
How Genode came to the Pandaboard
The Pandaboard is one of the most popular low-cost development boards featuring a multi-core ARM-Cortex-A9 CPU, more specifically the Texas Instruments OMAP4 SoC. This article describes the journey of the Genode developers to make the Genode OS Framework available on this platform. Besides the challenge to principally support a wide range of peripherals including networking-over-USB, HDMI, and SD cards, we have put a particular emphasis on performance analysis and optimization. The reason for doing so was to put the platitude that microkernel-based systems are inherently slow into perspective.

|
All work described in the article is available in the master branch of the Genode repository at Github. If you can get your hands on a Pandaboard, there is nothing to hold you back from trying out the described features.
- Genode repository at GitHub
The Fiasco.OC kernel as starting point
Of all Genode's supported base platforms, we found Fiasco.OC best suited for running Genode on the Pandaboard as this kernel supports the OMAP4 SoC out of the box. Even though we later discovered a few deficiencies of the level of OMAP4 support provided by the kernel, in particular with regard to clock calibration and cache management, while the fundamental platform support for running Genode's core, init, and timer components on this platform was straight-forward. Thanks to the Fiasco.OC developers for the smooth ride!
With the initial road block out of the way, let's dive right in into the diverse world of peripherals provided by the OMAP4 SoC. We will start our journey with graphics output via the HDMI connector, then move on to the support of USB and networking. Finally, we will conquer the access to SD-cards.
HDMI output
For enabling HDMI output, we first started implementing a driver from scratch by taking the comprehensive OMAP4 "Technical Reference Manual" as a guide. Of the 5500 pages, more than 500 pages are concerned with the display subsystem. The level of complexity is quite astounding. However, the documentation is well written so we got a pretty good understanding on how the different components work together. When booting, all parts are suspended and idle. So the clock and power management was the next topic to investigate (which is described in just another 700 pages of the reference manual). In hindsight, the most elaborative part so far was to set up the clock and power management to actually switch on the required subsystems. With our custom driver, we managed to perform the display subsystem initialization.

|
We were quite happy with the progress at this point. But then we hit a hard problem: The display subsystem would not fetch our display controller configuration for the TV parameters. These parameters are programmed into shadow registers that are fetched to the real registers by the hardware on each VSYNC signal. Apparently the generation of the VSYNC signal was still missing. We just discovered that this VSYNC signal is generated from a separate hardware component (HDMI chip), which is not covered in the Technical Reference Manual at all. Apparently, there exists no public documentation of this chip other than the Linux driver created by Texas Instruments. By looking at the driver alone, it is extremely hard to guess what is needed to get the HDMI chip into working state. The Linux OMAP video driver (driver/video/omap2) is over 28.000 lines of code. In addition to the actual driver code, the platform initialization code (arch/arm/mach-omap2) is required to set up the environment (such as OMAP4 GPIO pins) that seem to be crucial for operating the HDMI chip. Finding the right spots in the platform code is very difficult as the code is comprised of more than 96.000 lines of code.
So what to do when only having the extremely complex Linux driver as source of documentation? One promising idea is to run the Linux kernel and trace all memory-mapped I/O (MMIO) accesses that are related to the display driver. This is what we have done. Thanks to our custom configured and hand built Linux kernel, we became able to trace the MMIO accesses that the kernel performs on the platform by instrumenting the relevant hardware access functions. Initially, we found those traces to be exceedingly large. So the next step was to cut down the Linux kernel to do not much more than merely initializing the HDMI video. This was a long-winded process that required us to iteratively modify the kernel and see if the HDMI output still worked. In parts, this work provided interesting insights. For example, the HDMI subsystem is switched off and on four times during the initialization. In order to minimize the trace, we changed the Linux code to avoid such unnecessary repetitions. This way, we managed to strip down the trace of MMIO accesses from several thousands to only 300 MMIO register accesses. The obtained trace served as us as a kind of how-to guide of using the display subsystem. We could go through the trace step by step, lookup the registers in the manual and this way gathered the puzzle pieces needed to get the device into a functional state.

|
The resulting HDMI driver is located at os/src/drivers/framebuffer/omap4. It has been developed using the Genode API directly. In particular, it facilitates the use of Genode's MMIO framework that largely decouples the specification of register layouts from the driver logic. The driver sets up a predefined video mode XGA (1024x768) in the RGB565 pixel format.
