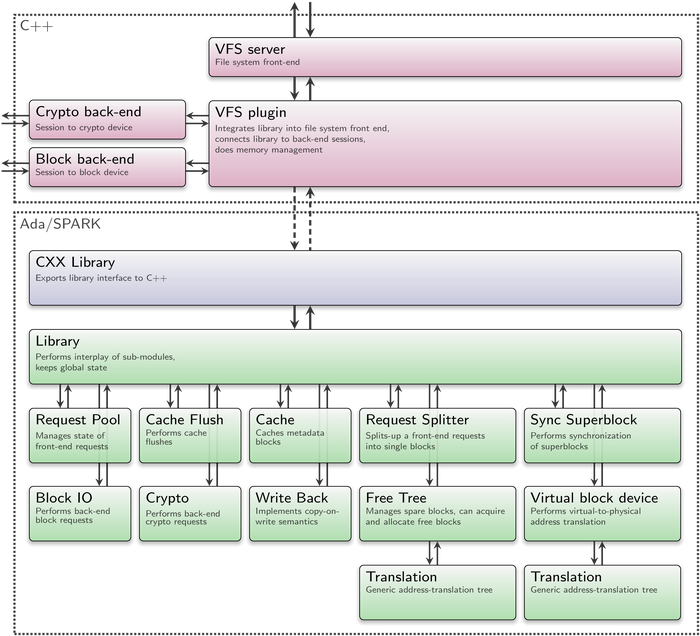
This approach worked out well. Module by module, we were able to translate the C++ prototype to SPARK without long untested phases, rendering all regression bugs manageable. In Genode, the CBE library is currently integrated through the CBE-VFS plugin. Figure 2 depicts its current structure and the integration via VFS plugin.
|
The green and blue boxes each represent an Ada/SPARK package. The translation to SPARK started at the bottom of the picture moving up to the more abstract levels until it reached the Library module. This is the module that handles the interplay of all other modules. Its interface is the front end of the CBE library. So, all green packages are now completely written in SPARK and together form the CBE library. Positioned above, the CXX library in blue is brought in by a separate library and exports the CBE interface to C++. This way, the CBE can also be used in other environments including pure SPARK programs. The CXX Library package is not written in SPARK but Ada and performs all the conversions and checks required to meet the preconditions set by the SPARK packages below.
At the C++ side, we have the VFS plugin. Even at this level, the already mentioned procedure applies: The plugin continuously tries to enter requests coming from the VFS client (above) into the CBE (below), pokes the CBE state machine, and puts thereby generated block/crypto requests of the CBE into the corresponding back-ends (left). This process is repeated until there is no further progress without waiting for an external event.
Current state
In its current state, the CBE library is still pretty much in flux and is not meant for productive use.
As the Free Tree does not employ copy-on-write semantics for its meta-data, a crash, software- or hardware-wise, will corrupt the tree structure and renders the CBE unusable on the next start.
This issue is subject to ongoing work. That being said, there are components that, besides being used for testing, show how the interface of the CBE library lends itself to be integrated in components in different ways. At the moment, there are two components making use of the CBE library as block-device provider.
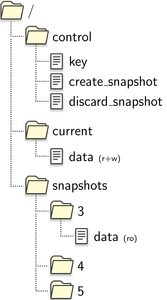
The first one is the aforementioned CBE-VFS plugin. Besides r/w access to the working tree and r/o access to all persistent snapshots, it also provides a management interface where persistent snapshots can be created or discarded. Its current layout is illustrated by Figure 3. The VFS plugin generates three top directories in its root directory. The first one is the control directory. It contains several pseudo files for managing the CBE:
|
- key
-
set a key by writing a string into the file.
- create_snapshot
-
writing true to this file will attempt to create a new snapshot. (Eventually the snapshot will appear in the snapshots directory if it could be created successfully.)
- discard_snapshot
-
writing a snapshot ID into this file will discard the snapshot
The second is the current directory. It gives access to the current working tree of the CBE and contains the following file:
- data
-
this file represents the virtual block device and gives read and write access to the data stored by the CBE.
The third and last is the snapshots directory. For each persistent snapshot, there is a sub-directory named after the ID of the snapshot. This directory, like the current directory, contains a data file. This file, however, gives only read access to the data belonging to the snapshot.
The CBE-VFS plugin itself uses the VFS to access the underlying block device. It utilizes the file specified in its configuration. Here is a <vfs> snippet that shows a configured CBE-VFS plugin where the block device is provided by the block VFS plugin.
