
Release notes for the Genode OS Framework 23.02
With Genode's February release, almost everything goes according to plan. As envisioned on our road map, it features the first ready-to-install system image of Sculpt OS for the PinePhone, which is not merely a re-targeted version of the PC version but comes with a novel user interface, a new mechanism for rapidly switching between different application scenarios, and system-update functionality. Section First system image of mobile Sculpt OS (PinePhone) gives an overview and further links about running Genode on your PinePhone.
While enabling substantial application workloads on devices as constrained as the PinePhone, we engaged in holistic performance optimizations, ranging from kernel scheduling (Section Base-HW microkernel), over the framework's VFS infrastructure (Section VFS optimization and simplification), to the interfacing of GPU drivers (Section GPU performance optimizations).
For stationary ARM-based platforms like the MNT-Reform laptop, interactive graphical virtual machines have become available now, which brings us close to mirror the experience of the PC version of Sculpt OS on such devices (Section Interactive graphical VMs on ARM). This development is accompanied by several device-driver improvements for NXP's i.MX family.
For embedded devices based on Xilinx Zynq, the release introduces custom FPGA fabric for implementing DMA protection that is normally not covered by Zynq SoCs. This line of work - as outlined in Section Custom IP block for DMA protection on AMD/Xilinx Zynq - exemplifies how well Genode and reconfigurable hardware can go hand in hand.
Also, PC platforms got their share of attention, benefiting from the new distinction between Intel's P&E cores, or the principle support of suspend/resume on both NOVA and Genode's custom base-hw microkernel.
When it comes to running applications on top of Genode, the release brings good news as well. Our custom Goa tool for streamlining application-development work flows received the ability to largely automate the porting and packaging of 3rd-party libraries using CMake (Section Build system and tools).
First system image of mobile Sculpt OS (PinePhone)
Just in time for our public presentation of Genode on the PinePhone at FOSDEM in the beginning of February, we published a first ready-to-use system image:
- First system image of mobile Sculpt OS
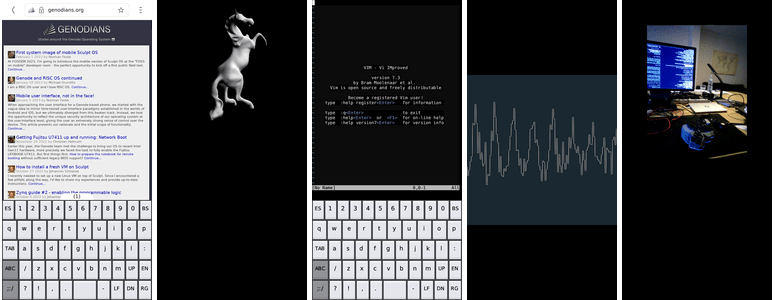
It features a custom user interface, voice calls and mobile-data connectivity, on-target software installation and system update, device controls (battery, brightness, volume, mic, reset, shutdown), and a variety of installable software. Among the installable applications, there is the Chromium-based Morph web browser, an OpenGL demo using the GPU, tests for the camera and microphone, as well as a light-weight Unix-like system shell.
The underpinnings of the Genode system image for the PinePhone are nearly identical to Sculpt OS on the PC. However, besides the new user interface specifically designed for the touch screen of the phone, two noteworthy differences set it apart from the regular version of Sculpt OS.
|
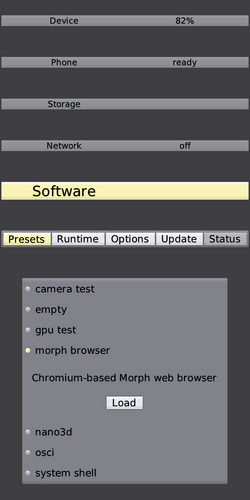
First, the phone variant allows the user to rapidly switch between different runtime configurations, called presets. This way, the limited resources of the phone can be accounted and fully leveraged for each preset individually, while making the system extremely versatile. The loading of a preset can be imagined as the boot into a separate operating system, but it takes only a fraction of a second. The structure of the running system is made fully transparent to the user by the component graph known from Sculpt OS.
|
|
The variety of presets includes the Morph browser, GLMark2, a system shell, a simple oscilloscope, and camera test.