USB keyboard and mouse
On the Pandaboard, keyboard and mouse input is realized through USB HID. Hence, we needed to enable Genode's USB stack to work on this platform. As a basis we used the USB stack introduced with Genode 12.05. It is based on the USB stack of the Linux kernel version 3.2. Thanks to our approach of porting this complex driver system, we did not need to change original Linux code. Instead, we supplemented the unmodified Linux driver code with a custom implementation of the Linux API the driver relies on. The original version of the USB stack was created for the PC platform. Now, we needed to incorporate support for the USB host controller as found on the OMAP4 platform. This was not a major hurdle and quickly came to the point where the USB host controller on the OMAP4 could be successfully initialized. But at this point, we hit a major difficulty, namely caching.
Caches - always good for a surprise
During our work on USB and HDMI, we noticed an unwelcome interference of memory caches and DMA. For example, the USB controller uses DMA for data transfer. DMA is done in normal RAM, which, however, is subjected to caching. On x86, this is not a problem because the DMA is participating in the cache-coherence protocol. But on ARM, this is not the case. The result is that data received from the USB via DMA is not always correct. Sometimes (if there is a cache hit) data is read not from the RAM (where the DMA data has landed) but from the cache. Vice versa, data provided to the USB via DMA is not always correct either because the cache is not written through the RAM as fetched by the DMA. We validated this hypothesis by disabling caches altogether (by patching the Fiasco.OC kernel). In this setup these so-called aliasing effects disappeared.
At this point, we had two alternatives of how to deal with this problem. First, we could explicitly flush, invalidate, and clear the cache lines used for the RAM locations that contain the DMA buffers. This solution is principally supported by the Fiasco.OC kernel but the Linux USB stack is not prepared for it. So we would have had to modify the 3rd-party code of the USB stack. The second possible solution would have been to introduce a special category of memory (DMA memory) for DMA operations into the Genode API. Under the hood, Genode would then take care to mark the memory pages of DMA memory as uncached in the page tables. This is the way how this is principally done in the Linux kernel. But unfortunately, there seemed to be no straight-forward way to explicitly set cache attributes when using the Fiasco.OC kernel. At the first glance, the first solution (explicitly flush/invalidate/clear the cache) looked more attractive to us because we would not need to consider changing the Fiasco.OC kernel. On the other hand, modifying the 3rd-party USB code would pose a maintenance liability in the future. We finally settled on the variant that introduced DMA memory as a first-class Genode citizen. The allocation of DMA buffers is done by a new argument of the Genode::Ram_session::alloc() function. The returned dataspace will carry the information with it that it is intended to be used as DMA buffer. In addition, core ensures that the cache is void of any memory content referred to by the dataspace. This is achieved by calling Fiasco.OC's l4_cache_clean_data API. Each time, the resulting dataspace gets attached to an address space, the page table attributes of the process are populated accordingly. While implementing this solution, we found that there is indeed a way to implicitly sneak the right attributes through the Fiasco.OC kernel into the page table via attributes of flex-page mapping items as used during page-fault handling. Because DMA buffers are solely allocated by core, core can maintain the consistency of page-table attributes across all processes of the system.
We found that this mechanism works well for the L1 cache. But since Fiasco.OC does not implement the l4_cache_clean_data API for the L2 cache of the OMAP4 platform, cache artifacts still occur when enabling the L2 cache. To side-walk this problem, we decided to disable the L2 cache at boot time entirely. Of course, this should not be done light-heartily if performance matters. We were afraid to experience a major performance drop due to disabling the L2 cache. To get an impression of the severity of the problem, we experimented with disabling the L2 cache for Ubuntu. Much to our surprise, the L2 cache apparently does not have an overwhelming effect on the performance of Ubuntu, at least as visibly perceived by us. Later, during our performance analysis, we were even able to largely confirm this assumption.
Networking
Networking support for the Pandaboard is realized via USB. Hence, a working USB driver is the prerequisite for networking support. We enhanced our USB driver with support for the SMSC95XX networking chip. To speak of the USB driver as a Genode component, it is a process that offers multiple services, namely Input (USB HID), Block (USB storage), and Nic (networking). To compare our driver against a native Linux kernel, we first measured the networking throughput using Ubuntu 12.04. Using the native Linux kernel, the network device could be saturated. We found the throughput to be around 11 MiB/sec.