<vfs> <dir name="dev"> <block name="block"/> <cbe name="cbe" block="/dev/block"/> </dir> </vfs>
An exemplary ready-to-use run script can be found in the CBE repository at run/cbe_vfs_snaps.run. This run script uses a bash script to automatically perform a few operations on the CBE using the VFS plugin. Afterwards it will drop the user into a shell where further operations can be performed manually, e.g.:
dd if=/dev/zero of=/dev/cbe/current/data bs=4K
The second component is the CBE server. In contrast to the CBE-VFS plugin, it is just a simple block-session proxy component that uses a block connection as back end to access a block-device. It provides a front-end block session to its client, creates disposable snapshots every few seconds, and uses the External_Crypto library to encrypt the data blocks using AES-CBC-ESSIV. The used key is a plain passphrase. The following snippet illustrates its configuration:
<start name="cbe"> <resource name="RAM" quantum="4M"/> <provides><service name="Block"/></provides> <config sync_interval="5" passphrase="All your base are belong to us"/> </start>
The run/cbe.run run script in the CBE repository showcases the use of the CBE server.
Both run scripts will create the initial CBE state in a RAM-backed block device that is then accessed by the CBE server or the CBE-VFS plugin.
The run-script and the code itself can be found on the cbe/cbe_19.11 branch on GitHub. If you intend to try it out, you have to checkout the corresponding genode/cbe_19.11 branch in the Genode repository as well.
Future plans
Besides addressing the current shortcomings and getting the CBE library production-ready so that it can be used in Sculpt, there are still a few features that are currently unimplemented. For one we would like to add support for making it possible to resize the VBD as well as the Free Tree. For now the geometry is fixed at initialization time and cannot be changed afterwards. Furthermore, we would like to enable re-keying, i.e., changing the used cryptographic key and re-encrypting the tree set of the VBD afterwards. In addition to implementing those features, the overall tooling for the CBE needs to be improved. E.g., there is currently no proper initialization component. For now, we rely on a component that was built merely as a test vehicle to generate the initial trees.
Virtualization of 64-bit ARM platforms
Genode has a long history regarding support of all kinds of virtualization-related techniques including para-virtualization, TrustZone, hardware-assisted virtualization on ARM, x86, up to the full virtualization stack of VirtualBox.
We regard those techniques as welcome stop-gap solutions for using non-trivial existing software stacks on top of Genode's clean-slate OS architecture. The recent introduction of a kernel-agnostic interface to control virtual machines (VM) ushered a new level for the construction respectively porting of virtual-machine monitors (VMM). By introducing a new ARMv8-compliant VMM developed from scratch, we continue this line of work.
The new VMM builds upon our existing proof-of-concept (PoC) implementation for ARMv7 as introduced in release 15.02. In contrast to the former PoC implementation, however, it aims to be complete to a greater extent. Currently, it comprises device models for the following virtual hardware:
-
RAM
-
System Bus
-
CPU
-
Generic Interrupt Controller v2 and v3
-
Generic Timer
-
PL011 UART (limited)
-
Pass-through devices
The VMM is able to load diverse 64-bit Linux kernels including Device-Tree-Binary (DTB) and Initramfs. Currently, the implementation uses a fixed memory layout for the guest-physical memory view, which needs to be reflected by the DTB used by the guest OS. An example device-tree source file can be found at repos/os/src/server/vmm/spec/arm_v8/virt.dts. The actual VMM is located in the same directory.
Although support for multi-core VMs is already considered internally, it is not yet finished. Further outstanding features that are already in development are Virtio device model support for networking and console. As the first - and by now only - back end, we tied the VMM to the ARMv8 broadened Kernel-agnostic VM-session interface as implemented by Genode's custom base-hw kernel. As a side effect of this work, we consolidated the generic VM session interface slightly. The RPC call to create a new virtual-CPU now returns an identifier for identification.
The VMM has a strict dependency on ARM's hardware virtualization support (EL2), which comprises extensions for the ARMv8-A CPU, ARM's generic timer, and ARM's GIC. This rules out the Raspberry Pi 3 board as a base platform because it does not include a GIC but a custom interrupt-controller without hardware-assisted virtualization of interrupts. To give the new VMM a try, we recommend using the run script repos/os/run/vmm_arm.run as a starting point for executing the VMM on top of the i.MX8 Evaluation Kit board.
