
Release notes for the Genode OS Framework 8.11
Summary
This document presents the new features and major changes introduced in version 8.11 of the Genode OS Framework. It is geared towards people interested in closely following the progress of the Genode project and to developers who want to adopt their software to our mainline development. The document aggregates important fragments of the updated documentation such that you won't need to scan existing documents for the new bits. Furthermore, it attempts to provide our rationale behind the taken design decisions.
The general theme for the release 8.11 is enabling the use of the Genode OS framework for real-world applications. Because we regard the presence of device drivers and a way to reuse existing library code as fundamental prerequisites for achieving this goal, the major new additions are an API for device drivers written in C, an API for handling asynchronous notifications, and a C runtime. Other noteworthy improvements are the typification of capabilities at the C++-language level, a way for receiving and handling application faults, the introduction of managed dataspaces, and a new API for scheduling timed events.
Base framework
This section documents the new features and changes affecting the base repository, in particular the base API.
New features
Connection handling
The interaction of a client with a server involves the definition of session-construction arguments, the request of the session creation via its parent, the initialization of the matching RPC-client stub code with the received session capability, the actual use of the session interface, and the closure of the session. A typical procedure of using a service looks like this:
#include <rom_session/client.h>
...
/* construct session-argument string and create session */
char *args = "filename=config, ram_quota=4K");
Capability session_cap = env()->parent()->session("ROM", args);
/* initialize RPC stub code */
Rom_session_client rsc(session_cap);
/* invoke remote procedures, 'dataspace' is a RPC function */
Capability ds_csp = rsc.dataspace();
...
/* call parent to close the session */
env()->parent()->close(session_cap);
Even though this procedure does not seem to be overly complicated, is has raised the following questions and criticism:
-
The quota-donation argument is specific for each server. Most services use client-donated RAM quota only for holding little meta data and, thus, are happy with a donation of 4KB. Other services maintain larger client-specific state and require higher RAM-quota donations. The developer of a client has to be aware about the quota requirements for each service used by his application.
-
There exists no formalism for documenting session arguments.
-
Because session arguments are passed to the session-call as a plain string, there are no syntax checks for the assembled string performed at compile time. For example, a missing comma would go undetected until a runtime test is performed.
-
There are multiple lines of client code needed to open a session to a service and the session capability must be maintained manually for closing the session later on.
The new Connection template provides a way to greatly simplify the handling of session arguments, session creation, and destruction on the client side. By implementing a service-specific connection class inherited from Connection, session arguments become plain constructor arguments, session functions can be called directly on the Connection object, and the session gets properly closed when destructing the Connection. By convention, the Connection class corresponding to a service resides in a file called connection.h in the directory of the service's RPC interface. For each service, a corresponding Connection class becomes the natural place where session arguments and quota donations are documented. With this new mechanism in place, the example above becomes as simple as:
#include <rom_session/connection.h>
...
/* create connection to the ROM service */
Rom_connection rom("config");
/* invoke remote procedure */
Capability ds_csp = rom.dataspace();
Typed capabilities
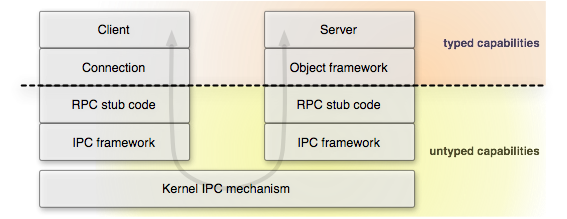
A plain Capability is an untyped reference to a remote object of any type. For example, a capability can reference a thread object or a session to a service. It is loosely similar to a C void pointer, for which the programmer maintains the knowledge about which data type is actually referenced. To facilitate the type-safe use of RPC interfaces at the C++ language level, we introduced a template for creating specialized capability types (Typed_capability in base/typed_capability.h) and the convention that each RPC interface declares a dedicated capability type. Note that type-safety is not maintained across RPC interfaces. As illustrated in Figure 1, typification is done at the object-framework level on the server side and via in the Connection classes at the client side.
|
From the application-developer's perspective, working with capabilities has now become type-safe, making the produced code more readable and robust.
See the updated API documentation for the capability representation...