|
To quantify the performance of our driver, we used the same benchmark but executed it on L4Linux that runs as user-level Genode component. The driver is a separate component that runs in a different address space. L4Linux talks to the driver through a Genode session interface. Naturally, compared to native Linux where both the driver and the TCP/IP stack reside in a single address space (the kernel), the Genode system is expected to introduce overhead caused by the context switches between the driver process and the L4Linux kernel process.
The baseline of our original driver implementation in this scenario was far beyond the performance of native Linux. We measured a throughput of only 3.5 MiB/sec. Are microkernel-based systems that slow? We would certainly not have thought so. Hence, we found that the time was right for optimizations.
Structural differences between Linux and L4Linux
We identified the following conceptual differences between Linux and L4Linux that could lead to the lack of performance in the L4Linux case. Most of our analysis was done for outbound traffic. The following description refers to the transmission of packets.
- Allocation overhead
Linux allocates one SKB per network packet only and passes it to the network driver. The driver creates an USB request block (URB) pointing to the SKB such that the hardware can fetch the payload directly from the SKB via DMA. The granularity of network packets does not attribute much to the overall costs because an SKB allocation happens only once per packet and only pointers to SKBs, not actual data, are being passed around.
In contrast when using L4Linux, the network stub driver needs to copy the contents of the SKB (originating from the TCP/IP stack) into Genode's packet-stream buffer shared between L4Linux and the USB driver process. This operation does not only involve copying bytes but also requires an allocation of a packets. At the USB-driver side, the driver receives data from the packet-stream interface. Because it needs to pass this data to USB stack that expects SKBs arguments, the driver needs to dynamically allocate an SKB and fill it with the data received from the packet stream. Furthermore, The USB driver needs to dynamically allocate an URB per packet in order to submit the network packet to the hardware interface.
Clearly, the insertion of an address-space boundary between the Linux kernel and the USB driver implies substantial costs per packet caused by dynamic allocations and the copying of payload data.
- Loosely coupled control flows
Whereas the Linux kernel has a single flow of control between the driver code and the TCP/IP code, L4Linux combined with USB driver component uses two components that are loosely coupled via Genode's packet stream interface. The alternative of tightly coupling the control flows of both components is infeasible because this would imply two context switches per network packet. Instead, the packet-stream interface uses a queue of network packets stored in a memory buffer shared by both L4Linux and the USB driver. The synchronization of both participants is realized by using Genode's signalling mechanism. Even though the loose coupling reduces context switch overhead, it introduces latency that is not present in the original Linux kernel. This has two potential consequences:
-
Linux code on both sides (L4Linux as well as in the USB driver) might behave differently compared with native Linux because of the latency characteristics of the packet stream interface.
-
The behaviour of both the L4Linux kernel and the USB driver inherently depend not only on the scheduler of one kernel but on the schedulers of L4Linux, the Fiasco.OC microkernel, and the local scheduling of the USB driver. Consequently, compared with a single Linux kernel, the behaviour of the decomponentized scenario is much harder to predict and to reason about.
- CPU load caused by interrupts
On a microkernel-based multi-server OS, both the costs and (potentially) latencies of interrupts are higher than for a monolithic kernel. On native Linux, the interrupt handler becomes immediately active when a device event occurs. On a microkernel-based system, a device interrupt is first handled by the kernel, which translates the interrupt into a message to the user-level interrupt handler in core. Core, in turn, propagates this message to the USB driver. The USB driver uses a dedicated IRQ thread for the reception of interrupts but it does not immediately execute the interrupt handler. Instead, the USB driver schedules the handling of the interrupt not before a defined preemption point is reached. The synchronization between the IRQ thread and the USB main thread (which executes the actual device-driver code) uses Genode's signalling mechanism. This mechanism, in turn, performs a round trip to core for each signal.
Clearly, the flow of control in the time from the occurrence of a device interrupt and the driver entering the IRQ handling code is much more complex compared to the monolithic case. The open question was: Does this cost dominate the driver performance or is it negligible?
Optimization of allocators
Section Structural differences between Linux and L4Linux suggests that there is a significant overhead in terms of dynamic memory allocations in the L4Linux case. By default, we almost universally used an AVL-tree-based best-fit allocator for all kinds of dynamically allocated objects including URBs, SKBs, and packet-stream entries.