|
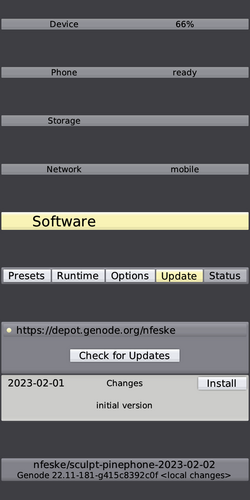
Second, the system is equipped with an on-target system update mechanism that allows the user to install new versions of the system image when they become available. System updates are secured by cryptographic signatures. The mechanism does not only allow for updating the system but also for the rollback to any previously downloaded version. This way, the user can try out a new version while being able to fall back to the previous one in the case of a regression. This reinforces the end user's ultimate control.
|
Interactive graphical VMs on ARM
The virtual-machine monitor (VMM) using hardware-assisted virtualization on ARM started as a case study eight years ago for Samsung's Exynos 5250 SoC. Originally, it supported virtualization of CPU, timer, interrupt-controller, and a UART-device only. Since then, it received several extensions like support for 64-bit ARMv8 systems, VirtIO devices for network, console, and block access. With release 22.11, the VMM's I/O device access, RAM consumption, and CPU count have come configurable.
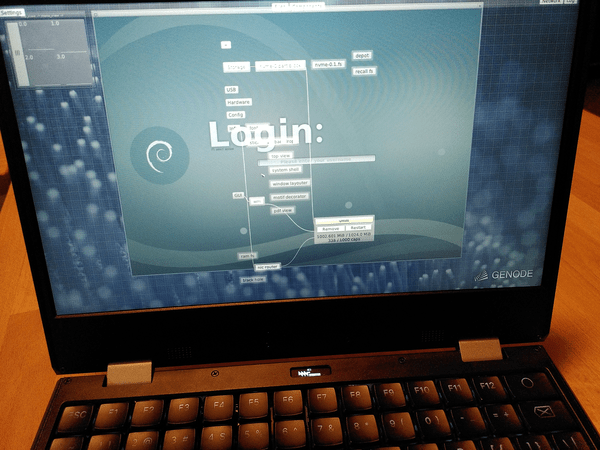
With the current release, we further enhance the VMM for ARM devices to provide all the means necessary to become a useful virtualization solution for interactive scenarios.
|
|
Sculpt OS running Debian in a virtual machine on the MNT Reform laptop
|
Two additional VirtIO device models are available now: A GPU model and one for input. Both models are mapped to Genode's GUI service under the hood. One can extend the configuration of the VMM accordingly:
<config ...> <virtio_device name="fb0" type="gpu"/> <virtio_device name="event0" type="input"/> ... </config>
For now, only one GPU and one input device can be declared. Both devices get mapped to the very same GUI service, according to the service routing of the VMM.
Caution: the GPU and input model are still in an experimental state, and there are known corner cases, e.g., when the graphical window size of the VMM gets changed dynamically.
Formerly, the VMM always expected an initial RAM file system to be provided as ROM dataspace, which got loaded together with the Linux kernel into the VM's memory. Now, it is possible to omit the "initrd_rom" configuration option. If omitted, no initrd is provided to the Linux guest.
Custom IP block for DMA protection on AMD/Xilinx Zynq
As a continuation of the hardware-software co-design efforts presented in the previous release, we turned towards enabling bulk-data transfer between the Zynq's CPU and its FPGA. In a first step, we built a custom hardware design that implements a DMA loopback device based on Xilinx' AXI DMA IP. Since we were particularly interested in testing out the Zynq's accelerator coherency port (ACP), we implemented two loopback devices: one attached to the ACP and one to the high-performance (HP) AXI port of the Zynq. In order to test the design in Genode, we added a port of Xilinx' embeddedsw repository that hosts standalone driver code for the Xilinx IP cores. Based on this port, we implemented the xilinx_axidma library as a Genode wrapper in order to simplify development of custom drivers using Xilinx' AXI DMA IP. A newly written test component takes throughput measurements for varying transfer sizes. A more detailed account of this story is published in an article on hackster.io.
Knowing that DMA bypasses any memory protection on the Zynq as it does not feature an IOMMU, we further spent some development efforts on implementing a custom IP block, called DMA Guard, for protecting against unintended DMA transfers from/to the FPGA. The DMA Guard is configured with a limited set of address ranges for which DMA transfers will be granted. Any out-of-range transfer will be denied. The configuration of the DMA Guard is conducted by the Zynq's platform driver based on the allocated DMA buffers. For the time being, we applied several changes to the platform driver. These modifications are currently hosted in the genode-zynq repository but are going to find their way into the generic platform driver for the next release.