Fifo data structure
Because the List data type inserts new list elements at the list head, it cannot be used for implementing wait queues requiring first-in first-out semantics. For such use cases, we introduced a dedicated Fifo template. The main motivation for introducing Fifo into the base API is the new semaphore described below.
Semaphore
Alongside lock-based mutual exclusion of entering critical sections, organizing threads in a producer-consumer relationship via a semaphore is a common design pattern for thread synchronization. Prior versions of Genode provided a preliminary semaphore implementation as part of the os repository. This implementation, however, supported only one consumer thread (caller of the semaphore's down function). We have now enhanced our implementation to support multiple consumer threads and added the semaphore to Genode's official base API. We have made the wake-up policy in the presence of multiple consumers configurable via a template argument. The default policy is first-in-first-out.
See the new API documentation for the semaphore...
Thanks to Christian Prochaska for his valuable contributions to the new semaphore design.
Asynchronous notifications
Inter-process communication via remote procedure calls requires both communication partners to operate in a synchronous fashion. The caller of an RPC blocks as long as the RPC is not answered by the called server. In order to receive the call, the server has to explicitly wait for incoming messages. There are a number of situations where synchronous communication is not suited.
For example, a GUI server wants to deliver a notification to one of its clients about new input events being available. It does not want to block on a RPC to one specific client because it has work to do for other clients. Instead, the GUI server wants to deliver this notification with fire-and-forget semantics and continue with its operation immediately, regardless of whether the client received the notification or not. The client, in turn, does not want to poll for new input events at the GUI server but it wants to be waken_up when something interesting happens. Another example is a block-device driver that accepts many requests for read/write operations at once. The operations may be processed out of order and may take a long time. When having only synchronous communication available, the client and the block device driver would have to employ one distinct thread for each request, which is complicated and a waste of resources. Instead, the block device driver just wants to acknowledge the completeness of an operation asynchronously.
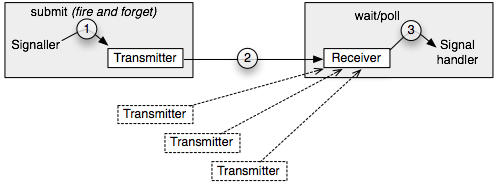
Because there are many more use cases for asynchronous inter-process communication, we introduced a new signalling framework that complements the existing synchronous RPC mode of communication with an interface for issuing and receiving asynchronous notifications. It defines interfaces for signal transmitters and signal receivers. A signal receiver can receive signals from multiple sources, whereas the sources of incoming signals are clearly distinguishable. One or multiple threads can either poll or block for incoming signals. Each signal receiver is addressable via a capability. The signal transmitter provides fire-and-forget semantics for submitting signals to exactly one signal receiver. Signals are communicated in a reliable fashion, which means that the exact number of signals submitted to a signal transmitter is communicated to the corresponding signal receiver. If notifications are generated at a higher rate than as they can be processed at the receiver, the transmitter counts the notifications and delivers the total amount with the next signal transmission. This way, the total number of notifications gets properly communicated to the receiver even if the receiver is not highly responsive. Notifications do not carry any payload because this payload would have to be queued at the transmitter.
|
Image 2 illustrates the roles of signaller thread, transmitter, receiver, and signal-handler thread.
See the new API documentation for asynchronous notifications...
The current generic implementation of the signalling API employs one thread at each transmitter and one thread at each receiver. Because the used threads are pretty heavy weight with regard to resource usage, ports of Genode should replace this implementation with platform- specific variants, for example by using inter-process semaphores or native kernel support for signals.
Region-manager faults
In Genode, region-manager (RM) sessions are used to manage the address-space layout for processes. A RM session is an address-space layout that can be populated by attaching (portions of) dataspaces to (regions of) the RM session. Normally, the RM session of a process is first configured by the parent when decoding the process' ELF binary. During the lifetime of the process, the process itself may attach further dataspaces to its RM session to access the dataspace's content. Core as the provider of the RM service uses this information for resolving page faults raised by the process. In prior versions of Genode, core ignored unresolvable page faults, printed a debug message and halted the page-faulted thread. However, this condition may be of interest, in particular to the process' parent for reacting on the condition of a crashed child process. Therefore, we enhanced the RM interface by a fault-handling mechanism. For each RM session, a fault handler can be installed by registering a signal receiver capability. If an unresolvable page fault occurs, core delivers a signal to the registered fault handler. The fault handler, in turn, can request the actual state of the RM session (page-fault address) and react upon the fault. One possible reaction is attaching a new dataspace at the fault address and thereby implicitly resolving the fault. If core detects that a fault is resolved this way, it resumes the operation of the faulted thread.