By microbenchmarking the individual steps performed by the USB driver using the Fiasco.OC trace buffer, we identified that the allocators consume considerable CPU time. So we started to replace them by less general but more optimized variants. For example, instead of using an AVL tree to keep track of free chunks in the packet-stream buffer, we opted for a bit allocator with fixed-sized slots similar to a slab allocator. These optimizations yielded a substantial gain in performance. As a general pattern, we observed that replacing one general AVL-tree-based allocator with a fast special-purpose allocator improved the throughput by 500 - 800 KiB/sec. There are three allocators that are invoked per packet and thereby are subject to this kind of optimization (for outbound communication):
-
The packet-stream allocator on the L4Linux side,
-
The SKB allocator at the USB driver,
-
The general memory allocator at the USB driver, which happens to be used as allocator for URBs.
The performance gained by optimizing dynamic memory allocations was clearly beneficial. As predicted, the optimization led to throughput improvements in the order of 2 MiB/sec, yielding an overall throughput of 5-6 MiB/sec. This is a significant improvement but still well below our goal to achieve at least 90% of the throughput of native Linux.
Cached versus uncached memory objects
The Linux driver code in the USB driver uses kmalloc to allocate memory objects. Some of these objects are used for DMA operations, which immediately triggers cache-coherency problems on the Cortex-A9 platform when mapping the backing-store memory as cached pages. To mitigate such cache coherency problems, our original implementation of kmalloc used uncached RAM dataspaces as backing store. However, memory objects allocated by kmalloc are frequently used by code unrelated to DMA. In these cases, we wanted to avoid to the costs of accessing uncached memory.
To distinguish allocations of cached from uncached memory objects, we had to slightly modify the Linux driver code by adding hints passed to kmalloc. Our kmalloc implementation, in turn, responds to these hints by performing the respective allocation from either an uncached memory pool or a cached memory pool.
This optimization improved the throughput by yet another 1 MiB/sec.
Avoiding and optimizing memcpy
In contrast to native Linux, the L4Linux scenario carries an inherent memory-copying overhead. We followed two lines of work, which are the avoidance of memcpy and the optimization of memcpy.
As an experiment, we tried to avoid the memory-copy overhead on the USB-driver side of the packet-stream interface by using the packet-stream buffer directly as DMA buffer. In order to do this, the buffer had to be mapped as uncached memory. Even though we managed to change the driver code to fetch the payload directly from the packet stream and thereby avoiding a memcpy operation, we observed a downgrade in performance. Apparently, cached memcpy (copy from the packet-stream buffer to the DMA buffer) is faster than imposing uncached memory accesses on both sides L4Linux and the USB driver. Therefore, this optimization turned out to be a dead end.
The second line of work was the optimization of memcpy. We replaced the generic byte-wise memcpy with a variant that takes several stages of alignments into account:
-
Unaligned blocks are copied with the generic (slow) memcpy.
-
For alignments of 4 and 8 bytes, we use the standard Linux memcpy implementation.
-
For alignments of 32 bytes, we use a custom ARM-specific copy operation facilitating the ldmia and stmia instructions.
Thanks to the optimization of the memcpy implementation, we were able to gain another 1 MiB/sec.
Batching outgoing packets
So far, our optimization were focused on removing overheads caused by the microkernel approach. However, we also found opportunities for optimization that go beyond that. In the native Linux kernel, NIC drivers are not able to leverage the batching of packet transmissions because of the design of the kernel API. Each packet is passed to the hardware individually. In contrast, L4Linux uses Genode's packet-stream facility to pass networking packets from the TCP/IP stack to the driver. So the driver has information about more than one packet pending for transmission. This information principally enables the USB driver to use a hardware mechanisms for submitting multiple networking packets at once, thereby reducing the driver overhead.
TCP parametrization
Thanks to our optimizations, we found that UDP performance reached the level of native Linux. However, the TCP performance was still lacking and prompted us to further investigate. We found that the cause of the TCP performance loss to be a configuration issue of the Linux TCP/IP stack. The Linux kernel has built-in heuristics for dimensioning TCP parameters depending on the available memory. Because we had assigned only very little memory to L4Linux, those heuristics resulted in extremely small TCP windows sizes (e.g., TCP retransmission buffer). The native Linux variant used much larger values. Because of the small buffers, the L4Linux kernel had to decrease the rate of TCP packets to wait for incoming acknowledgements until new packets could be generated. Now, when using the same TCP/IP configuration as native Linux, the differences between UDP and TCP performance were almost gone. TCP reaches over 10 MiB/sec (inbound) and 11 MiB (outbound).