New tooling for bridging existing build systems with Genode
Genode's development tools are powerful and intimidating at the same time. Being designed from the perspective of a whole-systems developer, they put emphasis on the modularity of the code base (separating concerns like different kernels or system abstraction levels), transitive dependency tracking between libraries, scripting of a wide variety of system-integration tasks, and the continuous integration of complete Genode-based operating-system scenarios. Those tools are a two-edged sword though.
On the one hand, the tools are key for the productivity of seasoned Genode developers once the potential of the tools is fully understood and leveraged. For example, during the development of Sculpt OS, we are able to change an arbitrary line of code in any system component and can test-drive the resulting Sculpt system on real hardware within a couple of seconds. As another example, the almost seamless switching from one OS kernel to another has become a daily routine that we just take for granted without even thinking about it.
On the other hand, the sophistication of the tools stands in the way of application developers who are focused on a particular component instead of the holistic Genode system. In this case, the powerful system-integration features remain unused but the complexity of the tools and the build system prevails. Speaking of build systems, this topic is ripe of emotions anyway. Developers use to hate build systems. Forcing Genode's build system down the throats of application developers is probably not the best idea to make Genode popular.
This line of thoughts prompted us to re-approach the tooling for Genode from the perspective of an application developer. The intermediate result is a new tool called Goa:
- Goa project at GitHub
Unlike Genode's regular tools, Goa's work flow is project-centered. A project is a directory that may contain source code, data, instructions how to download source codes from a 3rd party, descriptions of system scenarios, or combinations thereof. Goa is independent from Genode's regular build system. It combines Genode's package management (depot) with commodity build systems such a CMake. In addition to building and test-driving application software directly on a Linux-based development system, Goa is able to aid the process of exporting and packaging the software in the format expected by Genode systems like Sculpt OS.
At the current stage, Goa should be considered as work in progress. It's a new approach and its success is anything but proven. That said, if you are interested in developing or porting application software for Genode, your feedback would be especially valuable. As a starting point, you may find the following introductory article helpful:
- Goa - streamlining the development of Genode applications
Base framework and OS-level infrastructure
File-system session
The file-system session interface received a much anticipated update.
Writing modification times
The new operation WRITE_TIMESTAMP allows a client to update the modification time of a file-system node. The time is defined by the client to keep file-system servers free from time-related concerns. The VFS server implements the operation by forwarding it to the VFS plugin interface. At present, this new interface is implemented by the rump VFS plugin to store modification times on EXT2 file systems.
Enhanced file-status info
The status of a file-system node as returned by the File_system::Status operation has been revisited. First, we replaced the fairly opaque "mode" bits - which were an ad-hoc attempt to stay compatible with Unix - with the explicit notion of readable, writeable, and executable attributes. We completely dropped the notion of users and groups. Second, we added the distinction between continuous and transactional files to allow for the robust implementation of continuous write operations across component boundaries. A continuous file can be written-to via a sequence of arbitrarily sized chunks of data. For such files, a client can split a large write operation into any number of smaller operations in accordance to the size of the used I/O buffers. In contrast, a write to a transactional file is regarded as a distinct operation. The canonical example of a transactional file is a socket-control pseudo file.
Virtual file-system infrastructure
First fragments of a front-end API
The VFS is mostly used indirectly via the C runtime. However, it is also useful for a few components that use the Genode API directly without any libc. To accommodate such users of the VFS, we introduced the front-end API at os/vfs.h that covers a variety of current use cases. Currently, those use cases revolve around the watching, reading, and parsing of files and file-system structures - as performed by Sculpt's deployment mechanism. Writing to files is not covered.
Improved file-watching support
All pseudo files that use the VFS-internal Readonly_value_file_system utility have become able to deliver watch notifications. This change enables VFS clients to respond to VFS-plugin events (think of terminal resize) dynamically.
Speaking of the terminal VFS plugin, the current release enhances the plugin in several respects. First, it now delivers status information such as the terminal size via pseudo files. Second, we equipped the VFS terminal file system with the ability to detect user interrupts in the incoming data stream, and propagate this information via the new pseudo file .terminal/interrupts. Each time, the user presses control-c in the terminal, the value stored in this pseudo file is increased. Thereby, a VFS client can watch this file to get notified about the occurrences of user interrupts.
VFS plugin for emulating POSIX pipes
We added a new VFS plugin for emulating POSIX pipes. The new plugin creates pipes between pairs of VFS handles. It replaces the deprecated libc_pipe plugin. In contrast to the libc_pipe plugin, which was limited to pipes within one component, the new VFS plugin can also be used to establish pipes between different components by mounting the plugin at a shared VFS server.