More details about the DMA Guard are covered by the dedicated article: Taking control over DMA transactions on Zynq with Genode. To follow this line of work, keep watching our hackster.io channel.
Base framework and OS-level infrastructure
VFS optimization and simplification
For regular applications executed on Genode, input and output involves the virtual file system (VFS). In contrast to traditional monolithic operating systems (which host the VFS in the kernel) or traditional microkernel-based operating systems (which host the VFS in a dedicated server component), Genode's VFS has the form of a library, giving each component an individual virtual file system. The feature set of the VFS library is not fixed but extensible by so-called VFS plugins that come in the form of optional shared libraries. These plugins can implement new file-system types, but also expose other I/O facilities as pseudo files. For example, TCP/IP stacks like lwIP and lxIP (IP stack ported from Linux) have the form of VFS plugins. The extensibility of the VFS gives us extreme flexibility without compromising Genode's simplicity.
On the other hand, the pervasiveness of the VFS - being embedded in Genode's C runtime - puts it on the performance-critical path whenever application I/O is involved. The ever-growing sophistication of application workloads like running a Chromium-based web browser on the PinePhone puts merciless pressure on the VFS, which motivated the following I/O-throughput optimizations.
Even though the VFS and various VFS plugins work asynchronously, the batching of I/O operations is not consistently effective across different kernels. It particularly depends on the kernel's scheduling decision upon the delivery of asynchronous notifications. Kernels that eagerly switch to the signal receiver may thereby prevent the batching of consecutive write operations. We could observe variances of more than an order of magnitude of TCP throughput, depending on the used kernel. In the worst case, when executing a kernel that eagerly schedules the recipient of each asynchronous notification, the application performance is largely dominated by context-switching costs.
Based on these observations, we concluded that the influence of the kernel's scheduler should better be mitigated by scheduling asynchronous notifications less eagerly at the application level. By waking up a remote peer not before the application stalls for I/O, all scheduled operations would appear at the remote side as one batch.
The implementation of this idea required a slight redesign of the VFS, replacing the former implicit wakeup of remote peers by explicit wakeup signalling. The wakeup signalling is triggered not before the VFS user settles down. E.g., for libc-based applications, this is the case when the libc goes idle, waiting for external I/O. In the case of a busy writer to a non-blocking file descriptor or socket (e.g., lighttpd), the remote peers are woken up once a write operation yields an out-count of 0. The deferring of wakeup signals is accommodated by the new Remote_io mechanism (vfs/remote_io.h) that is designated to be used by all VFS plugins that interact with asynchronous Genode services for I/O.
Combined with additional adjustments of I/O buffer sizes - like the request queue of the file-system session, the TCP send buffer of the lwIP stack, or the packet buffer of the NIC session - the VFS optimization almost eliminated the variance of the I/O throughput among the different kernels and generally improved the performance. On kernels that suffered most from the eager context switching, netperf shows a 10x improvement. But even on kernels with more balanced scheduling, the effect is impressive.
While we were at it, and since this structural change affected all VFS plugins and users anyway, we took the opportunity to simplify and modernize other aspects of the VFS-related code as well.
In particular, the new interface Vfs::Env::User replaces the former Vfs::Io_response_handler. In contrast to the Io_response_handler, which had to be called on a Vfs_handle, the new interface does not require any specific handle. It is merely meant to prompt the VFS user (like the libc) to re-attempt stalled I/O operations but it does not provide any immediate hint about which of the handles have become ready for reading/writing. This decoupling led to welcome simplifications of asynchronously working VFS plugins.
Furthermore, we removed the file_size type from read/write interfaces. The former C-style pair of (pointer, size) arguments to those operations have been replaced by Byte_range_ptr and Const_byte_range_ptr argument types, which make the code safer and easier to follow. Also, the VFS utilities offered by os/vfs.h benefit from this safety improvement.
GPU performance optimizations
Session interface changes
The GPU session interface was originally developed along the first version of our GPU multiplexer for Intel devices. For this reason, the interface contained Intel specific nomenclature, like GTT and PPGTT for memory map and unmap operations. With the introduction of new GPU drivers with different architectures (e.g., Mali and Vivante), the Intel specifics should have gone away. With the current Genode release, we streamlined the map and unmap functions to semantically be more correct on all supported hardware. There are two map functions now: First, map_cpu which maps GPU graphics memory to be accessed by the CPU. And second, map_gpu which establishes a mapping of graphics memory within the GPU.