Resulting network performance
The optimization steps described in the previous section resulted in the measured throughput of 11 MiB/sec (transmission) and 8.8 MiB/sec (reception) when using network packets of 1024 bytes. Our analysis and optimizations suggest that the throughput is largely dependent on the packet size because protocol costs are caused per packet rather than by the amount of payload.
|
|
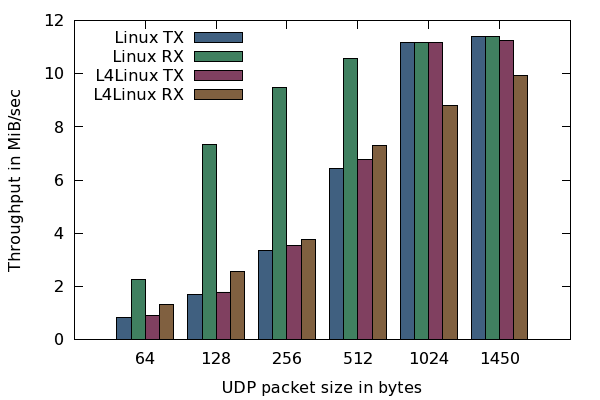
Comparison of UDP throughput between Linux and L4Linux. The values are in MiB/sec depending on the UDP packet size.
|
This assertion is supported by our experiment to use packets of 1450 bytes (MTU size) instead of 1024 bytes. By using MTU-sized packets, L4Linux reaches a transmission throughput of more than 11 MiB/sec, which is far better than our goal. We found that the throughput is largely bound by the number of packets. Image 5 supports this observation. For large packets, L4Linux reaches almost native performance but native Linux scales better when using small packet sizes. However, in both cases, the throughput is CPU bound. So for small packets, neither native Linux nor L4Linux are able to saturate the network interface.
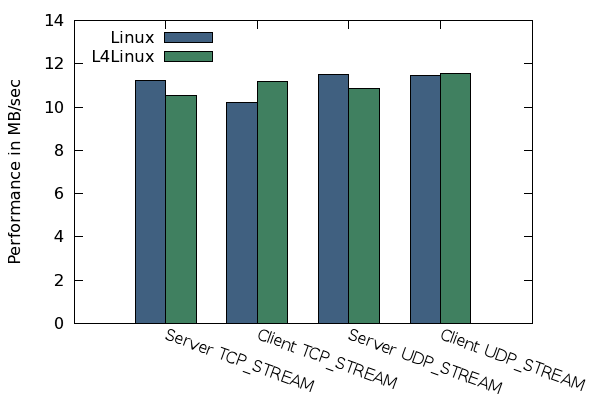
|
|
Results of the netperf benchmark
|
Figure 6 shows the results of the netperf benchmark executed on L4Linux. There are hardly any differences between the UDP and TCP performance values of native Linux compared to L4Linux.
SD card
We developed a new SD card driver for the OMAP4 platform from scratch. In line with the HDMI driver, this driver was implemented using the genuine Genode API. Similar to our work on the networking support, we were aiming to achieve a performance comparable to native Linux. The pivotal steps for reaching this goal were the operation of the SD-card in the proper mode and the use of DMA. At initialization time, the driver switches the card from the initial one-bit data mode to the faster 4-bit data mode. This change improves the bandwidth between the SD-card and the HSMMC host controller by 25% to 50% depending on the access pattern (i.e., the used block sizes). For the transfer of the actual payload data, we use the master DMA feature of the OMAP4 HSMMC card controller. This is in contrast to Linux, which uses the slave DMA option. By facilitating the use of DMA and interrupts, we slightly improved the raw driver performance and, more importantly, significantly lowered the CPU utilization caused by the driver. This pays off when complex workloads such as L4Linux are running concurrently with the driver.

|
SD-card performance in numbers
We measured both the raw driver performance as well as the performance of the driver when used as block device in L4Linux.