This mechanism works analogously to how page faults are handled by CPUs, but on a more abstract level. A (n-level) page table corresponds to a RM session, a page-table entry corresponds to a dataspace- attachment, the RM-fault handler corresponds to a page-fault exception handler, and the resolution of page-faults (RM fault) follows the same basic scheme:
-
Application accesses memory address with no valid page-table-entry (RM fault)
-
CPU generates page-fault exception (core delivers signal to fault handler)
-
Kernel reads exception-stack frame or special register to determine fault address (RM-fault handler reads RM state)
-
Kernel adds a valid page-table entry and returns from exception (RM-fault handler attaches dataspace to RM session, core resumes faulted thread)
The RM-fault mechanism is not only useful for detecting crashing child processes but it enables a straight-forward implementation of growing stacks and heap transparently for a child process. An example for using RM-faults is provided at base/src/test/rm_fault.
Note that this mechanism is only available on platforms on which core resolves page faults. This is the case for kernels of the L4 family. On Linux however, the Linux kernel resolves page faults and suspends processes performing unresolvable memory accesses (segmentation fault).
Managed dataspaces (experimental)
The RM-fault mechanism clears the way for an exciting new feature of Genode 8.11 called managed dataspaces. In prior versions of Genode, each dataspace referred to a contiguous area of physical memory (or memory-mapped I/O) obtained by one of core's RAM, ROM, or IO_MEM services, hence we call them physical dataspaces. We have now added a second type of dataspaces called managed dataspaces. In contrast to a physical dataspace, a managed dataspace is backed by the content described by an RM session. In fact, each RM session can be used as dataspace and can thereby be attached to other RM sessions.
Combined with the RM fault mechanism described above, managed dataspaces enable a new realm of applications such as dataspaces entirely managed by user-level services, copy-on-write dataspaces, non-contiguous large memory dataspaces that are immune to physical memory fragmentation, process-local RM fault handlers (e.g., managing the own thread-stack area as a sub-RM-session), and sparsely populated dataspaces.
Current limitations
Currently, managed dataspaces still have two major limitations. First, this mechanism allows for creating cycles of RM sessions. Core must detect such cycles during page-fault resolution. Although, a design for an appropriate algorithm exists, cycle-detection is not yet implemented. The missing cycle detection would enable a malicious process to force core into an infinite loop. Second, RM faults are implemented using the new signalling framework. With the current generic implementation, RM sessions are far more resource-demanding than they should be. Once the signalling framework is optimized for L4, RM sessions and thereby managed dataspaces will become cheap. Until then, we do not recommend to put this mechanism to heavy use.
Because of these current limitations, managed dataspaces are marked as an experimental feature. When building Genode, experimental features are disabled by default. To enable them, add a file called specs.conf with the following content to the etc/ subdirectory of your build directory:
SPECS += experimental
For an example of how to use the new mechanism to manage a part of a process' own address space by itself, you may take a look at base/src/test/rm_nested.
Changes
Besides the addition of the new features described above, the following parts of the base framework underwent changes worth describing.
Consistent use of typed capabilities and connection classes
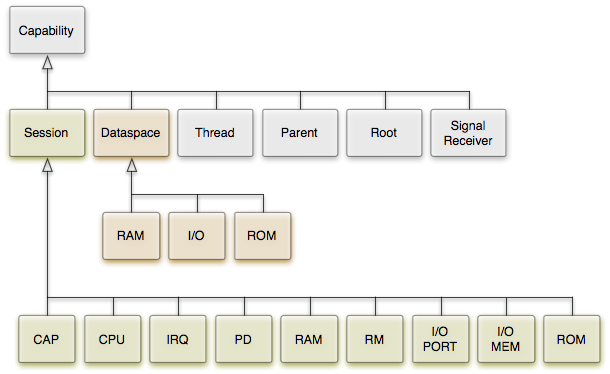
We applied capability typification to all interfaces of Genode including the base API and the interfaces defined in the os repository. Figure 3 provides an overview about the capability types provided by the base API.
|
|
Overview about the capability types provided by the base API
|
Furthermore, we have complemented all session interfaces with appropriate Connection classes taking service-specific session arguments into account.