Additionally, we removed the concept of buffers (as used by Mesa and Linux drivers) to manage graphics memory and replaced it by the notion of video memory (VRAM) where VRAM stands for the actual graphics memory used by a GPU - may it be dedicated on-card memory or system RAM. The change makes it possible to separate the graphics-memory management from the buffer management as required by the Mesa library.
Intel graphics
When porting 3D applications using Mesa's OpenGL, we found that Mesa allocates and frees a lot of small GPU buffer objects (data in GPU memory) during operation. This is sub optimal for component-based systems because the Mesa library has to perform an RPC to the GPU multiplexer for each buffer allocation and for each buffer mapping. As mentioned above, we changed the session semantics from buffer object to video memory and implemented this feature within Intel's GPU multiplexer, which now only hands out VRAM. This made it possible to move the buffer handling completely to the Mesa client side (libdrm). Libdrm now allocates large chunks of video memory (i.e., 16MB) and hands out memory for buffer objects from this pool. This brings two advantages: First, the client-side VRAM pool acts as cache, which reduces the number of RPCs required for memory management significantly. Second, because of the larger VRAM allocations (compared to many 4K or 16K allocations before) fewer capabilities for the actual dataspaces that back the memory are required. Measurements showed that almost an order of magnitude of capabilities can be saved at Mesa or the client side this way.
Mali graphics
The 22.08 release introduced a driver for the GPU found in the PinePhone. Since it was merely a rapid prototype, it was limited to one client at a time, and was normally started and stopped together with its client. With this release, we remedied these limitations and enabled support for multiple concurrent clients and also revised our libdrm backend for Mesa's Lima driver.
We have not yet explored applying the same VRAM optimizations that are employed by our Intel graphics stack. One VRAM allocation still correlates to one buffer-object.
More flexible ACPI-event handling
The acpica component uses the Intel ACPICA library to parse and interpret ACPI tables and AML code. One designated feature is the monitoring of several ACPI event sources including optional reporting of information about state changes. The supported event sources are:
-
Lid, which can be open or closed
-
Smart battery (SB), information about battery parameters (e.g., capacity) and charging/discharging status
-
ACPI fixed events, e.g., power buttons
-
AC adapters, which reflect power cable plug/unplug
-
Embedded controller (EC), events like Fn-* keys, Lid, AC, SB changes
-
Vendor-specific hardware events, e.g., Fujitsu FUJ02E3 key events
Acpica optionally reports information about state changes. These reports can be monitored by other components as ROMs. The following configuration illustrates the feature:
<start name="report_rom">
<resource name="RAM" quantum="2M"/>
<provides> <service name="ROM" /> <service name="Report" /> </provides>
<config>
<policy label="acpi_event -> acpi_lid" report="acpica -> acpi_lid"/>
<policy label="acpi_event -> acpi_battery" report="acpica -> acpi_battery"/>
<policy label="acpi_event -> acpi_fixed" report="acpica -> acpi_fixed"/>
<policy label="acpi_event -> acpi_ac" report="acpica -> acpi_ac"/>
<policy label="acpi_event -> acpi_ec" report="acpica -> acpi_ec"/>
<policy label="acpi_event -> acpi_hid" report="acpica -> acpi_hid"/>
</config>
</start>
<start name="acpica">
<resource name="RAM" quantum="8M"/>
<config report="yes"/>
<route>
<service name="Report"> <child name="acpi_state"/> </service>
...
</route>
</start>
One such ACPI monitor component is acpi_event that maps ACPI events to key events of a requested Event session based on its configuration. This way, ACPI state changes can be processed like ordinary key press-release events via, for example, the event_filter. The following configuration illustrates how to map the ACPI event types to key events:
<start name="acpi_event">
<resource name="RAM" quantum="1M"/>
<config>
<map acpi="lid" value="CLOSED" to_key="KEY_SLEEP"/>
<map acpi="fixed" value="0" to_key="KEY_POWER"/>
<map acpi="ac" value="ONLINE" to_key="KEY_WAKEUP"/>
<map acpi="ec" value="20" to_key="KEY_BRIGHTNESSUP"/>
<map acpi="ec" value="21" to_key="KEY_BRIGHTNESSDOWN"/>
<map acpi="hid" value="0x4000000" to_key="KEY_FN_F4"/>
</config>
<route>
<service name="ROM" label="acpi_lid"> <child name="acpi_state"/> </service>
<service name="ROM" label="acpi_battery"> <child name="acpi_state"/> </service>
<service name="ROM" label="acpi_fixed"> <child name="acpi_state"/> </service>
<service name="ROM" label="acpi_ac"> <child name="acpi_state"/> </service>
<service name="ROM" label="acpi_ec"> <child name="acpi_state"/> </service>
<service name="ROM" label="acpi_hid"> <child name="acpi_state"/> </service>
<service name="Event"> <child name="event_filter" label="acpi"/> </service>
...