- Performance of the raw SD-card driver
The benchmark used for measuring the raw driver performance is located at the os/src/drivers/sd_card/omap4/bench directory. It is accompanied with the os/run/sd_card_bench.run script for running the benchmark on the Pandaboard. The driver supports both PIO and DMA. The use of DMA or PIO is defined in the main function of the benchmark via the use_dma constant. The program reads and writes the first 10 MiB of the SD card using different block sizes.
|
|
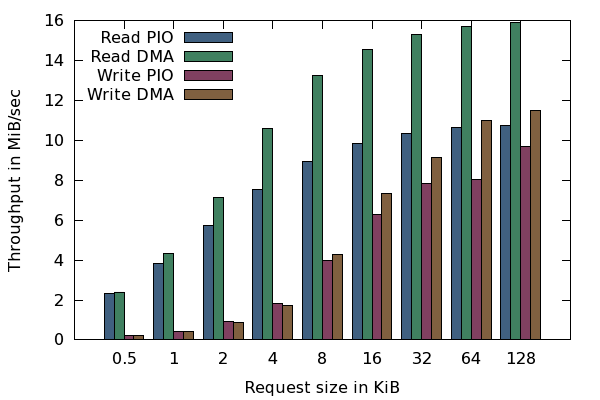
Raw I/O throughput of the SD-card driver. Values are given in MiB/sec.
|
Figure 8 shows the raw I/O throughput of the SD-card driver for both PIO and DMA mode of operations. The benchmark code is co-located with the driver code in the same process.
For small block sizes, both DMA and PIO modes show a similar performance. The performance is dominated by the setup costs of SD card commands. For large block sizes, the use of DMA is clearly beneficial. The main benefit of using DMA, however, is not captured by the numbers of the raw driver benchmark. It is the vastly reduced CPU load, which enables concurrently running components such as L4Linux to continue execution while an SD-card operation is in progress.
Performance of the SD-card driver used with L4Linux
As performance baseline, we again determined the SD-card performance of the Linux kernel. The throughput was measured using the dd command. To eliminate the effect of the Linux block cache and block-merging strategies, the direct flag was specified as argument of dd.
For measuring the L4Linux setup, we used the ports-foc/run/linux_panda.run script. Because the Busybox version of dd does not support the direct flag, we compiled dd from source (coreutils-8.9) using the CodeSourcery tool chain and added the binary to the initrd image.
|
|
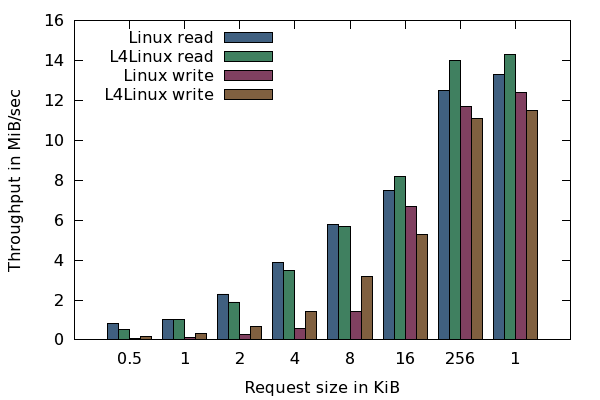
I/O throughput native Linux compared with L4Linux. Values are given in MiB/sec.
|
Figure 9 shows the comparison between native Linux and L4Linux using our SD-card driver that is executed in a separate address space. Overall, the L4Linux scenario shows nearly the same performance as the native Linux scenario. There are noteworthy exceptions though.
For reading small blocks of 512 bytes, L4Linux achieves only about 60% of the native performance. However, for block sizes of 1 KiB or higher, the L4Linux matches the native performance. For large blocks, L4Linux is 7% faster than native Linux.
The write throughput shows very different characteristics. Here L4Linux shines when handling small blocks. For block sizes of 8K or smaller, L4Linux is about double as fast as native Linux. In contrast, for very large block sizes, native Linux becomes 12% faster. We attribute the latter effect to the size of Genode's packet-stream buffer that is used to transfer payload between the L4Linux kernel and the SD card driver. The buffer is dimensioned to 128 KiB. If L4Linux receives large block requests, it divides the requests into smaller requests that fit into the packet-stream buffer. Another interesting anomaly is the significant performance drop of write throughput of both Linux and L4Linux when blocks become smaller than 16 KiB. Such a drastic change is not visible in the raw driver benchmark. Consequently, we attribute this effect to the behaviour of the Linux kernel.