For session-interface classes, we introduced the convention to declare the service name as part of the session-interface via a static member function:
static const char *service_name();
Allocator refinements
Throughout Genode, allocators are not only used for allocating memory but also for managing address-space layouts and ranges of physical resources such as I/O-port ranges or IRQ ranges. In these cases, the address 0 may be a valid value. Consequently, this value cannot be used to signal allocation errors as done in prior versions of Genode. Furthermore, because managed dataspaces use the RM session interface to define the dataspace layout, the address-'0' problem applies here as well. We have now refined our allocator interfaces and the RM-session interface to make them fit better for problems other than managing virtual memory.
Misc changes
We revised all interfaces to consistently use exceptions to signal error conditions rather than delivering error codes as return values. This way, error codes become exception types that have a meaningful name and, in contrast to global errno definitions, an error exception type can be defined local to the interface it applies to. Furthermore, the use of exceptions allows for creating much cleaner looking interfaces.
Traditionally, we have provided our custom printf implementation as C symbol to make this function available from both C and C++ code. However, we observed that we never called this function from C code and that the printf symbol conflicts with the libc. Hence, we turned printf into a C++ symbol residing in the Genode namespace.
Operating-system services and libraries
This section documents the new features and changes affecting the os repository.
New Features
Device-driver framework for C device drivers
Genode's base API features everything needed to create user-level device drivers. For example, the os repository's PS/2 input driver and the PCI bus driver are using Genode's C++ base API directly. However, most of today's device drivers are written in C. To ease the reuse of existing drivers on Genode, we have introduced a C API for device drivers into Genode's os repository. The API is called DDE kit (DDE is an acronym for device-driver environment) and it is located at os/include/dde_kit.
The DDE kit API is the result of long-year experiences with porting device drivers from Linux and FreeBSD to custom OS environments. The following references are the most significant contributions to the development of the API. Christian Helmuth created the initial version of the Linux device-driver environment for L4. He describes his effort of reusing unmodified sound drivers on the L4 platform in his thesis Generische Portierung von Linux-Gerätetreibern auf die DROPS-Architektur. Gerd Griessbach approached the problem of re-using Linux USB drivers by following the DDE approach in his diploma thesis USB for DROPS. Marek Menzer adapted Linux DDE to Linux 2.6 and explored the DDE approach for block-device drivers in his student research project Portierung des DROPS Device Driver Environment and his diploma thesis Entwicklung eines Blockgeräte-Frameworks für DROPS. Thomas Friebel generalized the DDE approach and introduced the DDE kit API to enable the re-use of device driver from other platforms than Linux. In particular, he experimented with the block-device drivers of FreeBSD in his diploma thesis Übertragung des Device-Driver-Environment-Ansatzes auf Subsysteme des BSD-Betriebssystemkerns. Dirk Vogt successfully re-approached the port of USB device drivers from the Linux kernel to L4 in his student research project USB for the L4 Environment.
The current incarnation of the DDE kit API provides the following features:
-
General infrastructure such as init calls, assertions, debug output
-
Interrupt handling (attach, detach, disable, enable)
-
Locks, semaphores
-
Memory management (slabs, malloc)
-
PCI access (find device, access device config space)
-
Virtual page tables (translation between physical and virtual addresses)
-
Memory-mapped I/O, port I/O
-
Multi-threading (create, exit, thread-local storage, sleep)
-
Timers, jiffies
For Genode, we have created a complete reimplementation of the DDE kit API from scratch by fully utilizing the existing Genode infrastructure such as the available structured data types, core's I/O services, the synchronization primitives, and the thread API.