</route>
</start>
In the current release, we replaced the limited list of supported key names by a general mechanism, which supports the use of all key names declared in repos/os/include/input/keycodes.h.
Base API changes
As part of our continuous motive to streamline and simplify the framework's base API as much as possible, the current release removes the interfaces base/blocking.h, base/debug.h, and base/lock_guard.h as those headers contained parts of the API that have become obsolete by now. As a further minor change, the abs function of util/misc_math.h got removed.
The string utilities util/string.h received the new Const_byte_range_ptr type complementing the existing Byte_range_ptr. Both types are designated for passing arguments that refer to a byte buffer, e.g., the source buffer of a write operation.
On-target system-update and rollback mechanism
For the mobile version of Sculpt OS as covered in Section First system image of mobile Sculpt OS (PinePhone), we envisioned easy-to-use system updates that would enable us to quickly iterate based on the feedback of early field testers.
This topic confronted us with a variety of concerns. Just to name a few, conventions for booting that would not require changes in the future, equipping (system) images with self-reflecting version information, tools for generating and publishing digitally-signed images, on-target discovery of new image versions, secure downloading and cryptographic checking of new images, directing the machine's boot loader to use the new version, and possibly reverting to an earlier version.
Fortunately, most of these concerns have a lot in common with the problems we had to address for Genode's package management. For example, the off-target and on-target tooling for digital signatures, the notion of a depot, and the concept of federated software providers (depot users) are established and time-tested by now.
Self-reflecting version information
To allow a running Sculpt system to know its own version, the sculpt.run script generates an artificial boot module named "build_info", which can be evaluated at runtime by the sculpt-manager component.
<build_info genode_version="22.11-260-g89be3404c0d"
date="2023-01-19" depot_user="nfeske" board="pinephone">
Formalism for generating images and image metadata
To enable the Sculpt system to easily detect new versions, system images must be accompanied by metadata discoverable at a known location. This information is provided by a so-called image-index file located at depot/<user>/image/index. The image index of a depot user lists the available images in XML form, e.g.,
<index>
<image os="sculpt" board="pinephone" version="2023-01-19">
<info text="initial version"/>
</image>
...
</index>
The os, board, and version attributes can be used to infer the file name of the corresponding image file. The <info> nodes contain a summary of changes as information for the end user.
The new gems/run/sculpt_image.run script provides assistance with generating appropriately named images, placing them into the depot, and presenting a template for the manually curated image index.
Signing and publishing
For signing and publishing system images and image indices, we extended the existing tool/depot/publish tool. To publish a new version of an image index:
./tool/depot/publish <depot-user>/image/index
Each system image comes in two forms, a bootable disk image and an archive of the boot directory. The bootable disk image can be used to install a new system from scratch by copying the image directly to a block device. It contains raw block data. The archive of the boot directory contains the content needed for an on-target system update to this version. Within the depot, this archive has the form of a directory - named after the image - that contains the designated content of the boot directory on target. Depending on the board, it may contain only a single file loaded by the boot loader (e.g., uImage), or several boot modules, or even the boot-loader configuration. The following command publishes both forms:
./tool/depot/publish <depot-user>/image/<image-name>
This results in the following - accompanied by their respective .sig files - in the public directory:
<depot-user>/image/<image-name>.img.xz (disk image) <depot-user>/image/<image-name>.tar.xz (boot archive) <depot-user>/image/<image-name>.zip (disk image)
The .zip file contains the .img file. It is provided for users who download the image on a system with no support for .xz.
On-target image discovery, download, and verification
To enable a running Sculpt system to fetch image index files and images, the existing depot-download component accepts the following two new download types:
<image_index path="<user>/image/index"/> <image path="<user>/image/<name>"/>
Internally, the depot-download subsystem employs the depot-query component to determine the missing depot content. This component accepts the following two new queries:
<images user="..."/> <image_index user="..."/>
If present in the query, depot_query generates reports labeled as "images" and "image_index" respectively. These reports are picked up by the depot-download component to track the completion of each job. The reported information is also used by the system updater to get hold of the images that are ready to install.