Scalability of L4Linux using SMP
The Pandaboard features two CPU cores. The original version of Genode on the Pandaboard only used one core though. In order to enable the use of both CPU cores by L4Linux, we took the following steps:
L4Linux uses Fiasco.OC's virtual CPUs (vCPU) to mimic the interaction of the kernel with underlying physical CPU(s). A vCPU is a user-level thread that can be intercepted by asynchronous events (virtual interrupts). If intercepted, the normal control flow gets stopped and an exception handler takes control. On return of the exception handler, the normal control flow continues. Any number of vCPUs can be instantiated on a single physical CPU. As the first step towards enabling L4Linux to use multiple physical CPUs, we had to enable the use of multiple vCPUs. In contrast to the uni-processor variant, SMP Linux uses thread-local variables, for which we had to slightly modify our version of L4Linux. With this work in place, L4Linux could be booted with any number of virtual CPUs indicated by the number of Tux instances at the boot console.
As second step, we added a principal API for assigning threads (or vCPUs) to physical CPUs. The API extension consists of two RPC functions in the Genode::Cpu_session interface. The num_cpus function returns the number of CPUs available to a particular CPU session. The affinity function assigns a given thread to a specified CPU index. The interface is designed such that the CPU set used by a CPU session is virtualizable in the future. However, currently, the CPUs exposed by each CPU session correspond to the physical CPUs.
The third step was enabling SMP support in Fiasco.OC. Apparently, SMP support on OMAP4 on Fiasco.OC rev 38 is not a well-tested code path. We had to manually fix several compile problems. However, we eventually got Fiasco.OC to successfully boot with SMP enabled and managed to assign threads to physical CPUs using Cpu_session::affinity. With these pieces in place, we were able to assign vCPUs of L4Linux to different physical CPUs. We validated the assignment using the Fiasco.OC kernel debugger by inspecting the information presented by the "list present" (lp) command.
Unfortunately, we observed unbearable high latencies of synchronous RPC between thread of different CPUs. For example, let's consider the case where a vCPU in the L4Linux kernel that runs on CPU 1 tries to call Genode's framebuffer driver (running on CPU 0) to refresh a certain area on screen. In this case, the RPC crosses CPU boundaries. Even though the framebuffer's refresh function is actually empty (as a physical framebuffer driver doesn't need to copy pixels around). A single refresh call takes several milliseconds. One possible explanation for this issue is that IPIs (inter-processor interrupts) were not working at all for Fiasco.OC rev 38 on SMP OMAP4. After the refresh call, CPU 0 would usually schedule the idle thread and sleep until the occurrence of the next timer interrupt, which will not happen before the end of the current time slice of 10 ms. In the occurrence of the timer interrupt, the next RPC (from CPU 1) will be processed. Obviously, this latency renders cross-CPU-communication almost unusable.
As a blessing in disguise, a new version of the Fiasco.OC kernel was just released when we discovered the IPI issue. We reasoned that the IPI issue may have been addressed by the Fiasco.OC developers in the course of the past 12 months (the time between both kernel releases). Therefore, we upgraded Genode to Fiasco.OC rev 40. To our delight, the IPI issue disappeared with the new kernel. With the new kernel, L4Linux can be used on Pandaboard with SMP enabled.
Conclusion
Through the work described in this article, we have enriched Genode with profound platform support for the popular Pandaboard. The driver support covers SD-card, USB HID, networking, and HDMI. We have put much emphasis not only on principally enabling those devices but on optimizing the system for good performance. Thanks to these elaborative efforts, we managed to achieve networking and block-device throughput that is roughly on par with the throughput achieved by native Linux, with both systems operating at a similar level of CPU utilization.
The results are strong indicators that microkernel-based systems are not inherently suffering overly large performance penalties. The decomposition of functionality into multiple protection domains is just one source of potential overheads among many. We found that using the right caching attributes, picking suitable allocation strategies, optimizing memory-copy performance, and batching I/O operations have a far greater impact onto the application performance than the costs added by carefully designed inter-process communication. With carefully designed, we mean the use of the right mechanisms for a given problem and the determination of practical trade-offs. For example, by loosely coupling components via shared memory and asynchronous notifications, high throughput can be achieved for bulk traffic on the costs of high latencies caused by buffering data. In contrast, if low latency is desired, the use of synchronous RPC might be more appropriate. Designing a good performing microkernel-based system comes down to taking sensible choices in designing those interfaces. This is a burden that developers of monolithic kernels do not have to carry to this degree. But we are greatly enjoying this challenge.