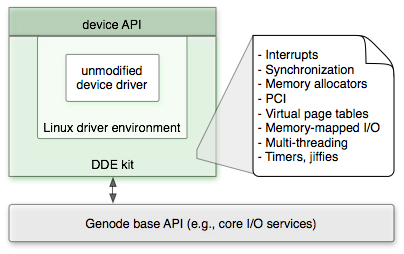
|
Figure 4 illustrates the role of DDE kit when re-using an unmodified device driver taken from the Linux kernel. DDE kit translates Genode's C++ base API to the DDE kit C API. The DDE kit API, in turn, is used as back end by the Linux driver environment, which translates Linux kernel interfaces to calls into DDE kit. With this translation in place, an unmodified Linux device driver can be embedded into the Linux driver environment. The device API is specific for a class of devices such as NICs, block devices, or input devices. It can either be used directly as a function interface by an application that is using the device driver as a library, or it can be made accessible to external processes via an RPC interface.
Limitations
The PCI sub system is not completely implemented, yet.
Alarm API providing a timed event scheduler
The scheduling of timed events is a recurring pattern found in device drivers, application frameworks such as Qt4 (qeventdispatcher), and applications. Therefore, we have added a timed event scheduler to the os repository. The new alarm API (os/include/os/alarm.h) allows for the scheduling of both one-shot alarms and periodic alarms.
Changes
PS/2 input driver
The original PS/2 driver tried to switch the PS/2 keyboard to scan-code set 2 and assumed that all modern keyboards support this mode of operation. However, this assumption was wrong. We observed that the legacy PS/2 support of some USB keyboards covers only the emulated (xlate) scan-code set 1 mode. This is also case for the PS/2 emulation in VirtualBox. Therefore, we changed our PS/2 driver to never touch the keyboard mode but to only detect the current mode of operation. The driver has now to support both, scan-code set 1 and scan-code set 2. This change comes along with a slightly more complex state machine in the driver. Hence, we moved the state machine from the IRQ handler to a distinct class and changed the control flow of the driver to fetch only one value from the i8042 PS/2 controller per received interrupt.
PCI bus driver
Until now, Genode's PCI bus driver was only used for experimentation purposes. With the forthcoming driver framework however, the PCI bus driver will play a central role in the system. Therefore, we adapted the interface of the PCI driver to these requirements. Specifically, the scanning of the PCI bus can now be performed without constraining the results by a specific vendor ID.
Nitpicker GUI server
We improved the output_latency of the Nitpicker GUI server by flushing pixels eagerly and deferring the next periodically scheduled flush. This change has a positive effect on the responsiveness of the GUI to user input.
Misc changes
Prior versions of the os repository came with a custom os/include/base directory with interfaces extending the base API. To avoid confusion between the base repository and the os repository, os-local API extensions are now located at os/include/os. This way, the folder prefix of include statements indicates well from which repository the included header files comes from.
C runtime
Most of existing libraries rely on the presence of a C library. For making the reuse of this software on Genode possible, we have now made a complete C library available for Genode. It comes as a separate source-code repository called libc and is based on the code of FreeBSD. The original code is available at the official FreeBSD website.
- FreeBSD website
Our libc port comprises the libraries gdtoa, gen, locale, stdio, stdlib, stdtime, string, and msun. Currently, it supports the x86 architecture. Support for other architectures is planned as future addition. At the current stage, our back end is very basic and most of its functions are dummy stubs. We used Christian Prochaska's forthcoming Genode port of Qt4 as test case and successfully used the new libc as foundation for building graphical Qt4 applications. We will further extend the back end in correspondence to the growing feature set of the Genode OS framework.
- Usage
To use the libc in your application, just add libc to the LIBS declaration in your build-description file. This declaration will make the libc headers available for the include path of your target and link the C library. When building, make sure that the libc repository is included in your build configuration (etc/build.conf).
- Limitations
The current version of the C library is not thread-safe. For most string and math functions, this is not a problem (as these functions do not modify global state) but be careful with using more complex functions such as malloc from multiple threads. Also, errno may become meaningless when calling libc functions from multiple threads.
We have left out the following files from the Genode port of the FreeBSD libc: gdtoa strtodnrp.c (gdtoa), getosreldate.c (gen), strcoll.c, strxfrm.c, wcscoll.c, wcsxfrm.c (string), s_exp2l.c (msun).