On-target image installation and rollback
Once downloaded into the local depot of a Sculpt system, the content of the boot directory for a given image version is readily available, e.g.,
depot/nfeske/image/sculpt-pinephone-2023-02-02/uImage
The installation comes down to copying this content to the /boot/ directory. On the next reboot, the new image is executed.
When subsequently downloading new image versions, the old versions stay available in the depot as sibling directories. This allows for an easy rollback by copying the boot content of an old version to the /boot/ directory.
Device drivers
NXP i.MX Ethernet & USB
The Ethernet driver for i.MX53, i.MX6, and i.MX7 got updated to use a more recent Linux kernel version (5.11). These drivers got aligned with the source-code base originally ported for the i.MX8 SoC.
Using the recent approach to port Linux device drivers, trying to preserve the original semantic, it is necessary to provide the correct clock rates to the driver. Therefore, specific platform drivers for i.MX6 and i.MX7 were created that enable the network related clocks and export their rate values. The i.MX53 related platform driver got extended to support these clocks.
The USB host-controller driver for the i.MX 8MQ EVK is now able to drive the USB-C connector of this board too.
Realtek Wifi
As a welcoming side effect of switching to the new DDE-Linux approach, enabling other drivers that are part of the same subsystem has become less involved. In the past, we mostly focused on getting wireless devices supported by the iwlwifi driver to work as those are the devices predominantly found in commodity laptops. That being said, every now and then, one comes across a different vendor and especially with the shifting focus on ARM-based systems covering those as well became necessary.
As a first experiment, we enabled the rtlwifi driver that provides support for Realtek-based wireless devices. Due to lacking access to other hardware, the driver has been so far tested only with a specific RTL8188EE based device (10ec:8179 rev 01). Of course, some trade-offs were made as power-management is currently not available. But getting it to work, nevertheless, took barely half a day of work, which is promising.
Platforms
Base-HW microkernel
Cache-maintenance optimization
On ARM systems, the memory view on instructions and data of the CPUs, as well as between CPUs and other devices is not necessarily consistent. When dealing with DMA transfers of devices, developers of related drivers need to ensure that corresponding cache lines are cleaned before a DMA transfer gets acknowledged. When dealing with just-in-time compilation, where instructions are generated on demand, the data and instruction caches have to be aligned too.
Until now, the base-API functions for such cache-maintenance operations were mapped to kernel system calls specific to base-hw. Only the kernel was allowed to execute cache maintenance related instructions. On ARMv8 however, it is possible to allow unprivileged components to execute most of these instructions.
With this release, we have implemented the cache maintenance functions outside the kernel on ARMv8 where possible. Thereby, several device drivers with a lot of DMA transactions, e.g. the GPU driver, benefit from this optimization enormously. The JavaScript engine used in the Morph and Falkon browsers profits as well.
ACPI suspend & resume
In the previous release, we started to support the low-level ACPI suspend and resume mechanism with Genode for the NOVA kernel. With the current release, we added the required low-level support to Genode's base-hw kernel for x86 64bit platforms. Similar to the base-nova version, on base-hw the Pd::managing_system RPC function of Genode's core roottask is used to transfer the required ACPI values representing the S3 sleep state to the kernel. The kernel then takes care to halt all CPUs and flush its state to memory, before finally suspending the PC using the ACPI mechanism. On resume, the kernel re-initializes necessary hardware used by the kernel, e.g., all CPUs, interrupt controller, timer device, and serial device. One can test drive the new feature using the run/acpi_suspend scenario introduced by the former release.
Scheduling improvements for interactive workloads
As Genode conquers the PinePhone, the base-hw kernel, for the first time, has to perform real-life multimedia on a daily basis given a resource-limited mobile target. One particularly important and ambitious use case has become video conferencing in the Morph browser. A combination of an already demanding browser engine with an application that not only streams video and audio in both directions over network but also handles video and audio I/O at the device, and all that fluently and at the same time.