Example scenario
If we wetted your appetite to try out Genode on the Pandaboard, there is a ready-to-use example scenario that illustrates how the different pieces described described above fit together. It shows off the following features:
-
HDMI output
-
User input via USB HID
-
Two instances of L4Linux
-
SD card access by both instances of L4Linux, each working with a different partition
-
SD card access by a native Genode program
-
A simple HTTP server implemented as native Genode program
-
Both Linux instances accessing the network
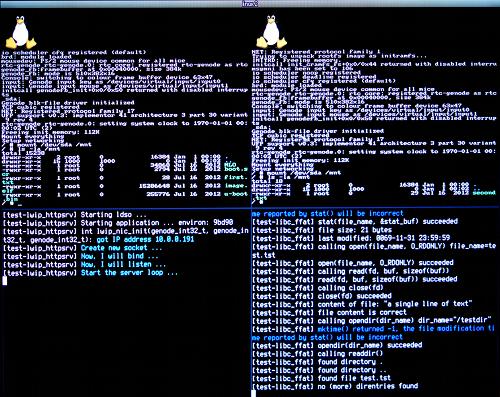
|
The scenario is available as both pre-compiled image and run script. The image can be downloaded here:
https://github.com/downloads/nfeske/genode/two_linux_panda.img.gz
After downloading the image, unpack the image and copy it onto your SD card:
gzip -d two_linux_panda.img.gz sudo dd if=two_linux_panda.img of=/dev/your_sd_card bs=1M
Alternatively, you might use zcat to avoid the intermediate creation of a big file:
sudo sh -c "zcat two_linux_panda.img.gz > /dev/your_sd_card"
The image was produced by formatting an SD card into three partitions. The output of fdisk -ul looks as follows:
Disk /dev/sdb: 8011 MB, 8011120640 bytes 247 heads, 62 sectors/track, 1021 cylinders, total 15646720 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x23e270f3 Device Boot Start End Blocks Id System /dev/sdb1 * 62 76569 38254 c W95 FAT32 (LBA) /dev/sdb2 76570 122511 22971 c W95 FAT32 (LBA) /dev/sdb3 122512 168453 22971 c W95 FAT32 (LBA)
The first partition contains the files of the u-boot boot loader and the image.elf file produced by the run script ports-foc/run/two_linux_panda.run. Each partition contains a file called first.txt, second.txt, and third.txt respectively. This way, the different partitions can be easily distinguished while running the demo scenario.
Please make sure to have the Pandaboard connected to a network with a DHCP server running. When booting the compound scenario, you might do the following experiments:
HTTP server
On the lower left screen area, you can see the output of a simple HTTP server running as native Genode program. At startup, it acquires an IP address via DHCP and prints the address. For example,
got IP address 10.0.0.191
You can use a web browser on your host machine to access this HTTP server by using the IP printed by ifconfig as URL. You will be greeted by a message from the Pandaboard. The text output of the HTTP server will respond to each request.
SD card access by native Genode program
In the lower right screen area, you can see the output of a simple ffat test program, which uses the libc_ffat plugin to access the third partition of the SD card. The text executes the following operations:
-
mkdir
-
chdir
-
write pattern to a file using open, write, close
-
query file status of new file using stat
-
read and verify file content using open, read, close
-
print directory entries
The steps will be repeatedly executed 10 times, with a delay of two seconds in between the test runs.
SD card access by L4Linux instances
Each of both L4Linux instances that are displayed in the upper screen area is wired to a different partition of the SD card. The left instance can access the first partition (the one containing the boot loader) whereas the right instance can access the second partition. For each instance, the partition is known as /dev/sda. To mount the partitions, issue the following command into each of both instances and inspect the content:
mount /dev/sda /mnt ls -la /mnt
You may cat the content of the first.txt and second.txt files. Furthermore, you might write to the partition. E.g., by copying /bin/ls to /mnt and then executing /mnt/ls.
Accessing the network from within L4Linux
Each L4Linux instance has acquired a different IP address using DHCP. To see the assigned IP addresses, issue
ifconfig
You can use these IP addresses to ping both Linux instances one another. You may also use your host machine to ping either of both instances.
To download a file from the internet, you may try out wget. For example:
wget http://genode.org cat index.html