The current back end is quite simplistic and it may help you to revisit the current state of the implementation in the libc/src/lib/libc directory. If one of the functions in dummies.c is called, you will see the debug message:
"<function-name> called, not yet implemented!"
However, some of the back-end function implemented in the other files have dummy semantics but have to remain quiet because they are called from low-level libc code.
Build infrastructure
Build-directory creation tool
Because we think that each Genode developer benefits from knowing the basics about the functioning of the build system, the manual creation of build directories is described in Genode's getting-started document. However, for regular developers, creating build directories becomes a repetitive task. Hence, it should be automated. We have now added a simple build-directory creation tool that creates pre-configured build directories for some supported platforms. The tool is located at tool/builddir/create_builddir. To print its usage information, just execute the tool without arguments.
Improved linking of binary files
For linking binary data, binary file have to be converted to object files. Over the time, we have used different mechanisms for this purpose. Originally, we used ld -r -b binary. Unfortunately, these linker options are not portable. Therefore, the mechanism was changed to a hexdump and sed magic that generated a C array from binary data. This solution however, is complicated and slow. Now, we have adopted an idea of Ludwig Hähne to use the incbin directive of the GNU assembler, which is a very clean, flexible, and fast solution.
Lib-import mechanism
Libraries often require specific include files to be available at the default include search location. For example, users of a C library expect stdio.h to be available at the root of the include search location. Placing the library's include files in the root of the default search location would pollute the include name space for all applications, regardless if they use the library or not. To keep library-include files well separated from each other, we have enhanced our build system by a new mechanism called lib-import. For each library specified in the LIBS declaration of a build description file, the build system incorporates a corresponding import-<libname>.mk file into the build process. Such as file defines library-specific compiler options, in particular additional include-search locations. The build system searches for lib-import files in the lib/import/ subdirectories of all used repositories.
Using ar for creating libraries
The previous versions of Genode relied on incremental linking (ld -r) for building libraries. This approach is convenient because the linker resolves all cross-dependencies between libraries regardless of the order of how libraries are specified at the linker's command line. However, incremental linking prevents the linker from effectively detecting dead code. In contrast, when linking .a files, the linker detects unneeded object files. Traditionally, we have only linked our own framework containing no dead code. This changed with the new libc support. When linking the libc, the presence of dead code becomes the normal case rather than the exception. Consequently, our old incremental-linking approach produced exceedingly large binaries including all functions that come with the libc. We have now adopted the classic ar mechanism for assembling libraries and use the linker's start-group end-group feature to resolve inter-library-dependencies. This way, dead code gets eliminated at the granularity of object files. In the future, we will possible look into the -ffunction-sections and -gc-sections features of the GNU tool chain to further improve the granularity to function level.
If your build-description files rely on custom rules referring to lib.o files, these rules must be adapted to refer to lib.a files instead.
Misc changes
-
Added sanity check for build-description files overriding INC_DIR instead of extending it.
-
Restrict inclusion of dependency files to those that actually matter when building libraries within var/libcache. This change significantly speeds up the build process in the presence of large libraries such as Qt4 and libc.
-
Added rule for building cpp files analogously to the cc rule. Within Genode, we name all C++ implementation files with the cc suffix. However, Qt4 uses cpp as file extension so we have to support both.
-
Build-description files do no longer need the declaration REQUIRES = genode. Genode's include search locations are now incorporated into the build process by default.
Applications
This section refers to the example applications contained in Genode's demo repository.
We have enhanced the Scout_widgets as used by the launchpad and the Scout tutorial browser to perform all graphical output double-buffered, which effectively eliminates drawing artifacts that could occur when exposing intermediate drawing states via direct (unbuffered) output. Furthermore, we have added a way to constrain the maximum size of windows to perform pixel-buffer allocations on realistic window sizes.
Both launchpad and Scout can now start child applications. In Scout this functionality is realized by special "execute" links. We have generalized the underlying application logic for creating and maintaining child processes between both applications and placed the unification into a separate launchpad library.
We have replaced the default document presented in Scout with an interactive_walk-through_guide explaining the basic features of Genode. The document uses the new "execute" link facility to let the user start a launchpad instance by clicking on a link.