C runtime with improved POSIX compatibility
Within Genode, we used to think of POSIX as a legacy that is best avoided. In fact, the foundational components of the framework do not depend on a C runtime at all. However, higher up the software stack - at the latest when 3rd-party libraries enter the picture - a working C runtime is unavoidable. In this statement, the term "working" is rather muddy though. Since we have never fully embraced POSIX, we were content with cutting corners here and there. For example, given Genode's architecture, supporting fork and execve seemed totally out of question because those mechanisms would go against the grain of Genode.
However, our growing aspiration to bridge the gap between existing popular applications and Genode made us re-evaluate our stance towards POSIX. All technical criticism aside, POSIX is immensely useful because it is a universally accepted stable interface. To dissolve friction between Genode and popular application software, we have to satisfy the application's expectations. This ignited a series of developments, in particular the added support for fork and execve - of all things - in Genode 19.08, which was nothing short of surprising, even to us. The current release continues this line of development and brings the following improvements.
Execve
The libc's execve implementation got enhanced to evaluate the path of the executable binary according to the information found on the VFS, in particular by traversing directories and following symbolic links. This enables the libc to execute files stored at sub directories of the file system.
Furthermore, execve received handling for executing shell scripts by parsing the shebang marker at the beginning of the executable file. This way, the execve mechanism of the libc reaches parity with the feature set of the Noux runtime that we traditionally used to host Unix software on top of Genode.
Modification-time handling
By default, the libc uses the just added facility for updating the timestamp of file-system nodes when closing a written-to file, which clears the path towards using tools like make that rely on file-modifications times.
The libc's mechanism can be explicitly disabled by specifying
<libc update_mtime="no"...>
This is useful for applications that have no legitimate access to a time source.
Emulation of ioctl operations via pseudo files
With the current release, we introduce a new scheme of handling ioctl operations, which maps ioctl calls to pseudo-file accesses, similar to how the libc already maps socket calls to socket-fs operations.
A device file can be accompanied with a (hidden) directory that is named after the device file and hosts pseudo files for triggering the various device operations. For example, for accessing a terminal, the directory structure looks like this:
/dev/terminal /dev/.terminal/info /dev/.terminal/rows /dev/.terminal/columns /dev/.terminal/interrupts
The info file contains device information in XML format. The type of the XML node corresponds to the device type. Whenever the libc receives a TIOCGWINSZ ioctl for /dev/terminal, it reads the content of /dev/.terminal/info to obtain the terminal-size information. In this case, the info file looks as follows:
<terminal rows="25" columns="80/>
Following this scheme, VFS plugins can support ioctl operations by providing an ioctl directory in addition to the actual device file.
Emulation of POSIX signals
Even though there is no notion of POSIX signals at the Genode level, we can reasonably emulate certain POSIX signals at the libc level. The current release introduces the first bunch of such emulated signals:
- SIGWINCH
-
If stdout is connected to a terminal, the libc watches the terminal's ioctl pseudo file .terminal/info. Whenever the terminal size changes, the POSIX signal SIGWINCH is delivered to the application. With this improvement, Vim becomes able to dynamically adjust itself to changed window dimensions when started as a native Genode component (w/o the Noux runtime environment).
- SIGINT
-
If stdin is connected to a terminal, the libc watches the terminal's pseudo file .terminal/interrupts. Since, the terminal VFS plugin modifies the file for each occurred user interrupt (control-c), the libc is able to reflect such an event as SIGINT signal to the application.
- Process-local signal delivery
-
The libc's implementation of kill got enhanced with the ability to submit signals to the local process.
Support for arbitrarily large write operations
The number of bytes written by a single write call used to be constrained by the file's underlying I/O buffer size. Even though our libc correctly returned this information to the application, we found that real-world applications rarely check the return value of write because partial writes do usually not occur on popular POSIX systems. Thanks to the added distinction between continuous and transactional files as described in Section File-system session, we became able to improve the libc's write operation to iterate on partial writes to continuous files until the original write count is reached. The split of large write operations into small partial writes as dictated by the VFS infrastructure becomes invisible to the libc-using application.
Input-event handling
In Genode 19.08, we undertook a comprehensive rework of our keyboard-event handling in the light of localization and also promised to tie up remaining loose ends soon.
First, we again dived into our character generators for a thorough check of our stack of keyboards and fixed remaining inconsistencies in French and German layouts. En passant, we also increased the default RAM quotas for the input filter to 1280K in our recipes to cope with the increased layout-configuration sizes in corner cases.