A lot of thinking went into how to optimize this scenario on each level of abstraction and one rather low-level lever was the scheduling scheme of the base-hw kernel. The base-hw scheduling scheme consists of a combination of absolute priority bands with execution-time quotas that prevent higher prioritized subjects from starving lower ones. There is the notion of a super period and each subject owns only a fraction of that super period as quota together with its priority. Once a subject has depleted its quota, it can't use its priority until the end of the current super period where its quota will be re-filled. However, during that time, the subject is not blocked - It can become active whenever there is no subject with priority and remaining quota present.
So, this "zero" band below all the priority bands temporarily accommodates all subjects that have a priority but that are out of quota. It contains, however, also subjects that have no priority in general. These might be tasks like a GCC compilation or a ray tracer. While prioritized tasks would be user input handlers or the display driver. Now, one difficult problem that arises with this scheduling scheme is that system integration has to decide how much quota is required by a prioritized task. The perfect value can't be determined as it depends on many factors including the target platform. Therefore, we have to consider that an important task like the audio driver in the video-conference scenario runs out of quota shortly before finishing its work.
This is already bad as is as the audio driver now has to share the CPU with many unimportant tasks until the next super period. But it became even worse because, in the past implementation, subjects always entered the zero band at the tail position. It meant that, e.g., the remaining audio handling had to wait at least until all the unprioritized tasks (e.g. long-taking computations) had used up their zero-band time slice. In order to mitigate this situation, we decided that prioritized tasks when depleting their quota become head of the zero-band, so, they will be scheduled first whenever the higher bands become idle.
This change relaxes the consequences of quota-depletion events for time-critical tasks in a typical system with many unprioritized tasks. At the same time, it should not have a significant impact on the overall schedule because depletion events are rare and zero-band time-slices short.
NOVA microhypervisor
ACPI suspend & resume
As an extension to the principal ACPI suspend and resume support introduced with the Genode 22.11 release, the NOVA kernel now supports also the re-enablement of the IOMMU after ACPI resume. The IOMMU as a hardware feature has been supported by Genode since release 13.02 and extended in release 20.11, which sandboxed device hardware and (malicious/faulty) drivers to avoid arbitrary DMA transactions.
Intel P/E cores
Starting with Intel CPU generation 12, Intel introduced CPUs with heterogeneous cores, similar to ARM's big/LITTLE concept. The new CPUs have a number of so called P-cores (performance) and E-cores (efficient), which differ in their performance and power characteristics. The CPU cores (should be) instruction compatible and are reported as identical via x86's CPUID instruction nowadays. However, an operating system such as Genode must be able to differentiate the cores in order to take informed decisions about the placement and scheduling of Genode components.
With the current release, we added support to the NOVA kernel to propagate the information about P/E cores to Genode's core roottask. In Genode's core, this information is used to group the CPU cores into Genode's affinity space. With release 20.05, we introduced the grouping of hyperthreads on the y-axis, which we keep in case the P-cores have the feature enabled. Following the P-cores and hyperthreads, all remaining E-cores are placed in the affinity space.
The following examples showcase the grouping in the affinity-space on x/y axis:
Core i7 1270P - 4 P-cores (hyperthreading enabled) and 8 E-cores:
x-axis 1 2 3 4 5 6 7 8
----------------------------------
y-axis 1 | P\ P\ P\ P\ E E E E
2 | P/ P/ P/ P/ E E E E
hyperthreads \ / of same core
Core i7 1280P - 6 P-cores (hyperthreading enabled) and 8 E-cores:
x-axis 1 2 3 4 5 6 7 8 9 10
-----------------------------------------
y-axis 1 | P\ P\ P\ P\ P\ P\ E E E E
2 | P/ P/ P/ P/ P/ P/ E E E E
hyperthreads \ / of same core
The information about the P/E cores is visible in the kernel and Genode's log output and is reported in the platform_info ROM, e.g.
kernel: [ 0] CORE:00:00:0 6:9a:3:7 [415] P 12th Gen Intel(R) Core(TM) i7-1270P ... [15] CORE:00:17:0 6:9a:3:7 [415] E 12th Gen Intel(R) Core(TM) i7-1270P ...