Platform-specific changes
Genode used to define fixed-width_integer_types in a file stdint.h placed in a directory corresponding to bit-width of the platform, for example include/32bit/stdint.h. When building for a 32bit platform, the build system included the appropriate directory into the include-search path and thereby made stdint.h available at the root of the include location. Unfortunately, this clashes with the stdint.h file that comes with the C library. To avoid conflict with libc header files, we moved the definition of fixed-width integer types to 32bit/base/fixed_stdint.h.
For the L4/Fiasco version of Genode, there existed some x86-specific header files that did not specifically depend on L4/Fiasco, for example atomic operations. Because these files are not L4/Fiasco-specific and may become handy for other platforms as well, we moved them to the generic base repository.
Linux 32bit
- Dissolving Genode's dependency from the glibc
The port of the C runtime to Genode posed an interesting challenge to the Linux version of Genode. This version used to rely on certain functions provided by the underlying glibc:
-
For creating and destroying threads, we used to rely on POSIX threads as provided by the pthread library
-
The lock implementation was based on the POSIX semaphore functions sem_init, sem_wait, and sem_post
-
Shared memory was realized by using files (open, close, ftruncate) and the mmap interface
-
Starting and killing processes was implemented using fork and kill
-
Inter-process communication used the glibc's socket functions
For our custom C runtime, we want to override the glibc functionality with our own implementation. For example, we want to provide the mmap interface to a Genode application by implementing mmap with functions of our base API. On Linux, however, this base API, in turn, used to rely on mmap. This is just an example. The problem applies also for the other categories mentioned above. We realized that we cannot rely on the glibc on one hand but at the same time replace it by a custom C runtime (in fact, we believe that such a thing is possible by using awkward linker magic but we desire a clean solution). Consequently, we have to remove the dependency of Genode from the glibc on Linux. Step by step, we replaced the used glibc functions by custom Linux system-call bindings. Each binding function has a prefix lx_ such that the symbol won't collide with libc symbols. The new bindings are located at the file base-linux/src/platform/linux_syscalls.h. It consist of 20 functions, most of them resembling the original interface (socket, connect, bind, getsockname, recvfrom, write, close, open, fork, execve, mmap, ftruncate, unlink, tkill, nanosleep). For other functions, we simplified the semantics for our use case (sigaction, sigpending, sigsetmask, create_thread). The most noteworthy changes are the creation and destruction of threads by directly using the clone and tkill system calls, and the lock implementation. Because we cannot anymore rely on the convenience of using futexes indirectly through the POSIX semaphore interface, we have adopted the simple locking approach that we already use for the L4/Fiasco version. This lock implementation is a simple sleeping spinlock.
- Compromises
The introduction of custom Linux system-call bindings for Genode has several pros and cons. With this change, The Linux version of Genode is not anymore easy to port to other POSIX platforms such as the Darwin kernel. For each POSIX kernel used as Genode platform, a custom implementation of our system-call bindings must be created. The original POSIX variant could still be reanimated, but this version would inherently lack support for Genode's C runtime, and thus would have limited value. A positive side effect of this solution, however, is that linux_syscalls.h documents well the subset of the Linux' kernel interface that we are actually using.
The replacement of POSIX semaphores with sleeping spinlocks decreases locking performance quite significantly. In the contention case, the wakeup from sleeping introduces a high latency of up to one millisecond. Furthermore, fairness is not guaranteed and the spinning produces a bit of system load. If this approach turns out to become a serious performance bottleneck, we will consider creating custom bindings for Linux' futexes.
L4/Fiasco
The concepts of RM_faults and managed_dataspaces as described in Section Base framework, had been implemented into the L4/Fiasco version of core. Although the introduction of these concepts involved only minimal changes at the API level, the required core-internal changes had been quite invasive, affecting major parts of the pager and RM-session implementations.
Prior versions of the L4/Fiasco version of core did not implement the cancel-blocking_mechanism as specified by the CPU-session API. The missing implementation resulted in lock-ups when destructing a thread that blocks for lock. With the new implementation based on L4/Fiasco's inter-task ex-regs system call, such threads can now be gracefully destructed.