Next - and more importantly - we subdued the monsters lurking in our Qt5 keyboard back end and enabled transparent support for system-wide keyboard layout configuration for Qt5 components. One important change during this work was to move the handling of control key sequences into the clients. For example, the graphical terminal and Qt5 interpret key events in combination with the CTRL modifier based on characters and, thus, support CTRL-A with AZERTY and QWERTY layouts correctly. As a result we removed all CTRL modifier (mod2) configurations from our character-generator configurations.
Finally we'd like to point out one important change of our rework that repeatedly led to surprises: For keys without character mappings the reworked character-generator mechanism emits invalid codepoints in contrast to codepoints with value 0. For that reason, components interpreting character events should check Codepoint::valid() to prevent the processing of invalid characters (and not the frequent pattern of codepoint.value != 0).
NIC router
The NIC router has received the ability to report the link state of its NIC interfaces (downlinks and uplinks). To control this mechanism, there are two new boolean attributes link_state and link_state_triggers in the <report> tag of the NIC router configuration. If the former is set to "true", the report will contain the current link state for each interface:
<domain name="domain1">
<interface label="uplink1" link_state="false"/>
<interface label="downlink1" link_state="true"/>
</domain>
<domain name="domain2">
<interface label="downlink2" link_state="true"/>
</domain>
The second attribute decides whether to trigger a report update each time the link state of an interface changes. By default, both attributes are set to "false".
Device drivers
Platform driver on x86
During our enablement of Genode on a recent notebook, we spotted some PC platform shortcomings, we address with this release. Most prominently we added support for 64-bit PCI base address registers to the x86 platform driver. This allows the use of PCI devices that are assigned to physical I/O-memory regions beyond 4 GiB by the boot firmware.
Wireless driver
We added the firmware images for the 5000 and 9000 series of Intel wireless devices to the firmware white-list in the wifi_drv component. Such devices as 5100AGN, 5300AGN and 5350AGN as well as 9461, 9462 and 9560 should now be usable on Genode.
Libraries and applications
VirtualBox improvements
The GUI handling of our VirtualBox port got improved to react on window-size changes more instantly. The effect is that an interactive adjustment of the window size, e.g., on Sculpt, becomes quickly visible to the user. Still, the VM may take some time to adjust to the resolution change, which ultimately depends on the behavior of the driver of the VirtualBox guest additions.
Updated 3rd-party software
With the addition of the 64-bit ARM architecture (AARCH64) with the 19.05 release, it became necessary to update the libraries the Genode tool chain (gcc) depends on in order to support AARCH64 properly. This concerns the GNU multi precision arithmetic library (gmp), which has been updated from version 4.3.2 to 6.1.2, as well as the libraries that depend on it: Multi precision floating point (mpfr) and multi precision complex arithmetic (mpc). All those old versions did not offer support for the AARCH64 architecture, which is a requirement to make Genode self hosting. Targets for building binutils and GCC within Genode for AARCH64 are in place, GNU make is in place, and even code coverage (gcov) has been added. This work puts AARCH64 in line with other supported CPU architectures and emphasizes our interest in the ARM 64-bit architecture.
Platforms
Execution on bare hardware (base-hw)
With the previous release, Genode's base-hw kernel got extended to support the ARMv8-A architecture in principle. The first hardware supported was the Raspberry Pi 3 as well as the i.MX8 evaluation kit (EVK). But only a single CPU-core was usable at that time. Now, we lifted this limitation. On both boards, all four CPU-cores are available henceforth.
Removed components
The current release removes the following components:
- gems/src/app/launcher
-
The graphical launcher remained unused for a few years now. It is not suitable for systems as flexible as Sculpt OS.
- os/src/app/cli_monitor
-
CLI monitor was a runtime environment with a custom command-line interface to start and stop subsystems. It was part of the user interface of our first take on a Genode-based desktop OS called Turmvilla.
Nowadays, we use standard command-line tools like Vim to edit init configurations dynamically, which is more flexible and - at the same time - alleviates the need for a custom CLI. The CLI-monitor component was too limited for use cases like Sculpt anyway.
Along with the CLI monitor, we removed the ancient (and untested for long time) terminal_mux.run script, which was the only remaining user of the CLI monitor.
- fatfs_fs, rump_fs, and libc_fatfs plugin
-
The stand-alone file-system servers fatfs_fs and rump_fs as well as the fatfs libc plugin have been superseded by the fatfs and rump VFS plugins. The stand-alone servers can be replaced by using the VFS server plus the corresponding VFS plugin as a drop-in replacement.