Genode's core: mapping: affinity space -> kernel cpu id - package:core:thread remap (0x0) -> 0 - 0: 0:0 P boot cpu remap (0x1) -> 1 - 0: 0:1 P remap (1x0) -> 2 - 0: 4:0 P remap (1x1) -> 3 - 0: 4:1 P remap (2x0) -> 4 - 0: 8:0 P remap (2x1) -> 5 - 0: 8:1 P remap (3x0) -> 6 - 0:12:0 P remap (3x1) -> 7 - 0:12:1 P remap (4x0) -> 8 - 0:16:0 E remap (4x1) -> 9 - 0:17:0 E remap (5x0) -> 10 - 0:18:0 E remap (5x1) -> 11 - 0:19:0 E remap (6x0) -> 12 - 0:20:0 E remap (6x1) -> 13 - 0:21:0 E remap (7x0) -> 14 - 0:22:0 E remap (7x1) -> 15 - 0:23:0 E ...
platform_info ROM: ... <cpus> <cpu xpos="0" ypos="0" cpu_type="P" .../> ... <cpu xpos="5" ypos="0" cpu_type="E" .../> ... <cpus> ...
Build system and tools
Building and packaging CMake-based shared libraries (via Goa)
The Goa tool streamlines the work of cross-developing, testing, and publishing Genode application software using commodity build tools like CMake. The tool is particularly suited for porting existing 3rd-party software to Sculpt OS.
Until recently, Goa was solely focused on applications whereas the porting of 3rd-party libraries required the use of the traditional approach of hand crafting build rules for Genode's build system. This limitation of Goa got lifted now.
In the new version, a Goa project can host an api file indicating that the project is a library project. The file contains the list of headers that comprise the library's public interface. The build artifact of a library is declared in the artifacts file and is expected to have the form <library-name>.lib.so. The ABI symbols of such a library must be listed in the file symbols/<library-name>. With these bits of information supplied to Goa, the tool is able to build and publish both the library and the API as depot archives - ready to use by Genode applications linking to the library. The way how all those little pieces work together is best illustrated by the accompanied example. For further details, please consult Goa's builtin documentation via goa help (overview of Goa's sub commands and files) and goa help api (specifics of the api declaration file).
When porting a library to Genode, one manual step remains, which is the declaration of the ABI symbols exported by the library. The new sub command goa extract-abi-symbols eases this manual step. It automatically generates a template for the symbols/<library-name> file from the library's built shared object. Note, however, that the generated symbols file is expected to be manually reviewed and tidied up, e.g., by removing library-internal symbols.
Thanks to Pirmin Duss for having contributed this welcomed new feature, which makes Goa much more versatile!
New tool for querying metadata of ports
The integration of third-party software into Genode is implemented via ports that specify how to retrieve, verify, and patch the source code in preparation for use with our build system. Ports are managed by tools residing in the tool/ports directory. For example, tool/ports/prepare_port is used to execute all required preparation steps.
Currently, the base Genode sources support 90 ports (you may try tool/ports/list yourself) and, thus, it's not trivial to keep track of all the ports in the repo directories. Therefore, we introduce the tool/ports/metadata tool to extract information about license, upstream version, and source URLs of individual ports. The tool can be used as follows:
./tool/ports/metadata virtualbox6 PORT: virtualbox6 LICENSE: GPLv2 VERSION: 6.1.26 SOURCE: http://download.virtualbox.org/virtualbox/6.1.26/VirtualBox-6.1.26.tar.bz2 (virtualbox) SOURCE: http://download.virtualbox.org/virtualbox/6.1.26/VirtualBoxSDK-6.1.26-145957.zip (virtualbox_sdk)
Harmonization of the boot concepts across ARM and PC platforms
To make the system-update functionality covered in Section On-target system-update and rollback mechanism equally usable across PC and ARM platforms, the conventions of booting the platforms had to be unified.
Traditionally, a bootable disk image for the PC contains a boot/ directory. E.g., when using NOVA, it contains the GRUB boot-loader config + the hypervisor + the bender pre-boot loader + the banner image + the Genode system image. This structure corresponds 1:1 to the boot/ directory as found on the 3rd partition of the Sculpt system, which is very nice. A manual system update of Sculpt comes down to replacing these files. However, on ARM platforms, SD-card images used to host a uImage file and a U-Boot environment configuration file in the root directory. The distinction of these differences complicates both the build-time tooling and the on-target handling of system updates.
The current release unifies the boot convention by hosting a boot/ directory on all platforms and reinforces the consistent naming of files. On ARM, the uImage and uboot.env files now always reside under boot/. Thanks to this uniform convention, Genode's new system update mechanism can now equally expect that a system update corresponds to the mere replacement of the content of the boot/ directory.
Minor run-tool changes
The functionality of the image/uboot_fit plugin has been integrated into the regular image/uboot plugin as both plugins were quite similar. FIT images can now be produced by adding the run option --image-uboot-fit.